| R语言可视化【ggplot2】 | 您所在的位置:网站首页 › origin怎么画三维散点图 › R语言可视化【ggplot2】 |
R语言可视化【ggplot2】
|
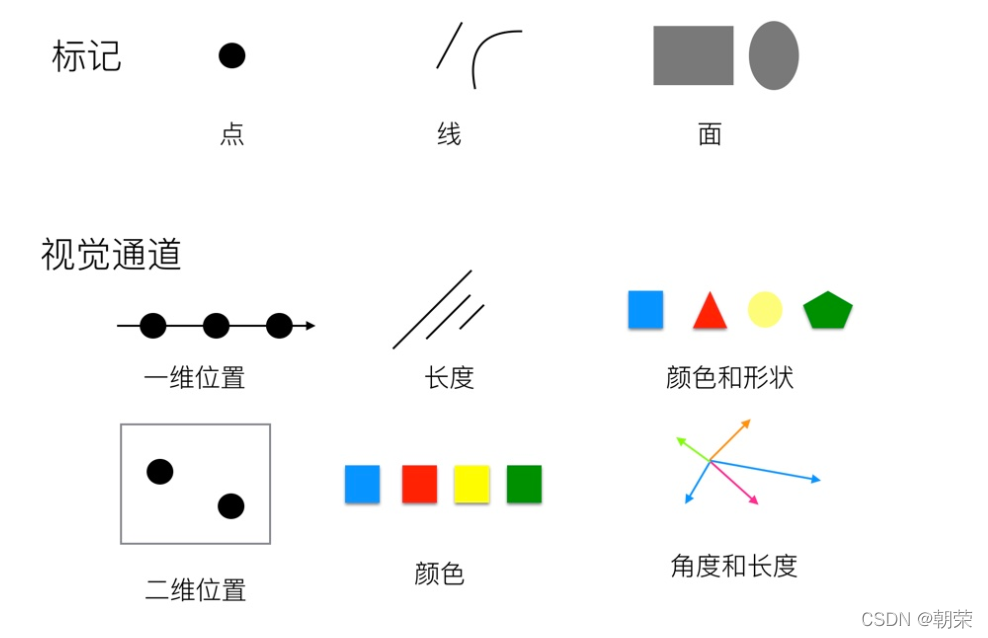
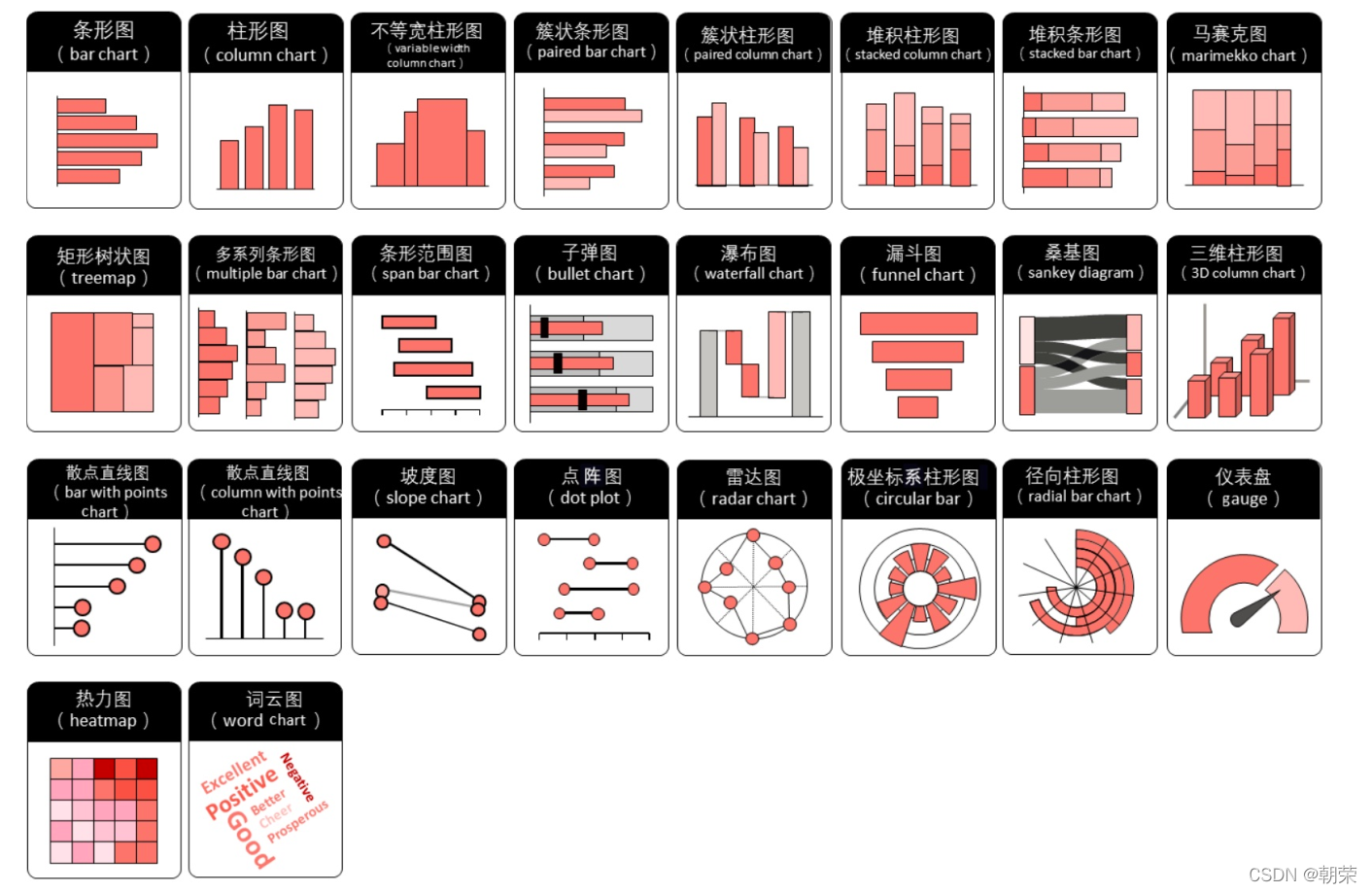
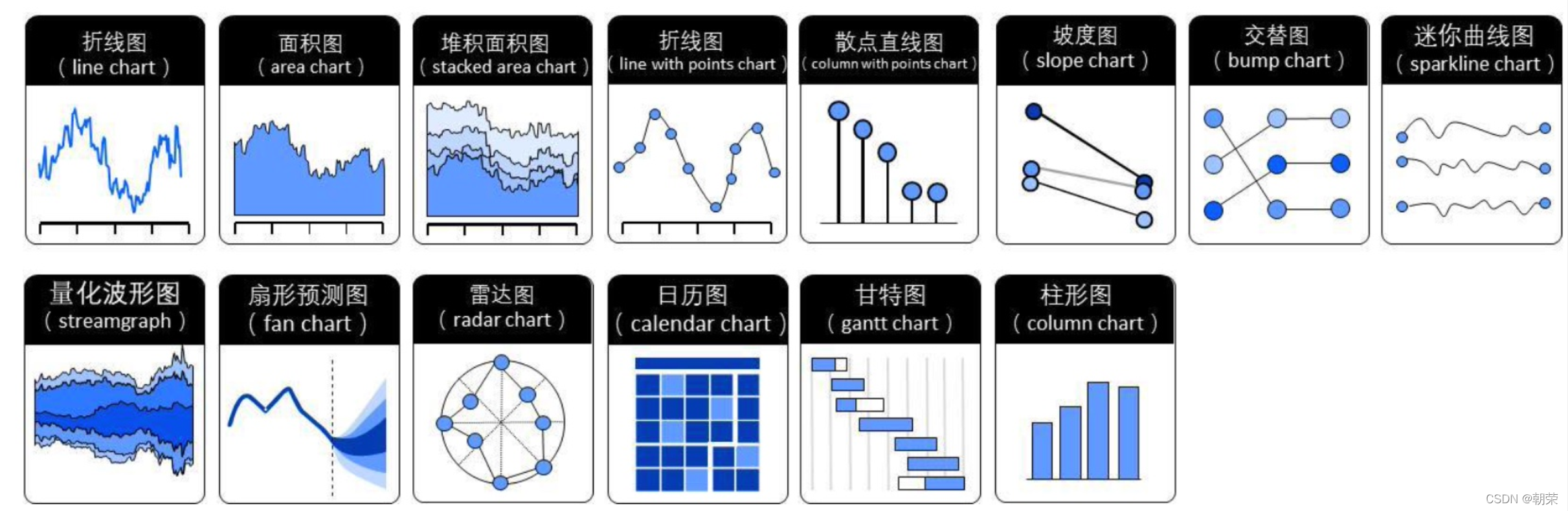
R语言可视化【ggplot2】 文章的文字/图片/代码部分/全部来源网络或学术论文或课件,文章会持续修缮更新,仅供学习使用。 目录 R语言可视化【ggplot2】 一、可视化介绍 二、不同情况适用的图形 类别比较: 数值关系: 数据分布: 时间序列: 局部与整体: 举几个例子: 类别比较:柱形图 类别比较:条形图 类别比较:克利夫兰点图 类别比较:南丁格尔玫瑰图 数值关系:散点图 数值关系:气泡图 数值关系:三维散点/气泡图 数值关系:瀑布图 数值关系:峰峦图 数值关系:相关系数图 数值关系:韦恩图 数据分布:直方图 数据分布:核密度估计图 局部整体:直方图/密度图 数据分布:散点分布图 数据分布:柱形分布图 数据分布:箱形图 数据分布:小提琴图、雨云图 数据分布:显著性标签的箱形图 时间序列:折线图/面积图 时间序列:堆积面积图 局部整体:饼图 局部整体:圆环图 高维数据:降维 高维数据:分面图 高维数据:矩阵散点图 高维数据:热力图 高维数据:平行坐标系图 高维数据:图标法-花瓣图 层次关系:树形图 层次关系:矩形树状图 层次关系: Voronoi 树图 网络关系:和弦图 网络关系:桑基图 网络关系:节点链接图 网络关系:节点链接图 地理空间 小结 三、ggplot2(Grammar of Graphics) ggplot2的图层: ggplot2 图形语法特点: ggplot2 基本绘图语法: 一、可视化介绍可视化:可视化将数据以一定的变换和视觉编码原则映射为可视化视图。用户对可视化的感知和理解通过人的视觉通道完成。 可视化编码:可视化编码 (visual encoding) 是可视化的核心内容,是将数据信息映射成可视化元素的技术,其通常具有表达直观、易于理解和记忆等特性。 可视编码由两部分组成: 标记和视觉通道。标记:代表数据属性的分类,通常是一些几何图形元素,例如:点、线、面、体。视觉通道:表示人眼所能看到的各种元素的属性,包括大小、形状、颜色等,往往用来展示属性的定量信息。
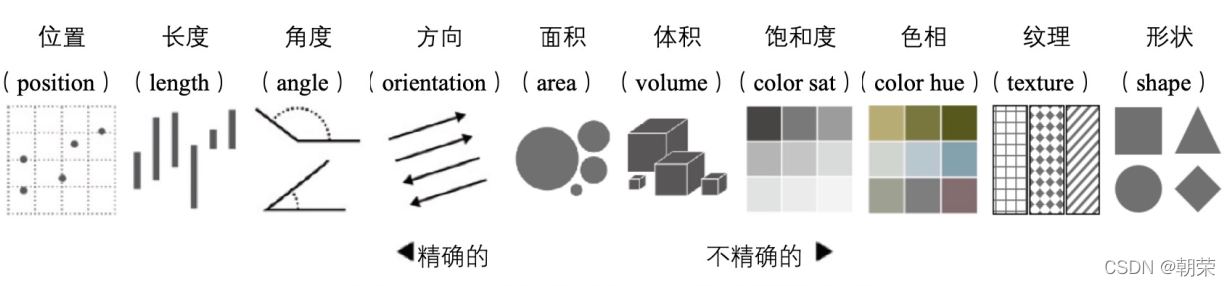
视觉通道有:位置、长度、角度、方向、面积、体积、饱和度、色相、纹理、形状。 色彩空间: RGB 色彩空间:采用笛卡尔坐标系定义颜色,三个轴分别对应红色 (R)、绿色 (G) 和蓝色 (B) 三个分量。 RGB 色彩空间是迄今为止使用最广泛的色彩空间,几乎所有的电子显示设备都使用 RGB色彩空间。CMYK 色彩空间:青色 (Cyan)、品红色 (Magenta)、黄色 (Yellow)和黑色 (Black)。通常用于印刷行业中。 二、不同情况适用的图形 类别比较:
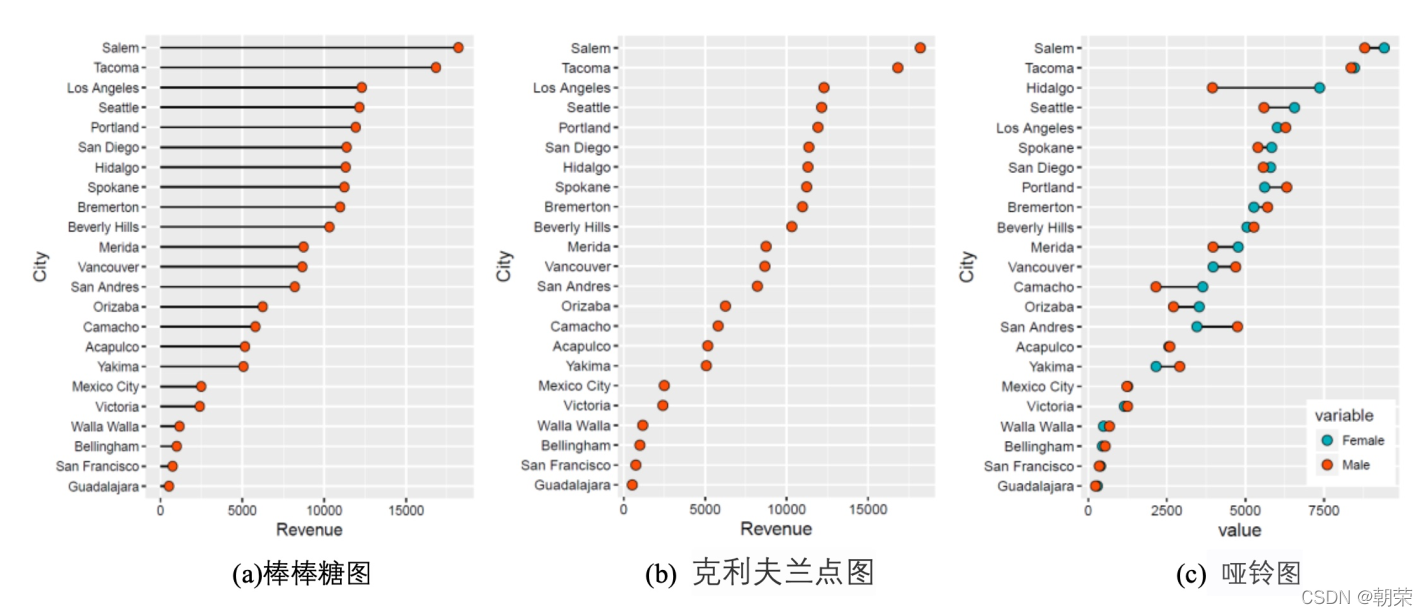
棒棒糖图 (lollipop chart):类似柱形图/条形图,只是将矩形转变成线条,减少展示空间,重点放在数据点上,看起来更加简洁美观。克利夫兰点图 (Cleveland’s dot plot):滑珠散点图,类似棒棒糖图,只是没有连接的线条,重点强调数据的排序展示及互相之间差距。哑铃图 (dumbbell plot):可以看成多数据系列的克利夫兰点图,只是使用直线连接了两个数据系列的数据点。 南丁格尔玫瑰图 (Nightingale rose chart, coxcomb chart, polar area diagram) 即极坐标柱形图,是一种圆形的柱形图,由弗罗伦斯·南丁格尔所发明。适用于 X 轴变量是环状周期型序数的情况,比如月份、星期、日期等,这些都是具有周期性的序数型数据。在数据量比较多时,使用南丁格尔玫瑰图更能节省绘图空间。
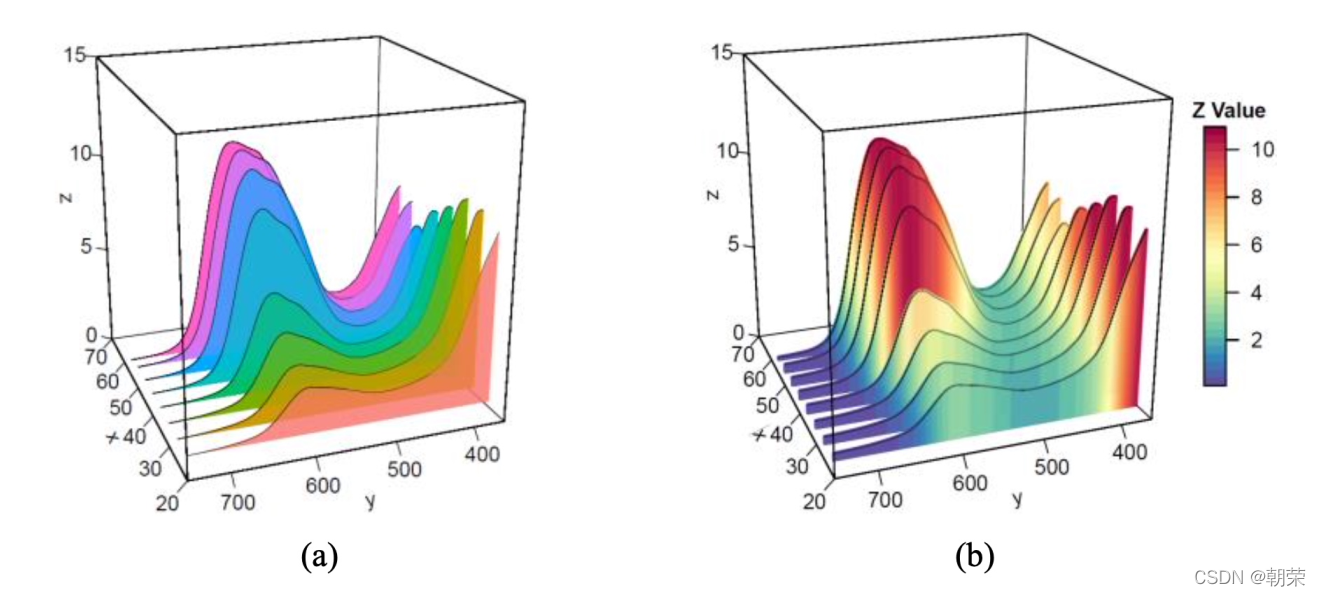
瀑布图 (waterfall plot) 用于展示拥有相同的 X 轴变量数据 (如相同的时间序列)、不同的 Y 轴离散型变量 (如不同的类别变量) 和Z 轴数值变量,可以清晰地展示不同变量之间的数据变化关系。
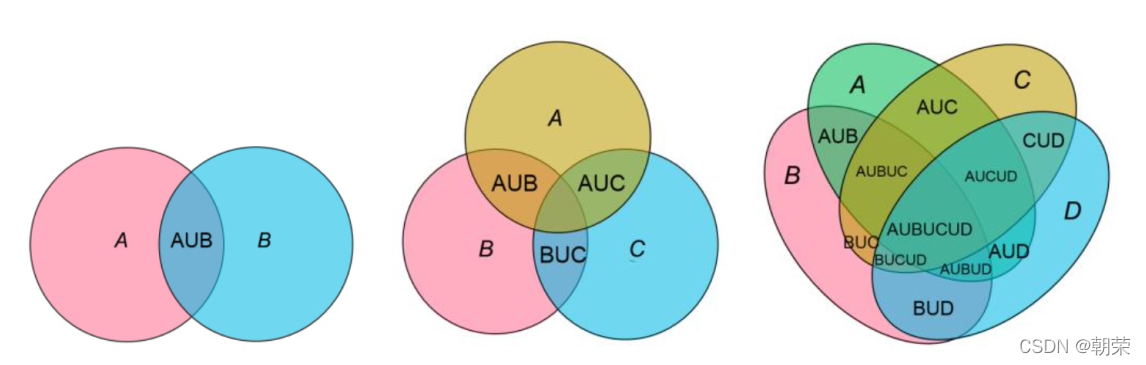
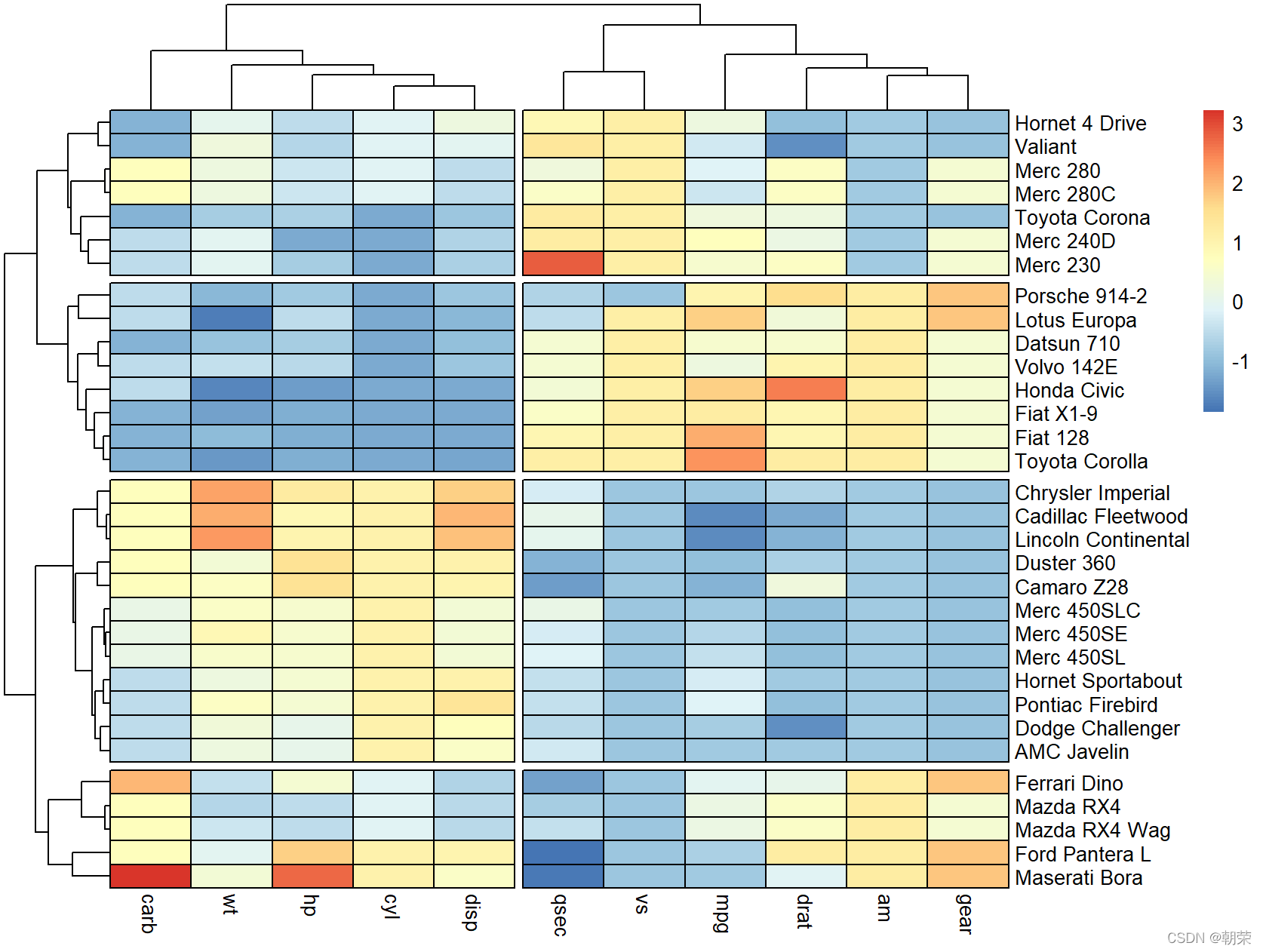
相关系数图:相关系数矩阵的可视化热力图 (heatmap) 就是将一个网格矩阵映射到指定的颜色序列上,恰当地选取颜色来展示数据。气泡图是将一个网格矩阵映射到气泡的面积和颜色上,这样使用两个视觉特征表示数据,可以让读者更加清晰地观察数据。 韦恩图 (venn diagram),用于显示元素集合重叠区域的图表。通过图形与图形之间的层叠关系,来表示集合与集合之间的相交关系。每个集合通常以一个圆圈表示。一般来说,超过 5 个集合的场景,不适合使用韦恩图。
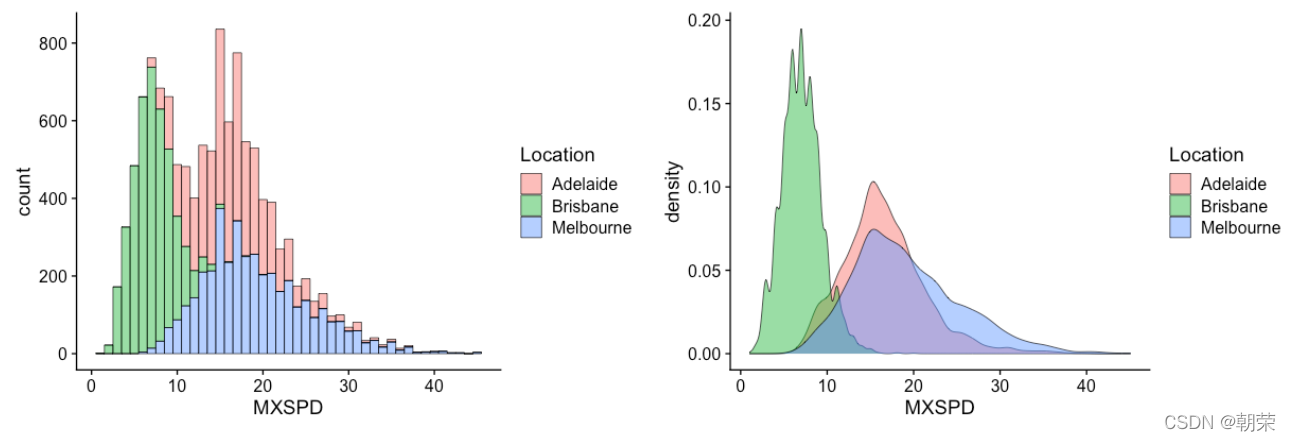
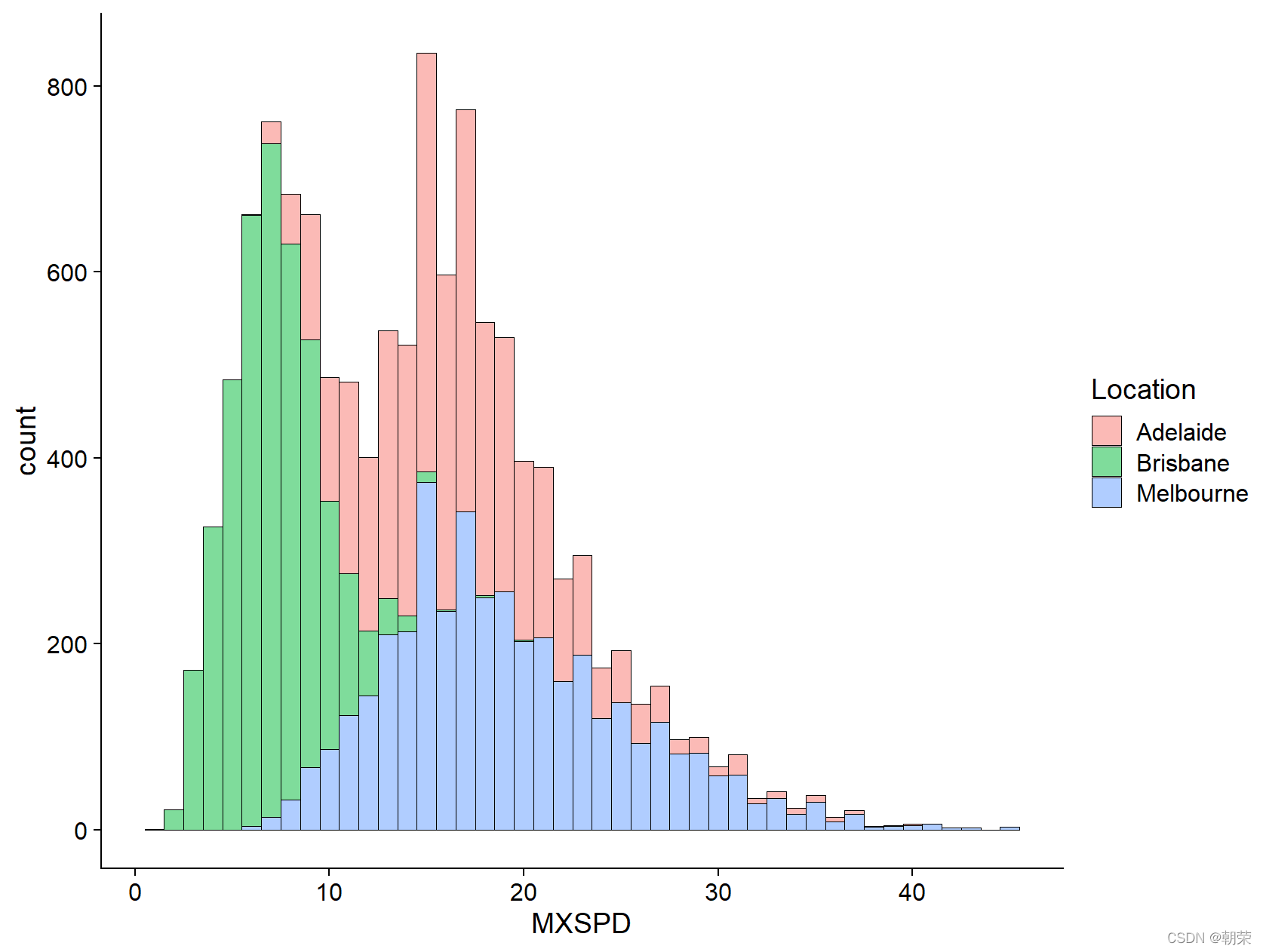
核密度估计图 (kernel density plot) 是直方图的变种,使用平滑曲线来绘制水平数值,从而得出更平滑的分布。核密度估计图比直方图优胜的地方是,它们不受所使用分组数量的影响,所以能更 好地界定分布形状。
ggplot(df, aes(x = MXSPD, fill = Location))+geom_histogram(binwidth = 1, alpha=0.5, colour="black", size=0.25) +theme_cowplot()ggplot(df, aes(x = MXSPD, fill = Location)) +geom_density(binwidth = 1, alpha=0.5, colour="black", size=0.25) +theme_cowplot()
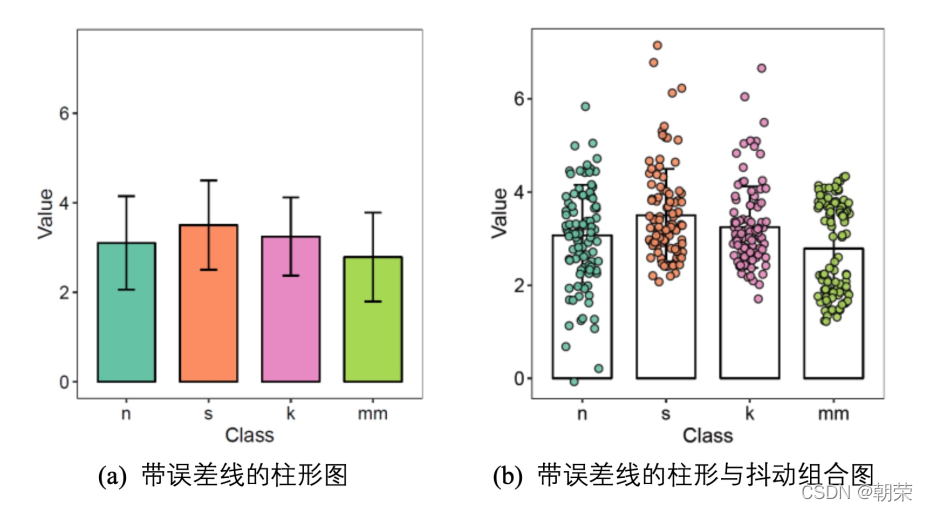
散点分布图是指使用散点图的方式展示数据的分布规律。抖动散点图 (jitter chart),每个类别数据点的 Y 轴数值保持不变,数据点 X 轴数值沿着 X 轴类别标签中心线在一定范围内随机生成,然后绘制成散点图。
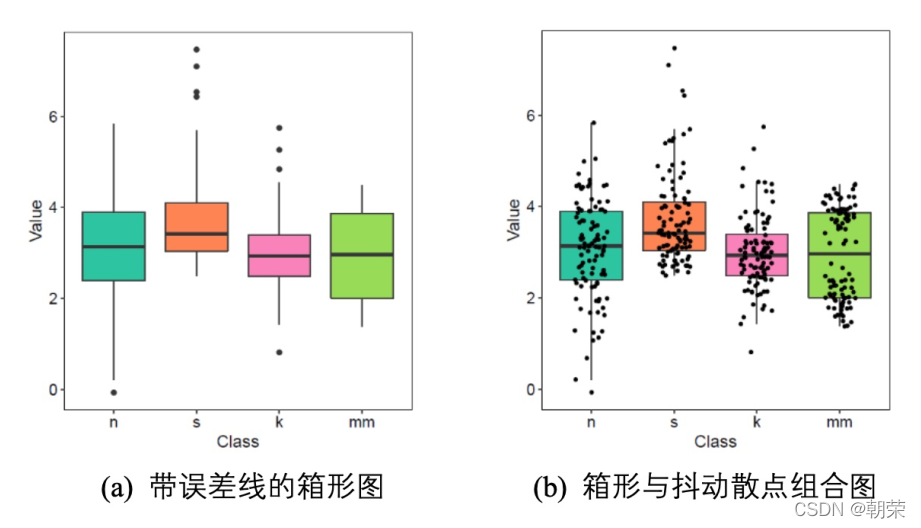
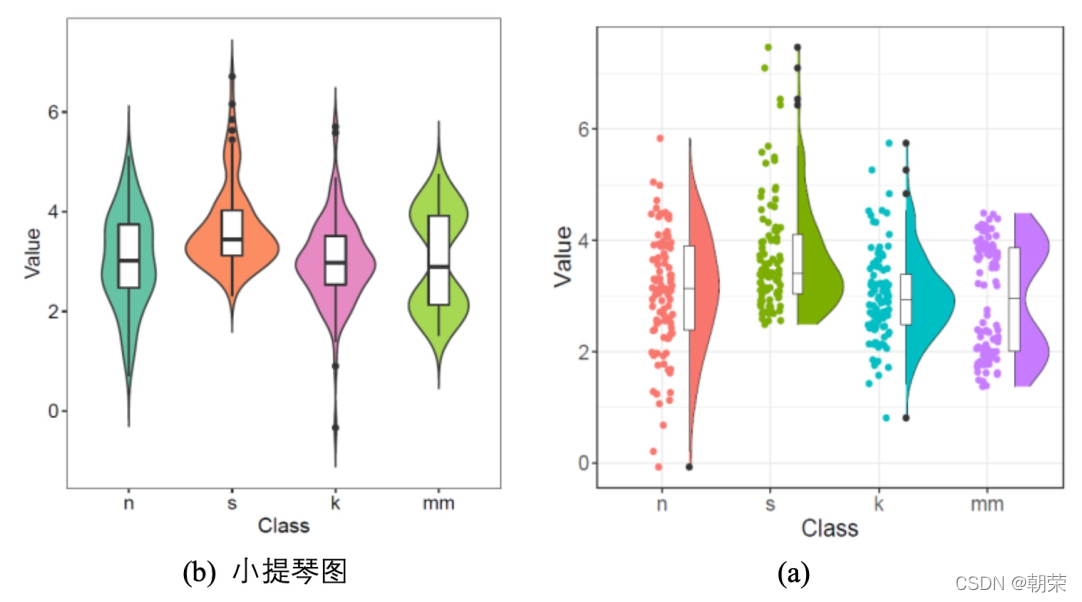
箱形图 (box plot)、箱须图 (box-whisker plot),能显示出一组数据的最大值、最小值、中位数,以及上下四分位数,可以用来反映一组或多组连续型定量数据分布的中心位置和散布范围。 小提琴图 (violin plot) 用于显示数据分布及其概率密度,结合了箱形图和密度图的特征,主要用来显示数据的分布形状。雨云图 (raincloud plot) 可以看成箱形图、密度图和抖动散点图的组合图表,清晰、完整、美观地展示了所有数据信息。
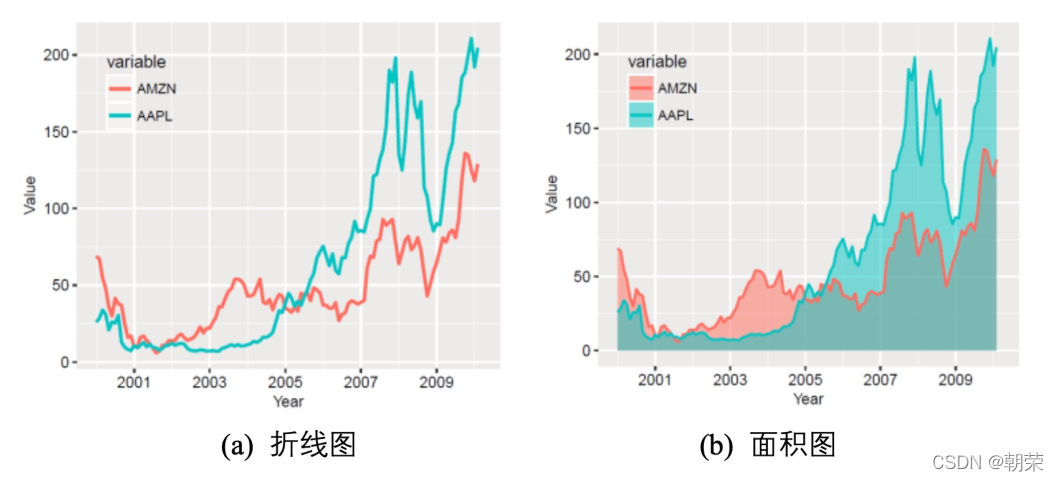
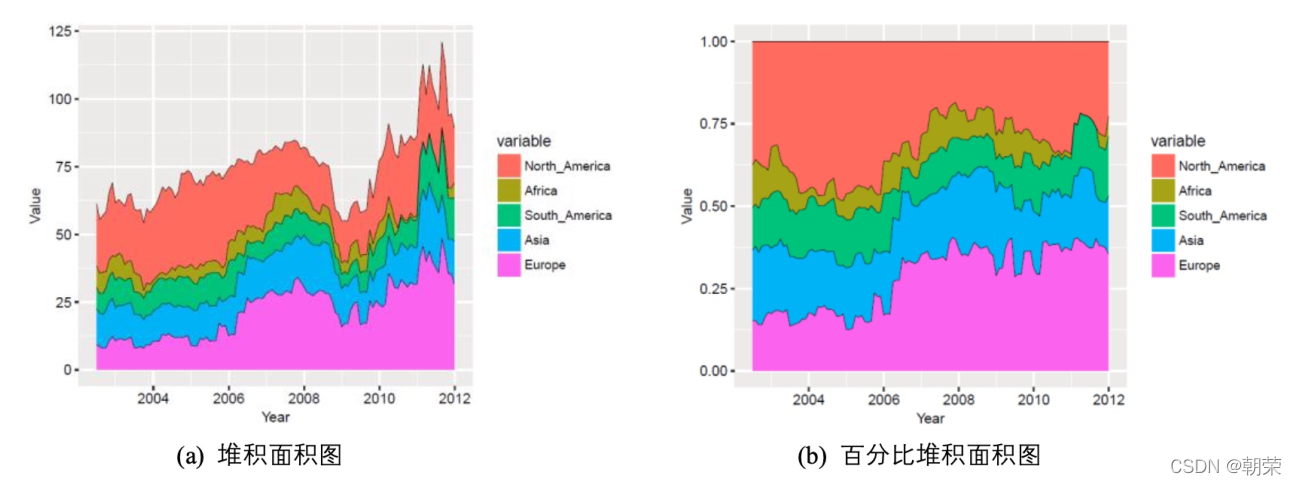
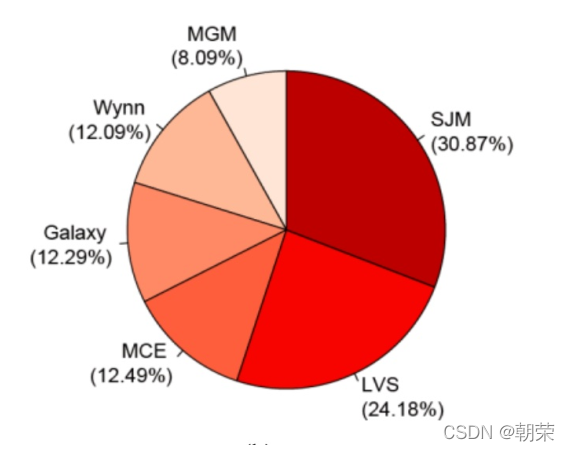
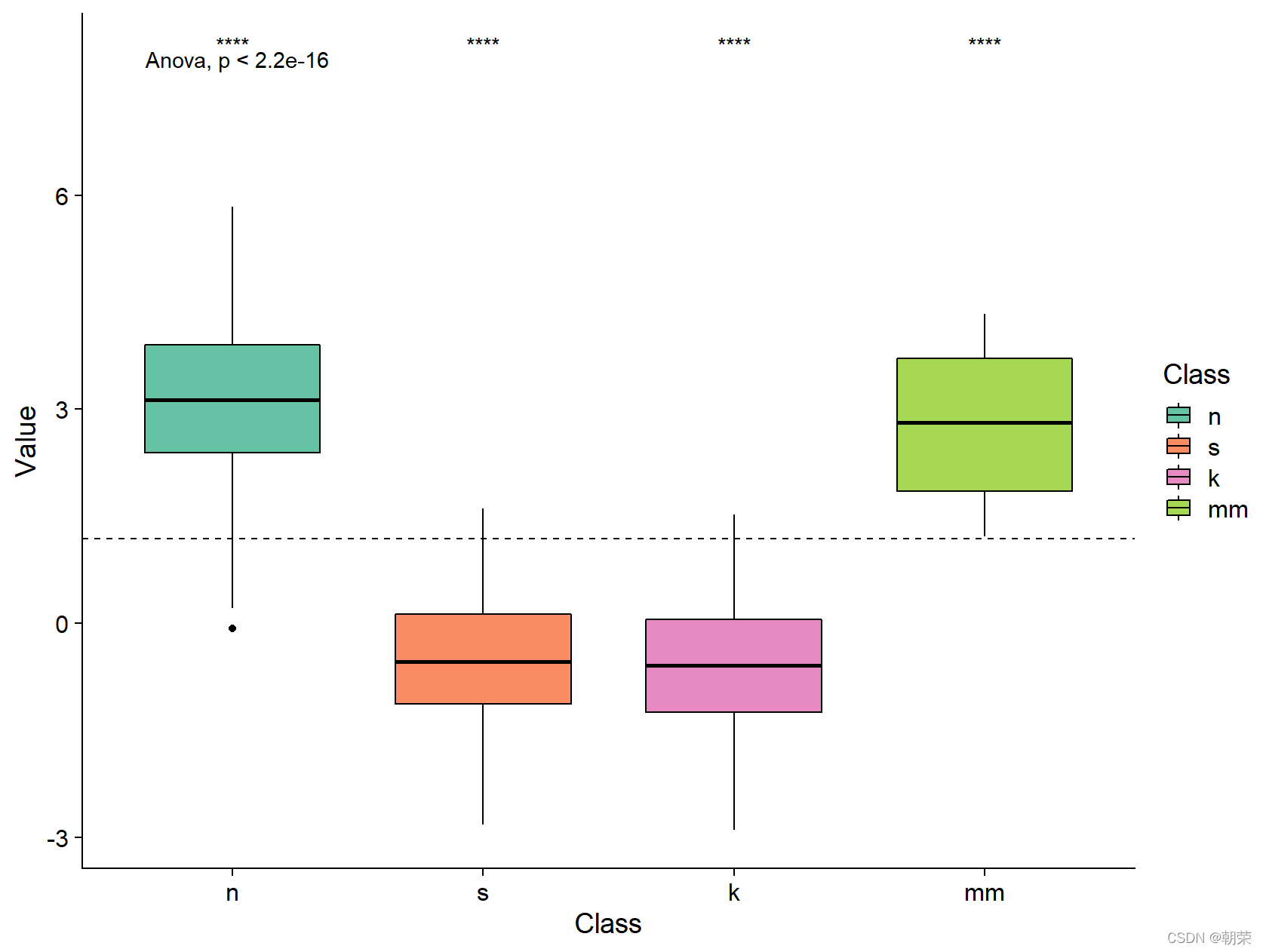
ggboxplot(mydata, x = "Class", y = "Value",fill = "Class", palette = palette,add = "none", size=0.5, add.params = list(size = 0.25)) +geom_hline(yintercept = mean(mydata$Value), linetype = 2) +stat_compare_means(method = "anova", label.x=0.8,label.y = 7.8) +stat_compare_means(label = "p.signif", method = "t.test",ref.group = ".all.", hide.ns = TRUE,label.y = 8) +theme_cowplot() ggpubr:易于绘制符合出版物要求的图表,包括显著性标签 折线图 (line chart) 用于在连续间隔或时间跨度上显示定量数值。 面积图 (area graph) 是在折线图的基础之上形成的,使用颜色或者纹理填充,这样可以更好地突出趋势信息,让图表更加美观。多数据系列的面积图如果使用得当,那么效果可以比多数据系列的折线图美观很多。注意要用透明度,系列不要超过 3 个。 堆积面积图 (stacked area graph),每一个系列的开始点是先前数据系列的结束点,在表现分量的变化情况时格外有用。百分比堆积面积图,不能反映总量的变化,但是可以清晰地反映每个数值所占百分比随时间或类别变化的趋势线。 饼图 (pie chart) 被广泛地应用于各个领域,用于表示不同分类的占比情况,通过角度大小来对比各种分类。饼图不适用于多分类的数据,原则上一张饼图不可多于 9 个分类。在绘制饼图前一定注意要把多个类别按一定的规则排序。阅读饼图就如同阅读钟表一样,人会潜意识地从而 12 点开始顺时针往下阅读内容。
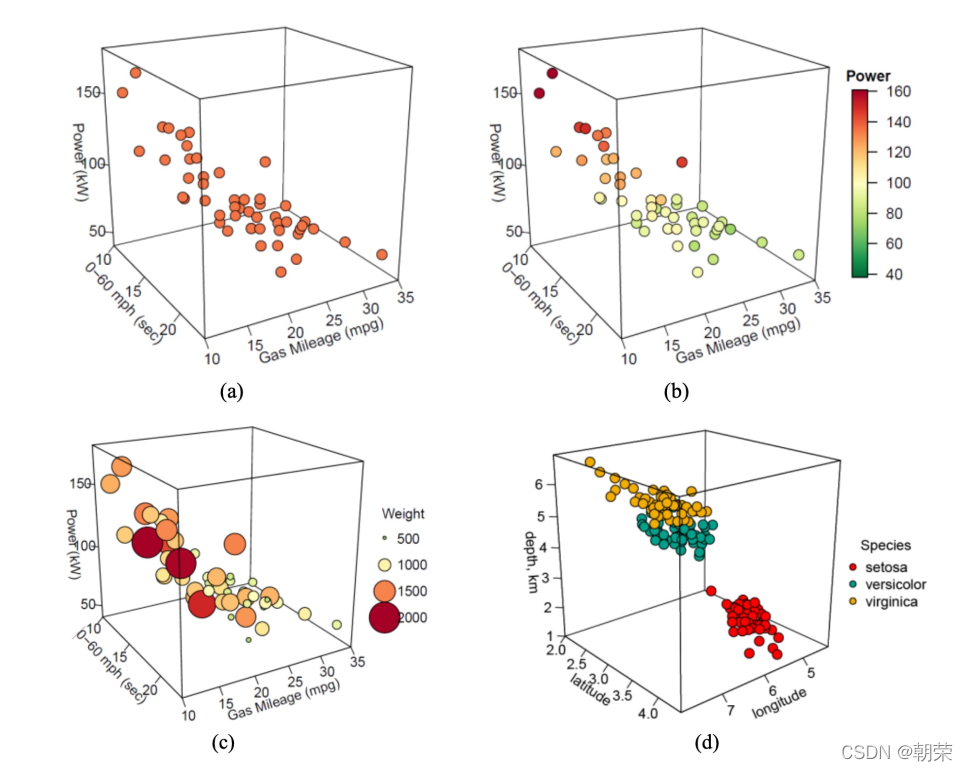
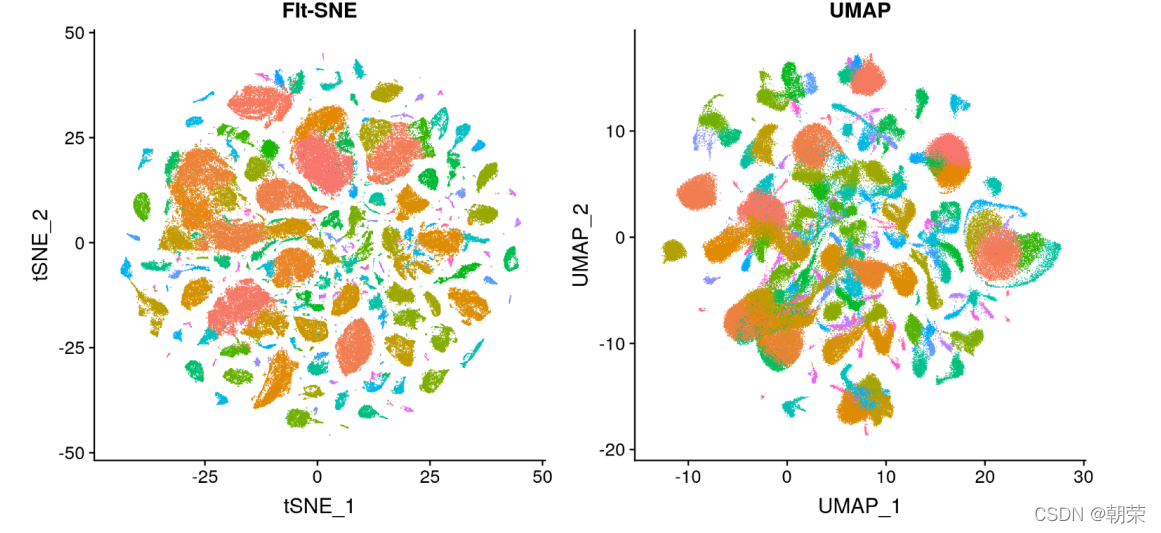
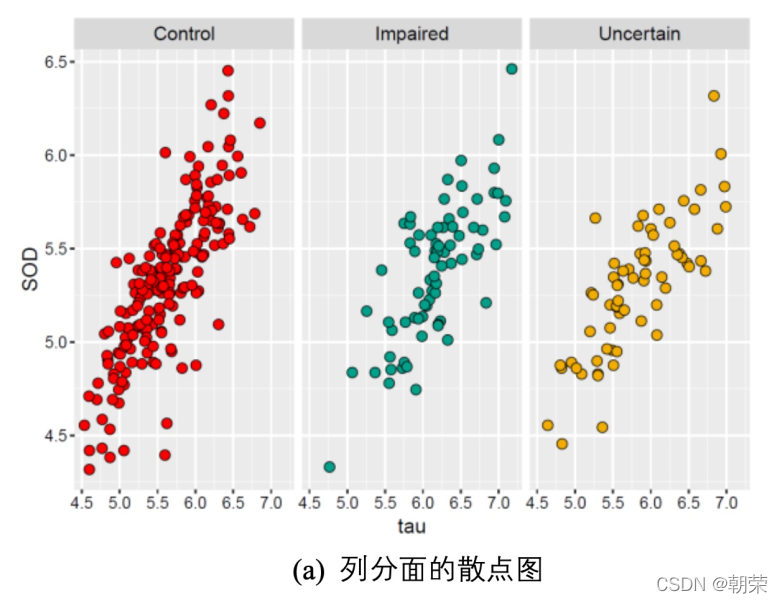
圆环图 (又叫作甜甜圈图, donut chart),其本质是将饼图的中间区域挖空。圆环图比较的不是角度是弧长。圆环图相对于饼图空间的利用率更高,可以使用空心区域显示文 本信息 (标题等)。 人眼一般能感知的空间为二维和三维。高维数据变换就是使用降维度的方法,使用线性或非线性变换把高维数据投影到低维空间,去掉冗余属性,同时尽可能地保留高维空间的重要信息和特征。 主成分分析 PCA、多维尺度分析 MDS、 t-SNE、 UMAP 分面图 (facet) 根据数据类别按行或者列,使用散点图、气泡图、柱形图或者曲线图等基础图表展示数据,揭示数据之间的关系,可以适用于三到五维的数据结构类型。 三维数据: 四维数据:
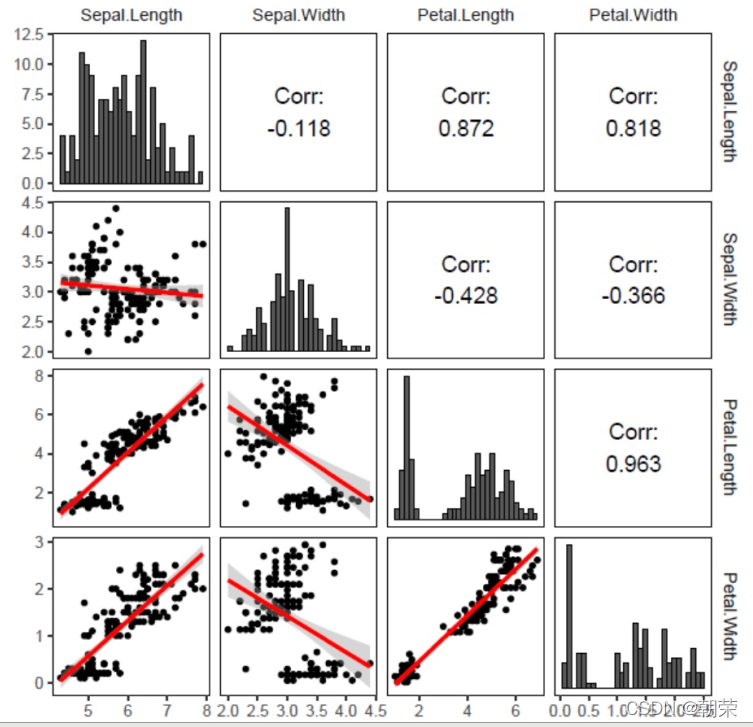
五维数据: 矩阵散点图 scatter plot matrix 是散点图的高维扩展。将高维度数据的每两个变量组成一个散点图,从而将高维度数据中所有的变量两两之间的关系展示出来。 热力图 (heat map) 是一种将规则化矩阵数据转换成颜色色调的常用的可视化方法,其中每个单元对应数据的某些属性,属性的值通过颜色映射转换为不同色调并填充规则单元。 平行坐标系图 (parallel coordinates chart) 是一种用来呈现多变量,或者高维度数据的可视化技术,用它可以很好地呈现多个变量之间的关系。 位置 2 维 + 花瓣 5 维
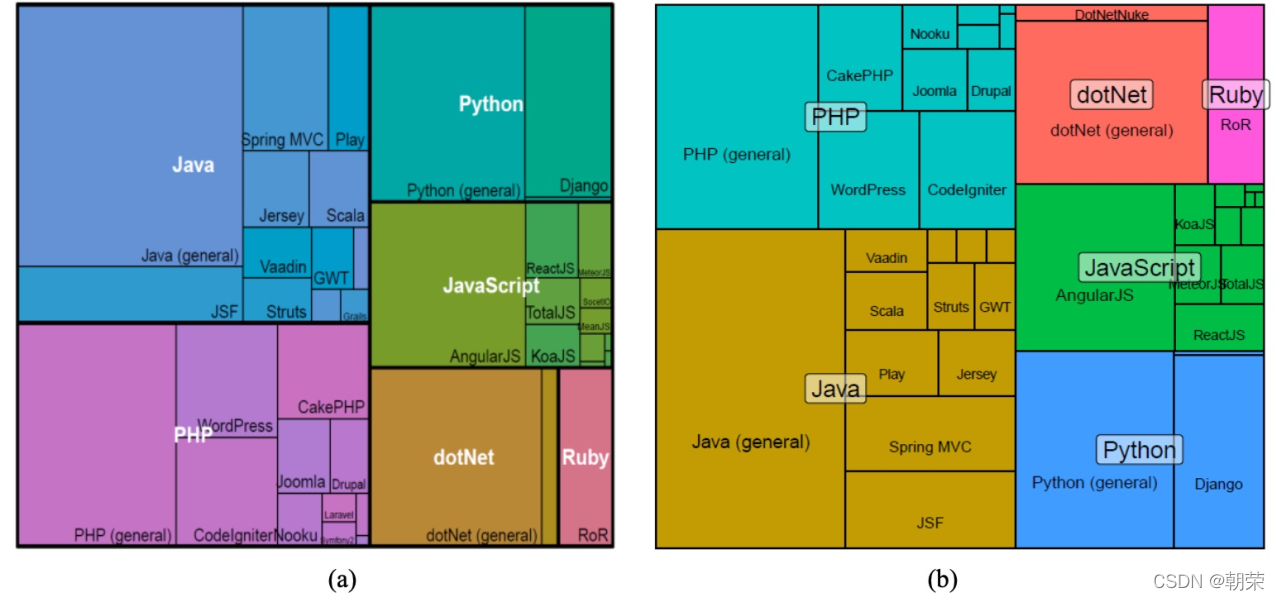
矩形树状图 (treemap):利用嵌套式矩形来显示树状结构数据,以不同颜色区块呈现不同类别,可以透过区块大小看出各类别数值大小比较。
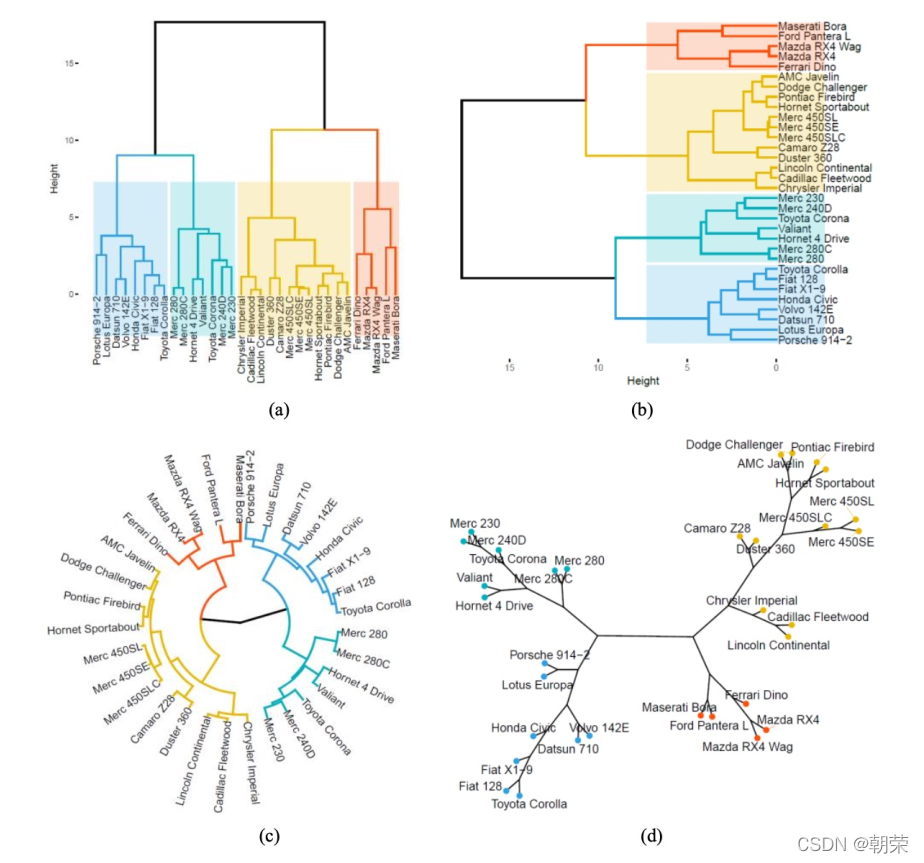
 网络关系:节点链接图 网络关系:节点链接图
地理空间  小结 小结 三、ggplot2(Grammar of Graphics) ggplot2 基于图形语法,提供了一种全新的图形创建方式。绘图过程归纳为数据 data、转换 transformation、度量 scale、坐标系 coordinate、元素 element、指引 guide、显示 display 等一系列独立的步骤。通过将这些步骤搭配组合,来实现个性化的统计绘图。ggplot2的图层: 三、ggplot2(Grammar of Graphics) ggplot2 基于图形语法,提供了一种全新的图形创建方式。绘图过程归纳为数据 data、转换 transformation、度量 scale、坐标系 coordinate、元素 element、指引 guide、显示 display 等一系列独立的步骤。通过将这些步骤搭配组合,来实现个性化的统计绘图。ggplot2的图层: Data 数据: Input data Geom 几何对象: A geometry representing data. Points, Lines etc Aesthetic 视觉通道: Visual characteristics of the geometry. Size, Color, Shape etc Scale 度量: How visual characteristics are converted to display values Statistics 统计: Statistical transformations. Counts, Means etc Coordinates 坐标: Numeric system to determine position of geometry. Cartesian, Polar etc Facets 分面: Split data into subsets
library(ggplot2)library(RColorBrewer)library(wesanderson)library(cowplot)library(reshape2)str(mpg)head(mpg)ggplot(data= mpg, mapping = aes(x=displ, y=hwy, colour=class)) + geom_point() data 为数据集,主要是数据框 (data.frame) 格式的数据集;mapping 为变量的视觉通道映射,用来表示变量 x 和 y,还可以用来控制颜色 (color)、大小 (size) 或形状 (shape) 等视觉通道。 # different vis channelsdf
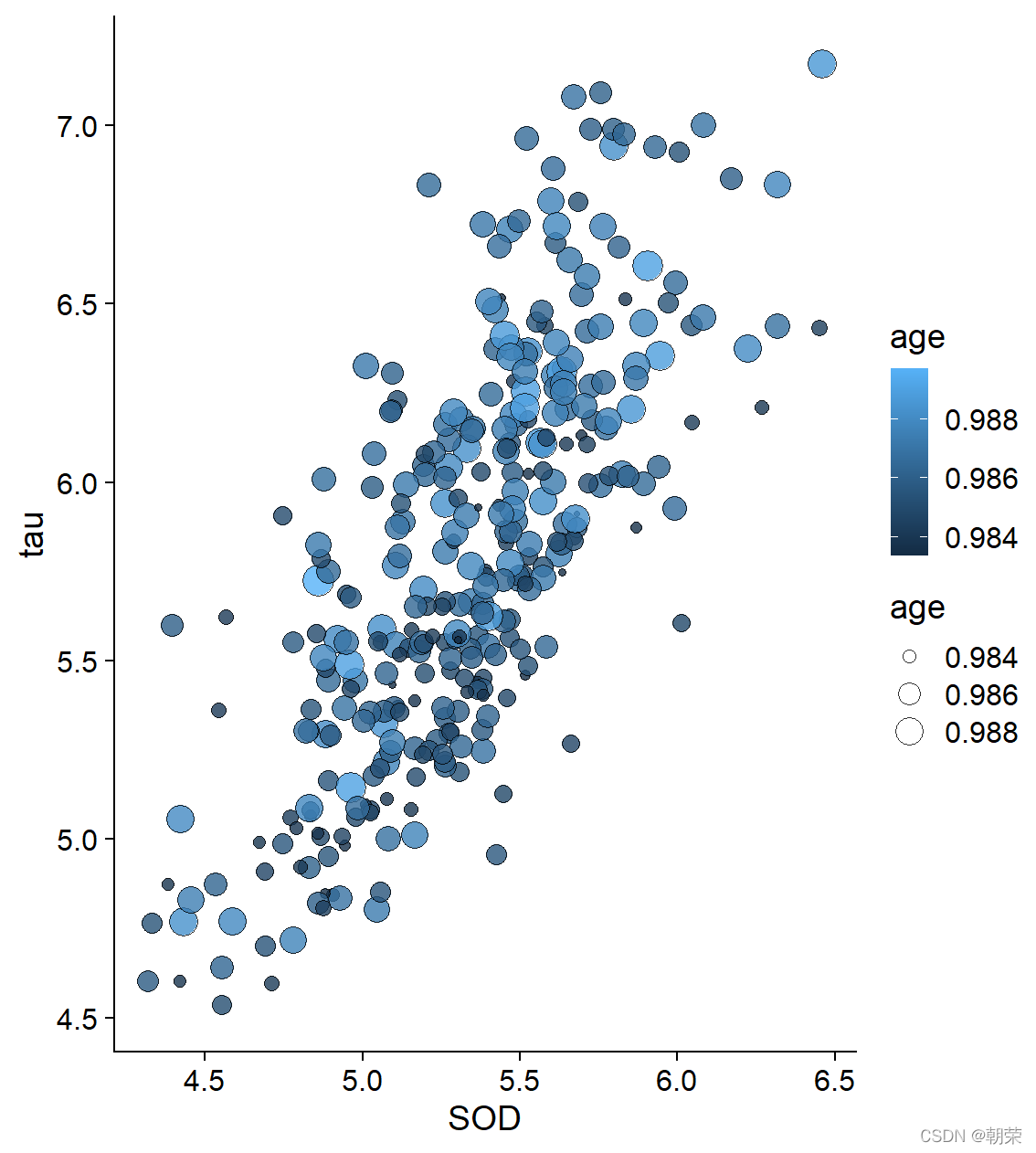
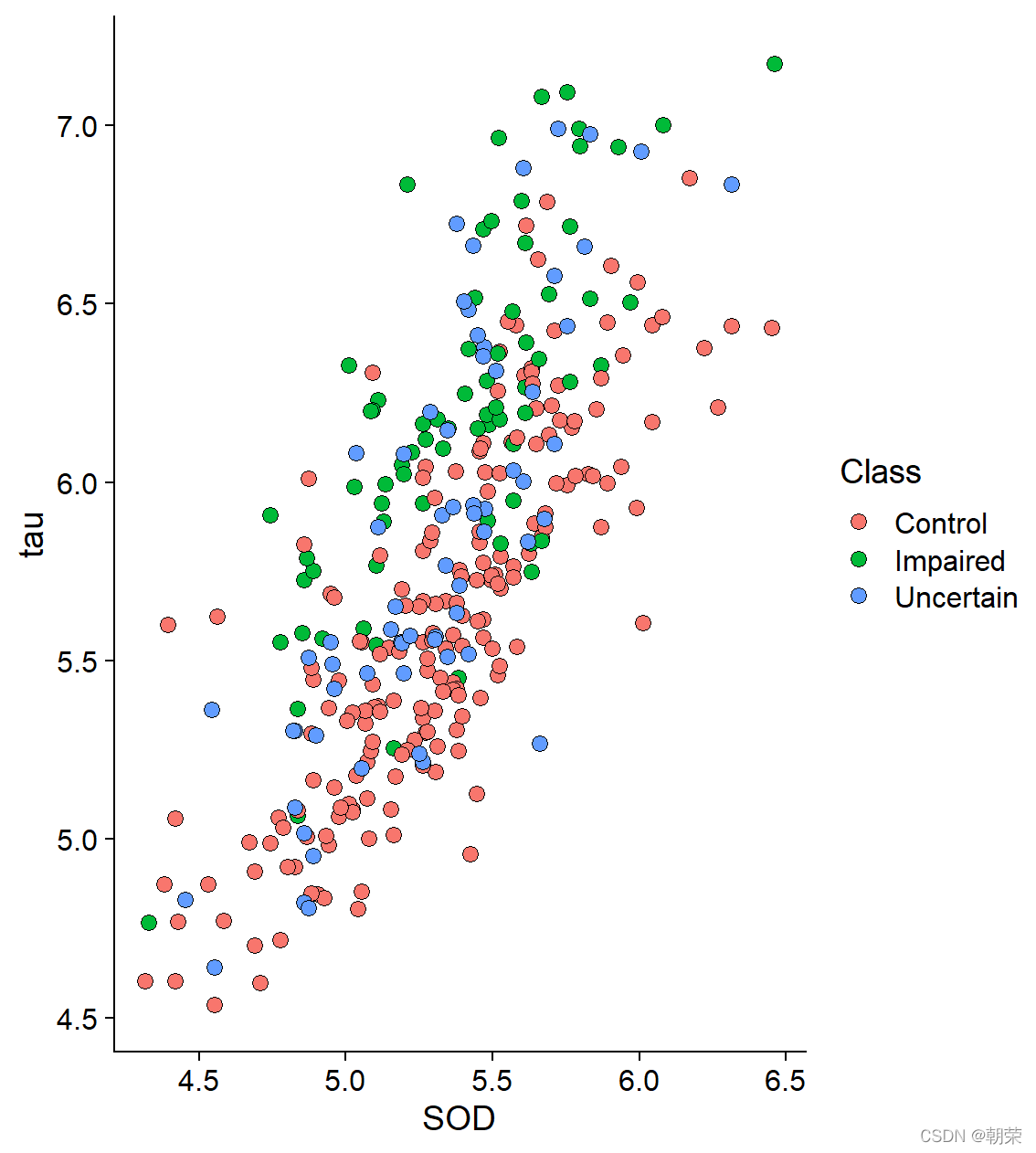
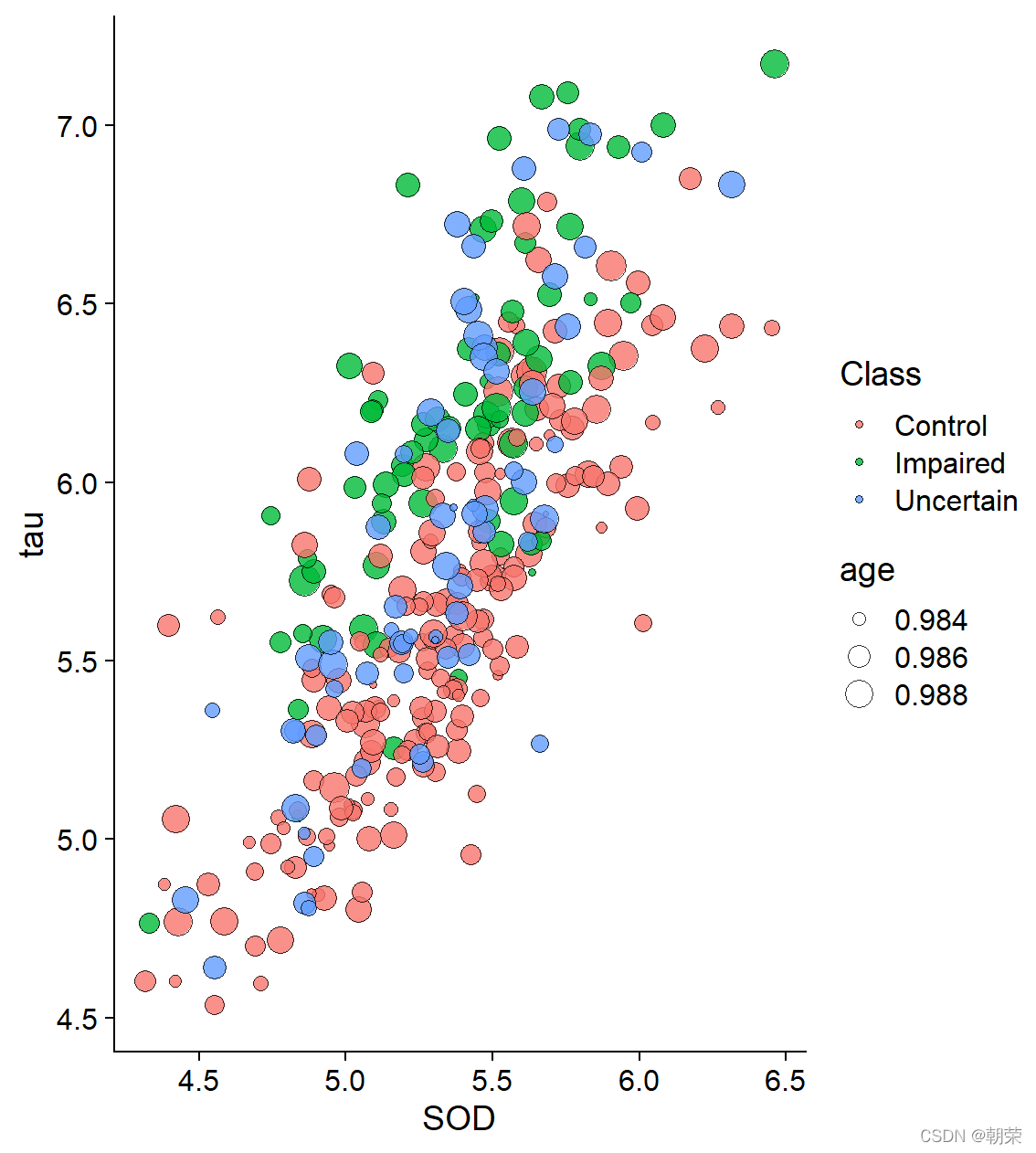
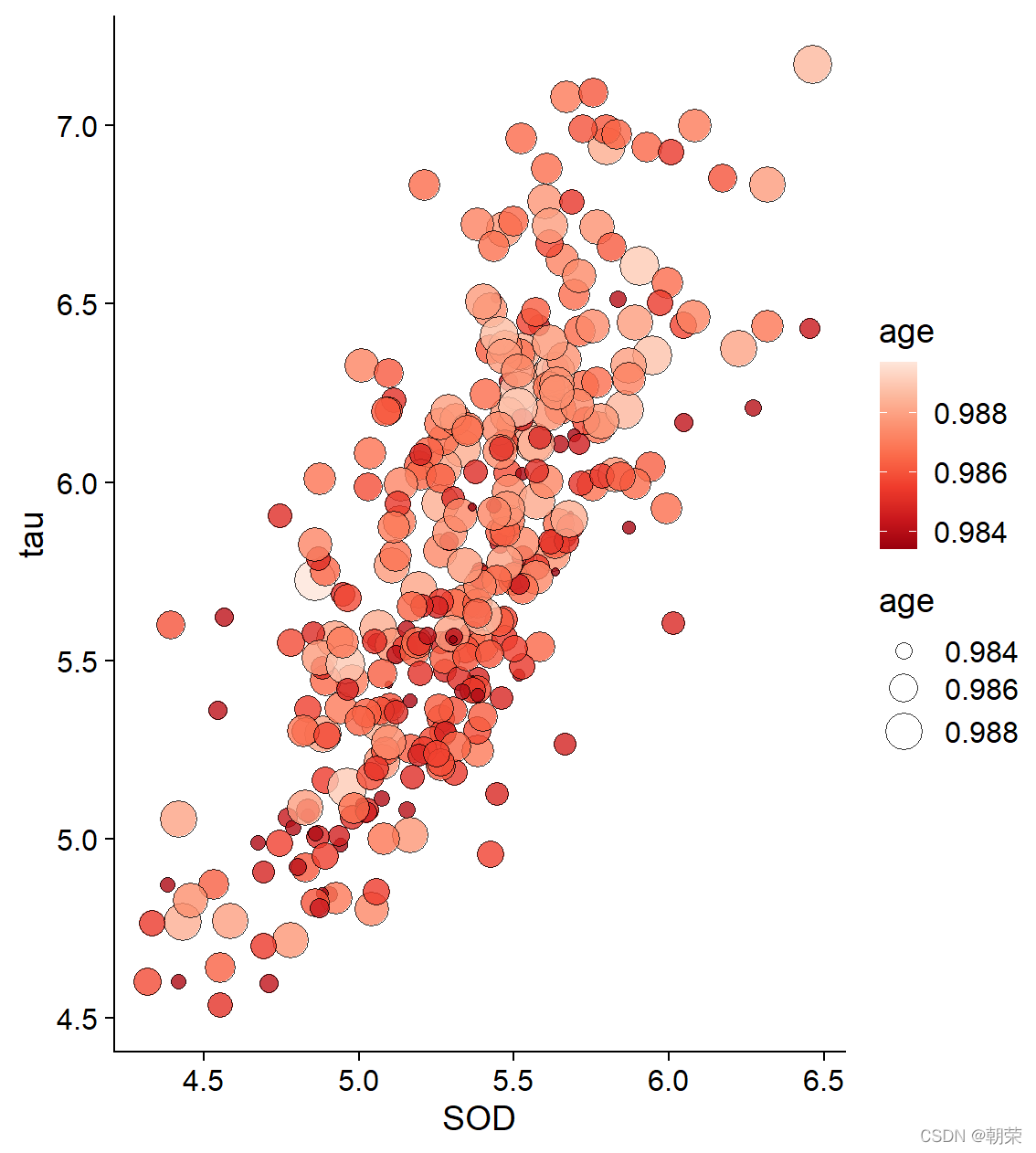
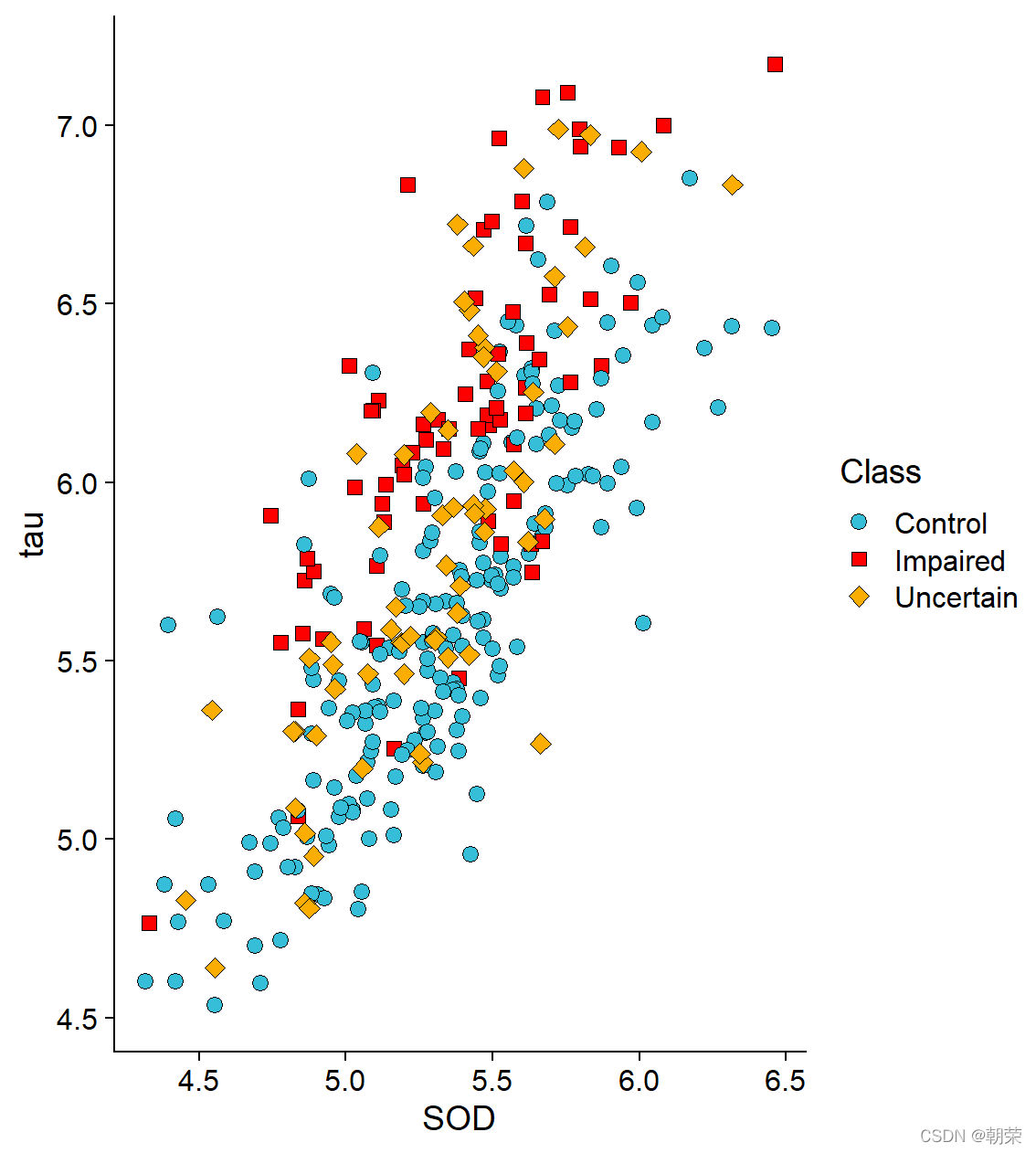
# different scalesggplot(df, aes(x=SOD, y=tau, size=age)) + geom_point(shape=21, color="black", fill="#E53F2F", stroke=0.25, alpha=0.8) +scale_size(range = c(1, 8)) +theme_cowplot()ggplot(df, aes(SOD, tau, fill=age, size=age)) + geom_point(shape=21,colour="black",stroke=0.25, alpha=0.8) +scale_size(range = c(1, 8)) +scale_fill_distiller(palette="Reds") +theme_cowplot()ggplot(df, aes(x=SOD, y=tau, fill=Class, shape=Class)) + geom_point(size=3, colour="black", stroke=0.25)+scale_fill_manual(values=c("#36BED9", "#FF0000", "#FBAD01")) +scale_shape_manual(values=c(21,22,23)) +theme_cowplot()ggplot(df, aes(SOD, tau, fill=Class, size=age)) + geom_point(shape=21, colour="black", stroke=0.25, alpha=0.8) +scale_fill_manual(values=c("#36BED9","#FF0000","#FBAD01")) +scale_size(range = c(1, 8)) + theme_cowplot()
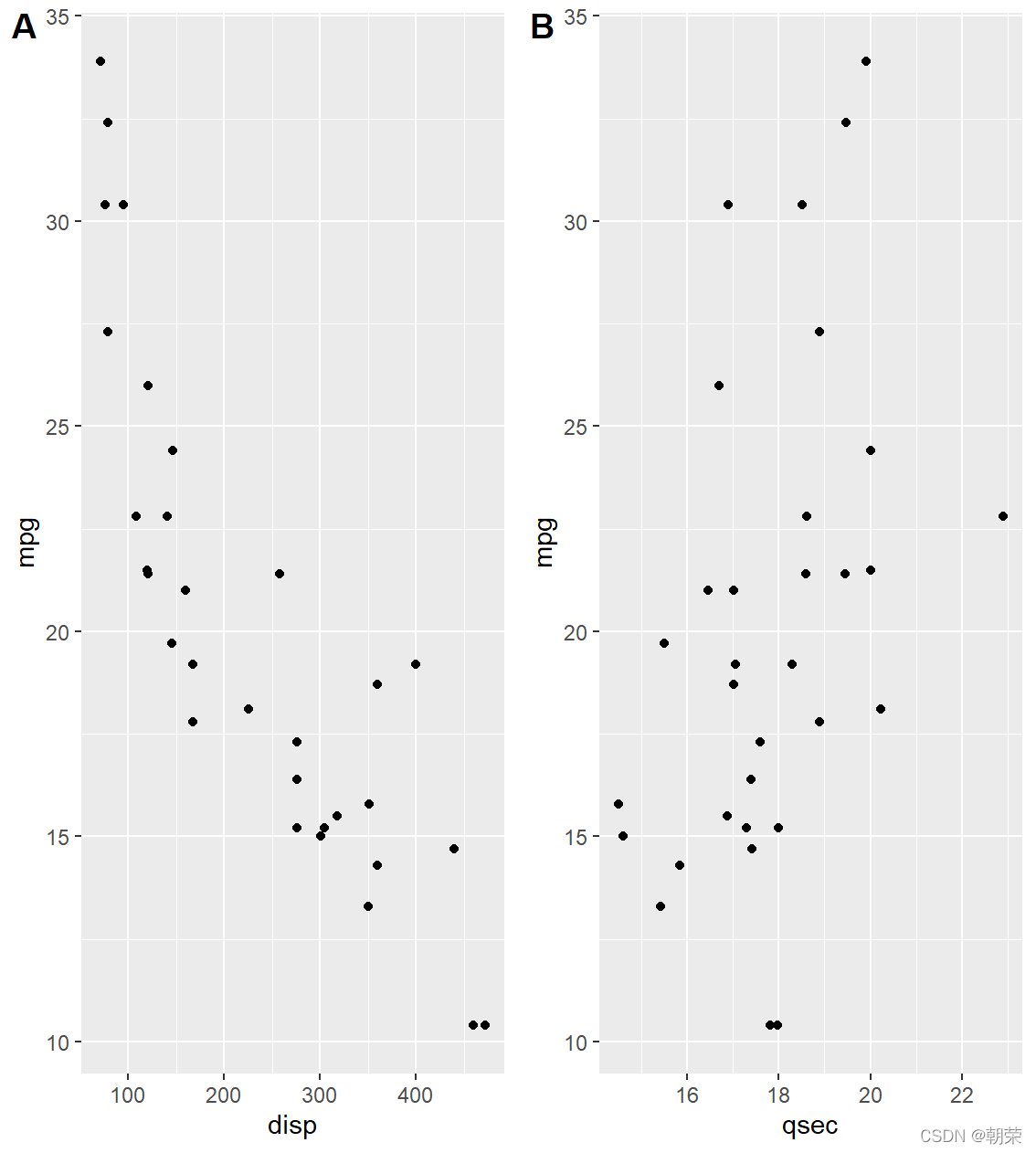
# multi-plotsp1 p2 plot_grid(p1, p2, labels = c('A', 'B')) # color brewerdf
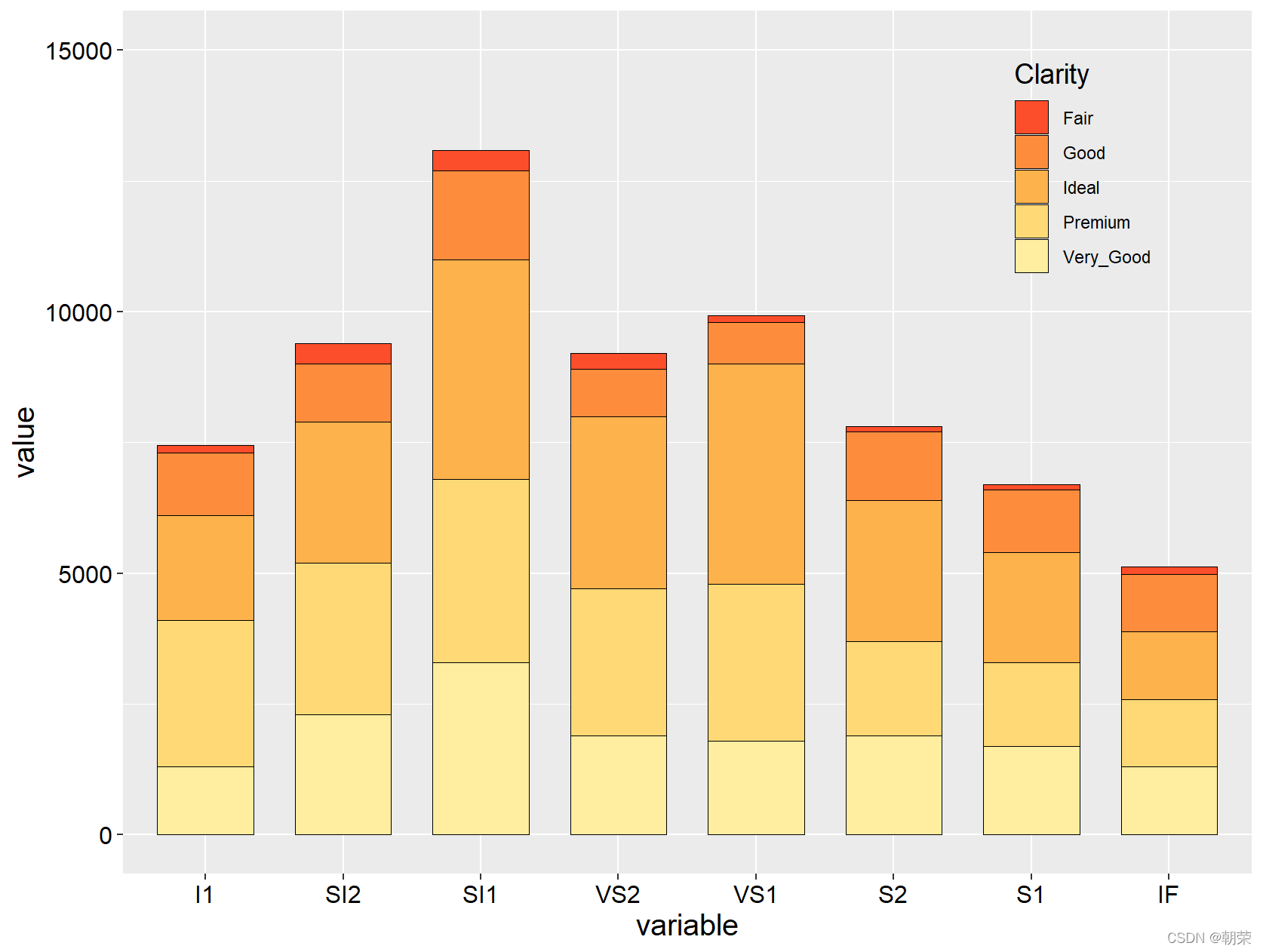
# bar plotsmydata
mydata
mydata
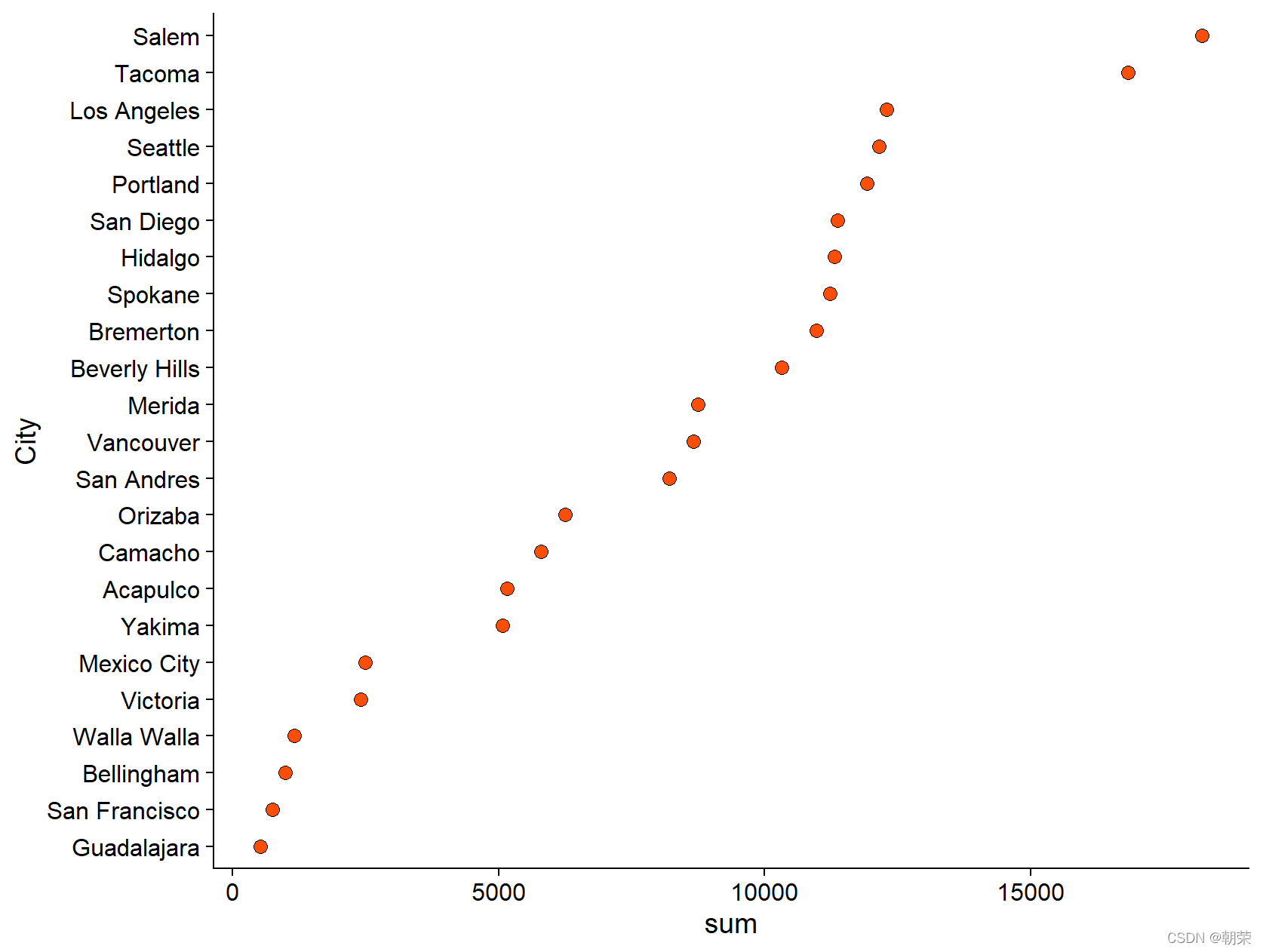
mydata # cleveland plotmydata mydata$sum mydata$City
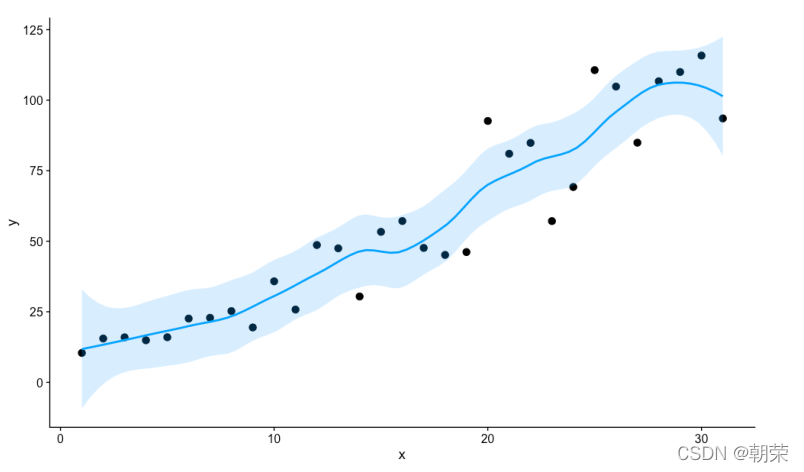
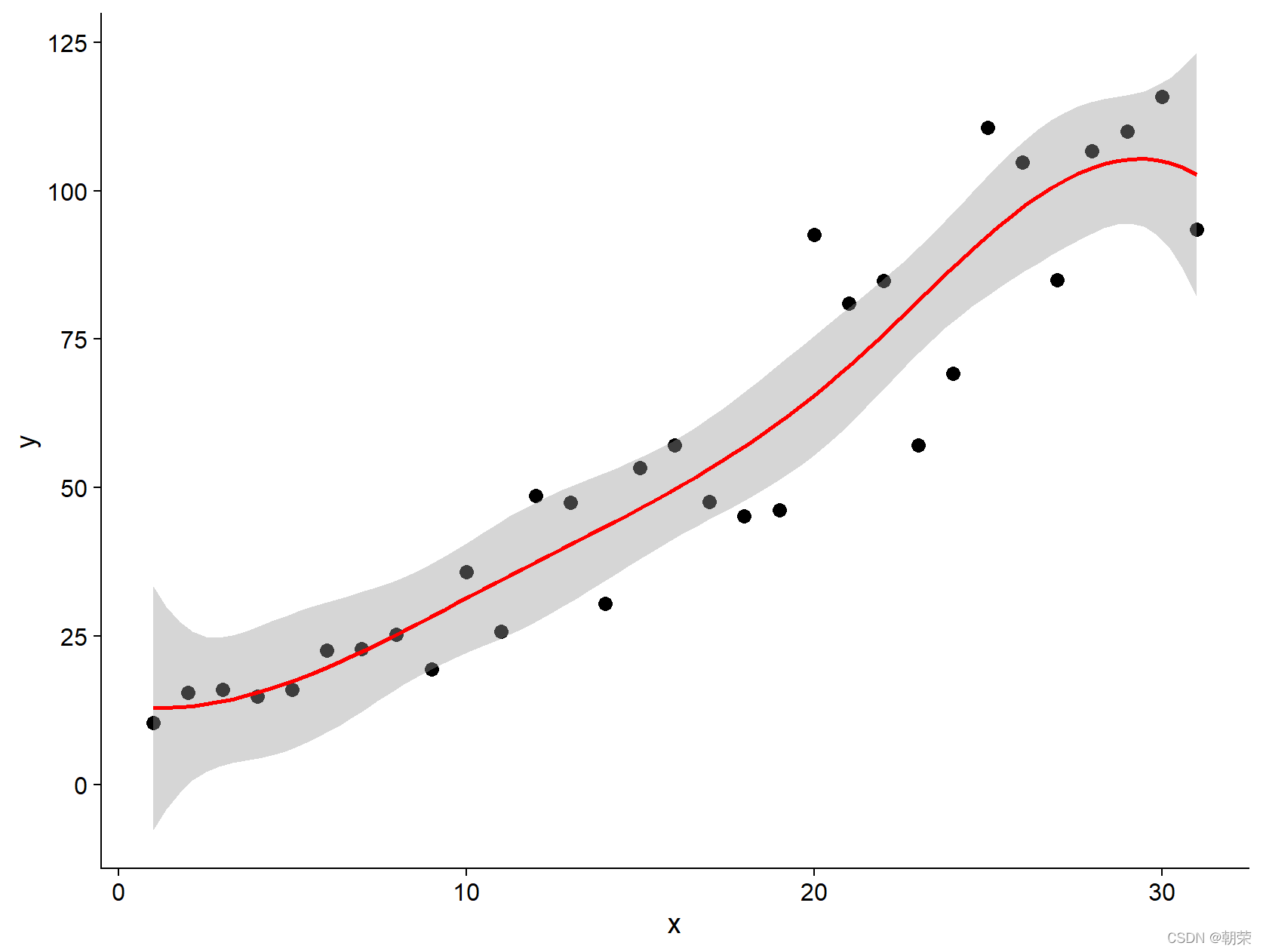
# scatter plot with smoothingmydata
# bubble chartggplot(data=mtcars, aes(x=wt,y=mpg))+geom_point(aes(size=disp, fill=disp), shape=21, colour="black", alpha=0.8)ggplot(data=mtcars, aes(x=wt, y=mpg)) +geom_point(aes(size=disp, fill=disp), shape=21, colour="black", alpha=0.8) +scale_fill_gradient2(low="#377EB8",high="#E41A1C",limits = c(0,max(mtcars$ disp)),midpoint = mean(mtcars$disp)) +theme_cowplot()ggplot(data=mtcars, aes(x=wt,y=mpg))+geom_point(aes(size=disp,fill=disp),shape=22,colour="black",alpha=0.8)+scale_fill_gradient2(low="#377EB8",high="#E41A1C",limits = c(0,max(mtcars$ disp)),midpoint = mean(mtcars$disp))
# histogram/density df
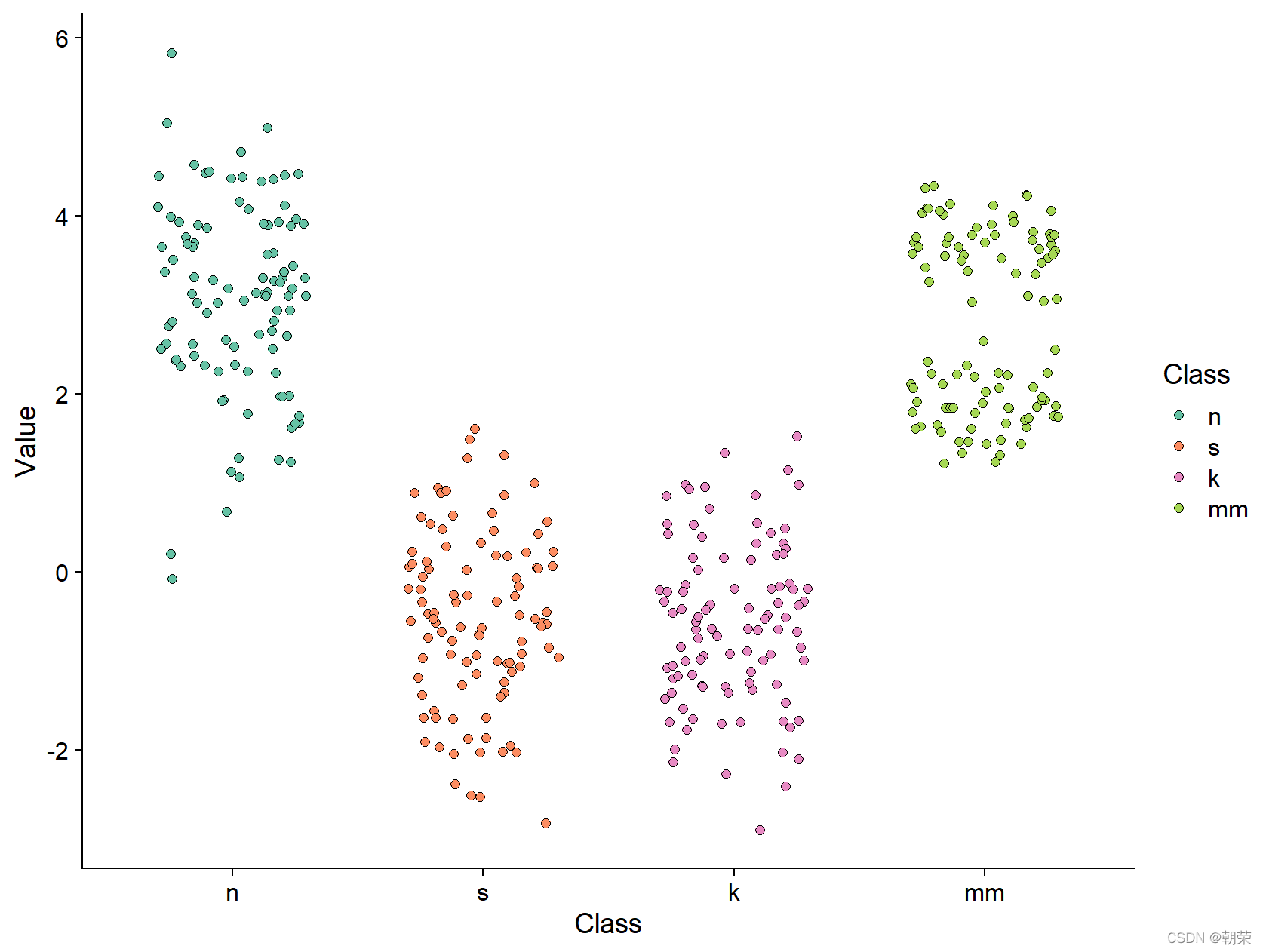
# jitterlibrary(SuppDists)set.seed(141079)n s k mm mydata )ggplot(mydata, aes(Class, Value)) +geom_jitter(aes(fill = Class), position = position_jitter(0.3), shape=21, size=2)+scale_fill_manual(values=c(brewer.pal(7,"Set2")[c(1,2,4,5)]))+theme_cowplot()
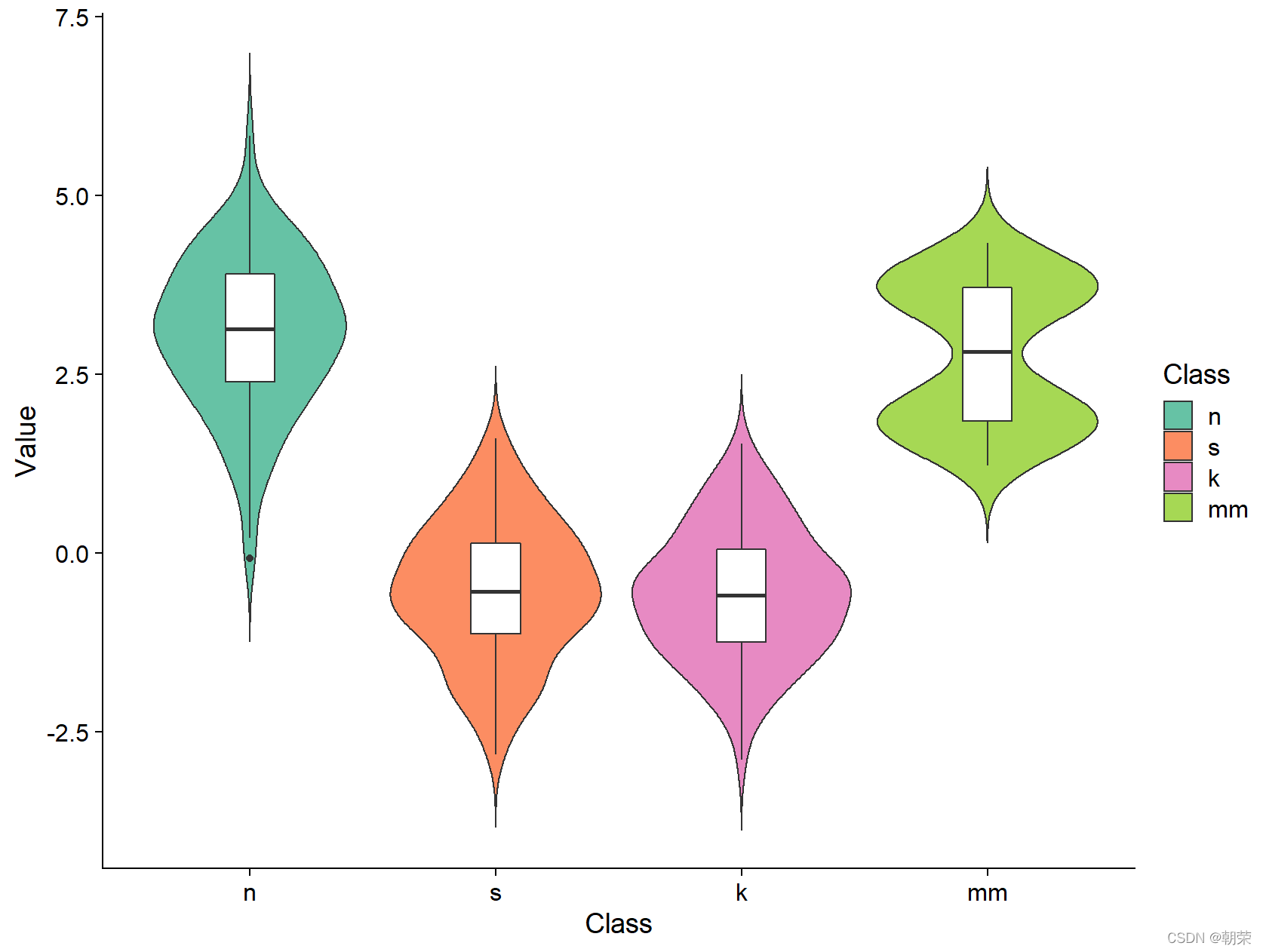
# violin plotggplot(mydata, aes(Class, Value))+ geom_violin(aes(fill = Class), trim = FALSE) +geom_boxplot(width = 0.2) +scale_fill_manual(values=c(brewer.pal(7,"Set2")[c(1,2,4,5)]))+theme_cowplot()
# ggpubrlibrary(ggpubr) palette
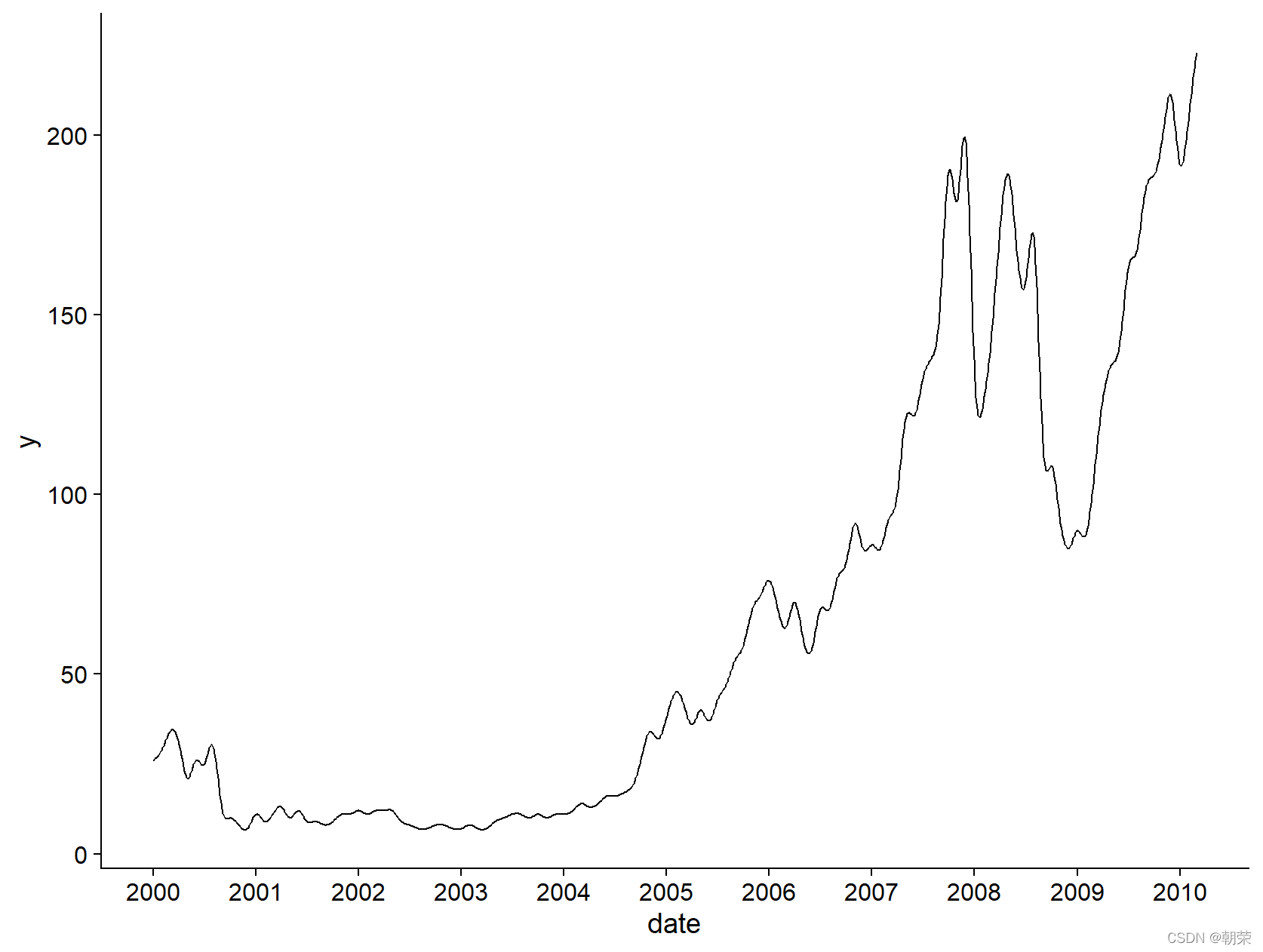
# line plot, area plotlinedata linedata$date
# donut plotmodel11 model11$Organism mypalette
# heatmaplibrary(pheatmap)df colormap breaks
# treemaplibrary(treemapify)comm comm$name mypalette
|











































【本文地址】