|
文件类型:.csv,.txt,.xlsx .csv文件,一行即为数据表的一行。生成数据表字段用逗号隔开(英文的逗号!!!!)。csv文件用记事本和excel都能打开,用记事本打开显示逗号,用excel打开,没有逗号了,逗号都用来分列了。 .txt文件和.csv文件没有太大差别,.txt文件也可由用逗号进行分割,直接将.txt文件改成.csv文件完全可以。.txt文件也可以用空格分割

用excel打开data1.csv(左),data2.csv(右)文件后的内容  用记事本打开data1.csv(左),data2.csv(右)后 用记事本打开data1.csv(左),data2.csv(右)后 
1.读取.csv文件
import pandas as pd
'''
读取data1.csv
'''
#读取csv文件pd.read_csv(文件路径)
#df1为DataFrame
df1=pd.read_csv(r"C:\data\data1.csv") #注意要不加r则要将'\'换成'/'。默认的编码方式是utf8,pandas默认的编码方式是utf8
#pd.read_csv(r"C:\data\data1.csv",encoding='utf8',engin='python')。
'''
写成这种形式也行。因为有时候需要带上参数,否则会报错OSError: Initializing from file failed。
'''
df1中的内容 
'''
读取data2.csv,从上面打开的data2.csv可以看出,data2没有列名,而data1有列名
如果用和data1一样的写法,则df2中的内容会和预期的不一样。
'''
df2=pd.read_csv(r"C:\data\data2.csv")
#df2为DataFrame
从df2中的结果可以看出,第一行的数据当成了列名,这显然不是我们想要的结果。 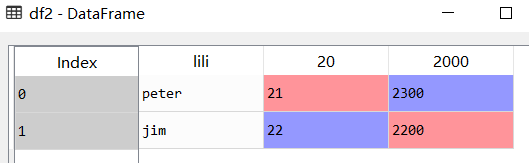 无列名时,读取.csv文件的正确写法如下 无列名时,读取.csv文件的正确写法如下
df2=pd.read_csv(r"C:\data\data2.csv",header=None)
再次查看df2中的内容,可以发现此时和我们预期的结果一样。 
2.读取excel文件(.xlsx文件)
打开data3.xlsx后,内容如下 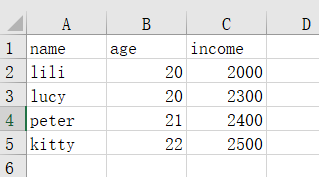
'''
当excel文件没有列名时,也需要加header=None。
'''
df3=pd.read_excel(r"C:\data\data3.xlsx")#df3为DataFrame
df3中的内容如下: 
3.读取.txt文件
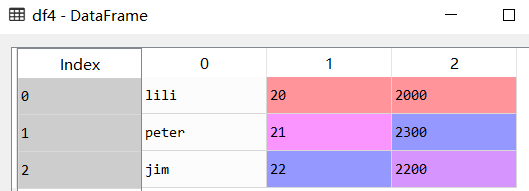
打开data4.txt后。 
df4=pd.read_table(r"C:\data\data4.txt",header=None)#因为data4.txt没有列名。所以要加上header=None
从下图可以看出,结果和我们预期的还是不一样  正确写法如下: 正确写法如下:
df4=pd.read_table(r"C:\data\data4.txt",header=None,sep=',')#加上分隔符参数
4.导出
'''
以df1为例
'''
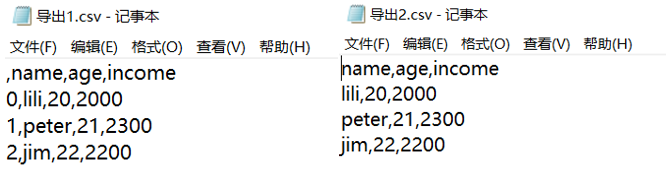
df1.to_csv(r"C:\data\导出1.csv",index=True,header=True) #注意导出的文件后缀要写成.csv
df1.to_csv(r"C:\data\导出2.csv",index=False,header=True)#index和header默认为True
df1.to_excel(r"C:\data\导出.xlsx")#注意导出的文件后缀要写成.xlsx
df1.to_csv(r"C:\data\导出5.csv",index=False,header=False)#index和header默认为True

df2.to_csv(r"C:\data\导出3.csv",index=True,header=True) #注意导出的文件后缀要写成.csv
df2.to_csv(r"C:\data\导出4.csv",index=False,header=False)#index和header默认为True

|