| GBK/GBK2312字库寻址及使用原理 | 您所在的位置:网站首页 › oracle查询汉字GBK编码 › GBK/GBK2312字库寻址及使用原理 |
GBK/GBK2312字库寻址及使用原理
|
一、字符编码
1.1.ASCII编码
我们知道,我们所见到的所有字符编码,对于计算机来说都是0、1。更具不同位上的0、1,一个字节(8位)共有256中排列方式,因此一个字节就可以表示256个不同的字符。在这个前提下,ASCII编码就由美国制造出来用来表示英文、数字以及一些不可见字符。 ASCII编码共规定了128个字符,比如数字0的ASCII编码为48,符号@的ASCII编码为64,字符a的ASCII编码为97···,因为每一个字节8位共可以表示256个字符,因此对于ASCII字符是使用不完的,仅后7位便可以刚刚可以表示128个字符,因此对于ASCII字符来说,最高位永远为0。 1.2.Unicode编码我们可以发现对于一个字节来说,最多仅可以表示256个字符,那么其他语言怎么在计算机上表示呢?对我国博大精深的汉字就有超10万个。这使用一个字符是远远不够的,因此就出现了一个庞大的集合-Unicode,这个字符集将世界上几乎所有的符号都纳入其中。 这个时候问题就来了,上面已经说了一个字节最多能表示256个字符,那么这么多的汉字是肯定不够的,就一定需要两个、三个字节或者更多的字节来表示。但是这个时候,虽然可以有更多的字节来表示字符了,但是计算机又怎么知道我们是一个字节代表的一个字符还是俩个、三个字节代表的一个字符呢? 1.3.UTF-8------Unicode的实现方式之一 首先需要明确一点,UTF-8是Unicode编码的一种实现方式(Unicode只是一个符号集合,它只规定了符号的二进制代码,如严字的Unicode编码是0x4E25,却并没有规定二进制代码的存储方式)。上面我们提到了,计算机并不能区分Unicode和ASCII,但是UTF-8却可以,UTF-8的最大特点就是它是一个1-4字节可变长的编码方式,可以根据不同的符号而变化所需要的字节长度。 UTF-8的两条编码规则: ① 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 ② 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码,多出位补0。 在进行中文编码之前,需要了解三个概念以及他们之间的关系 区位码(10进制):GB2312-80的全部字符由94*94的方阵组成,每行称为区,编号为1-94,每列称为位。这样即可得到一个区位图,用区位图的位置来表示汉字编码称为区位码。简单的说就是在GB2312-80规定中将汉字分区分位,区位码顾名思义就是代表该汉字在哪个区以及区中具体哪一位。在线转换工具国标码(16进制):汉字编码遵循的标准,GB2312-80就是国标码。机内码(16进制):为了避免ASCII码和国标码同时使用产生的歧义。汉字系统将国标码每个字节高位置加1作为汉字机内码。三者之间的联系: 国标码 = 区位码转十六进制 + 0x2020 机内码 = 国标码 + 0x8080 1.4.2.GBK/GBK2312编码规范GB2312:是中国制定的GB2312-80的简称,其中一共收纳了7445个字符,包括6763个汉字以及682个其他符号。GB2312编码都由2字节构成。GB2312详细请参看区位码部分。 GB13000:包含GB2312已有的文字和其他很多为包含的文字,如GB2312-80推出以后才简化的汉字。 GBK:后面微软对GB2312-80扩展,利用起未使用的编码空间,收录了所有Unicode及GB13000中的汉字全部字符。GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个 二、字库实现 2.1.LCD显示的基本原理LCD的显示原理是及其复杂的,但是对于软件开发来说我们不需要了解那么多,我们只需要知道LCD的基本原理就可以了。对于一个屏幕来说,我们只需要将他看成一张白纸即可,我们的显示无疑就是在这个白纸上画一个一个的点。点的有序排列既可以显出出我们所看到的汉字或者各种图像。 其实我们汉字的显示就是这样的,首先我们对相应的汉字取模的过程就是将一个汉字转成了一个数组,数组中对应的16进制转成2进制之后的0、1排列就是对应显示屏上的点阵点亮还是熄灭。 2.2.GBK编码字库实现(寻址)了解了编码规范之后,接下来说一下GBK编码应该如何解码。上面说到,每一个GBK编码都是由2个字节组成: 第一个字节的范围为0x81-0xFE,第二个字节被分成了两个部分,分别是0x40-0x7E、0x80-0xFE。其中第一字节代表的意义称为区,因此GBK里面总共有126个区(0xEF-0x81+1=126)。第二个字节代表的意义是每个区内有多少个汉字,总共有190(0xFE-0x80+0x7E-0x40+2=190)个。观察第二部分可以看到0x7F和0xFF两个字节不存在,但是为了能够线性查找我们暂且认为这两个字节也是存在的,那么每个区就有192个汉字。 知道了GBK的编码之后,我们就能够在字库中找到对应汉字的偏移量,方法如下: 上文已经说到区位码、国标码以及机内码,并且说明了三者之间的关系。在这里主要描述一下GB2312的字库寻址原理,同时通过寻址的过程了解一下三者的具体含义。 首先我们使用UltraEdit打开一个文件并写入一个汉字“瑞”,通过软件的16进制编辑功能我们可以看到瑞的机内码为0xC8F0,如下图: |
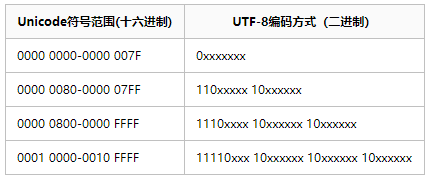 以瑞字为例,它的Unicode编码是0x745E,转为二进制为111010001011110共15位,也就是至少需要两个字节表示。按着UTF-8的编码规范可以知道瑞字Unicode对应的UTF-8编码为:111001111001000110011110,转为十六进制为E791E9。
以瑞字为例,它的Unicode编码是0x745E,转为二进制为111010001011110共15位,也就是至少需要两个字节表示。按着UTF-8的编码规范可以知道瑞字Unicode对应的UTF-8编码为:111001111001000110011110,转为十六进制为E791E9。  (汉字对应表)
(汉字对应表) 以上代码应该还算简单易懂,GBKH-=0x81的目的是找到汉字对应的区,GBKL同理找到字所在区内的位置。已知每个区有192个汉字,每个1616大小的汉字占32字节(1616/8=32)。即可算出我们所查找的汉字的偏移量。
以上代码应该还算简单易懂,GBKH-=0x81的目的是找到汉字对应的区,GBKL同理找到字所在区内的位置。已知每个区有192个汉字,每个1616大小的汉字占32字节(1616/8=32)。即可算出我们所查找的汉字的偏移量。 通过我们上面介绍的三者关系我们可以得到,瑞字的国标码为0x4870,区位码为0x2850(转为十进制为4080)。通过上文的软件进行验证,如下图:
通过我们上面介绍的三者关系我们可以得到,瑞字的国标码为0x4870,区位码为0x2850(转为十进制为4080)。通过上文的软件进行验证,如下图:  经过我们的计算及验证,我们可以知道瑞字在GB2312区位图中的40区80位。如此便可以找到我们需要找的字。 具体算法及示例如下(以16*16为例):
经过我们的计算及验证,我们可以知道瑞字在GB2312区位图中的40区80位。如此便可以找到我们需要找的字。 具体算法及示例如下(以16*16为例): 

【本文地址】