| 线性回归(Linear Regression)和最小二乘法(ordinary least squares) | 您所在的位置:网站首页 › ols和最小二乘法 › 线性回归(Linear Regression)和最小二乘法(ordinary least squares) |
线性回归(Linear Regression)和最小二乘法(ordinary least squares)
|
下面是对Andrew Ng的CS229机器学习课程讲义note1做的一部分笔记,按照自己的理解,对note1进行部分翻译,英文水平和知识水平不够,很多认识都不够深刻或者正确,请大家不吝赐教! 一、基本知识 为了更好的描述监督学习的问题,我们的目标是,给定一个训练集(training set),学习一个函数h:X->Y,因此h(x)对y而言是要一个好的predicator。将这个过程用流程图来形象的表示:
如果我们将要预测的target variable是连续的,就像我们的房屋例子一样,我们将这个学习问题叫做回归问题。当y只可以取少量的离散值的时候,就像这个例子中已知了living area的时候,我们想要预测一个dwelling是一个house还是一个apartment的时候,我们将这个问题叫做分类问题。 二、线性回归(Linear Regression)-------斯坦福公开课ML笔记note1 线性回归的目的就是使得预测值与实际值的残差平方和最小。【注:残差在数理统计中是指实际观察值与估计值(拟合值)之间的差】 为了让我们的房屋例子更加有趣,让我们考虑一个稍微丰富一些的数据集,在这个数据集中,每个房屋的bedrooms的数量是已知的。
现在X是R^2中的二维向量, 为了实行监督学习,我们必须要考虑我们将如何在计算机中进行表示functions/hypotheses。作为初始选择,假设我们将决定将y近似为x的线性函数:
这里的 这里的等式右边的θ和 x都是向量,n是输入变量的数量(但是不包括x0,取x0=1)。 现在给定一个训练集,那我们如何选取和学习得到θ?一个合理的方案是使h(x)接近y,至少在我们的训练例子中是这样的。我们定义了要给关于该方案的函数,对每一个θ,measure出
如果你以前学过线性回归,你可能认为这个函数和最小均方损失函数(least-squares cost function )很类似,并提出普通最小二乘法回归模型(ordinary least squares regression model)。 三、普通最小二乘法(ordinary least squares) 最小二乘法(又称最小平方法)是一种数学优化技术,它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和最小,该方法还可以用于曲线拟合。
离差(deviation)即标志变动度,是观测值或估计量的平均值与真实值之间的差,是反映数据分布离散程度的量度之一,或说是反映统计总体中各单位标志差别大小的程度或离差情况的指标,常写作 残差(residual)在数理统计中是指实际观察值与估计值(拟合值)之间的差。 Python代码,普通最小二乘法(Ordinary Least Squares)的简单应用。(该代码来源于:https://blog.csdn.net/claroja/article/details/70312864)代码的基本思想:先载入数据集dataset,将X变量分割成训练集和测试集,将Y目标变量分割成训练集和测试集,接着创建线性回归对象,并使用训练数据来训练模型,接着可以查看相关系数、残差平方的均值和方差得分,最后可以将测试点和预测点都直观地画在图上。 import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model#载入数据集“datasets” diabetes = datasets.load_diabetes()#获取糖尿病的数据集 diabetes_X = diabetes.data[:, np.newaxis, 2]#使用其中的一个特征,np.newaxis的作用是增加维度 diabetes_X_train = diabetes_X[:-20]#将X变量数据集分割成训练集和测试集 diabetes_X_test = diabetes_X[-20:] diabetes_y_train = diabetes.target[:-20]#将Y目标变量分割成训练集和测试集 diabetes_y_test = diabetes.target[-20:] regr = linear_model.LinearRegression()#创建线性回归对象 regr.fit(diabetes_X_train, diabetes_y_train)#使用训练数据来训练模型 print('Coefficients: \n', regr.coef_)#查看相关系数Coefficients print("Residual sum of squares: %.2f"% np.mean((regr.predict(diabetes_X_test) - diabetes_y_test) ** 2))#查看残差residual平方的均值(mean square error,MSE) # Explained variance score: 1 is perfect prediction # 解释方差得分(R^2),最好的得分是1: # 系数R^2=1 - u/v, u是残差平方,u=(y_true - y_pred) ** 2).sum() # v是离差平方和,v=(y_true - y_true.mean()) ** 2).sum() print('Variance score: %.2f' % regr.score(diabetes_X_test, diabetes_y_test))#Returns score : float R^2 of self.predict(X) wrt. y. plt.scatter(diabetes_X_test, diabetes_y_test, color='black')#画出测试的点 plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color='blue',linewidth=3)#画出预测的点 # plt.xticks(())#删除X轴的标度 # plt.yticks(())#删除Y轴的标度 plt.show() 效果图:
|
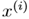 作为“input”variables(在这个例子中是living area),也叫做input features(输入特征),
作为“input”variables(在这个例子中是living area),也叫做input features(输入特征), 作为“output”或者target variables,我们将用
作为“output”或者target variables,我们将用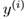 来预测(price)。
来预测(price)。 是一个training example,并且用来学习的dataset是m个training examples{
是一个training example,并且用来学习的dataset是m个training examples{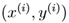 ,i=1,…m},叫做一个training set。注意,这里的右上角的“i”只是说明这个training dataset中的index而已,和exponentiation(求幂)无关。X=Y=R(X作为输入空间,Y作为输出空间)
,i=1,…m},叫做一个training set。注意,这里的右上角的“i”只是说明这个training dataset中的index而已,和exponentiation(求幂)无关。X=Y=R(X作为输入空间,Y作为输出空间)

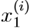 是训练集中的第i个房子的living area,
是训练集中的第i个房子的living area, 是训练集中的第i个房子的bedrooms。(通常来说,当设计一个学习问题的时候,是由你自己来决定选取什么作为features的,比如当你收集房屋数据的时候,可能会决定将房屋是否有fireplace或者bedrooms的数量作为features。)
是训练集中的第i个房子的bedrooms。(通常来说,当设计一个学习问题的时候,是由你自己来决定选取什么作为features的,比如当你收集房屋数据的时候,可能会决定将房屋是否有fireplace或者bedrooms的数量作为features。)
 是参数,代表的是weights,通过这个线性函数从X映射到Y。
是参数,代表的是weights,通过这个线性函数从X映射到Y。
 和
和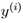 之间的联系。我们定义了cost function(损失函数):
之间的联系。我们定义了cost function(损失函数):

 ,即参与计算平均数的变量值与平均数之差。
,即参与计算平均数的变量值与平均数之差。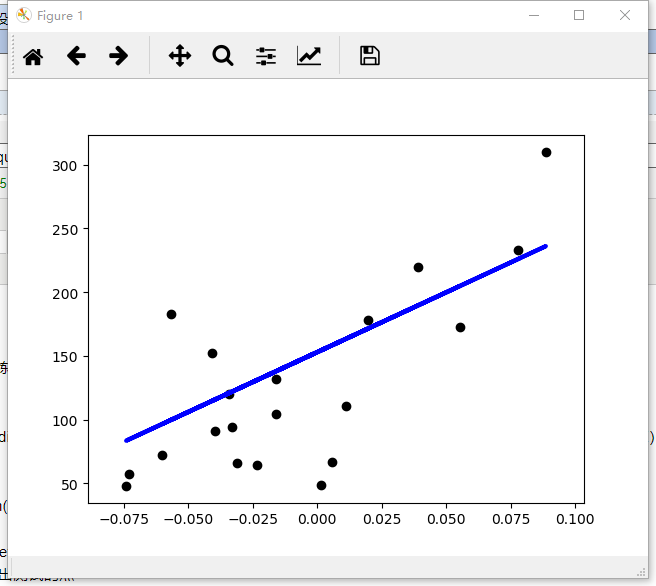
【本文地址】