| PyTorch入门(一):Tensors | 您所在的位置:网站首页 › numpy库怎么导入anoconda › PyTorch入门(一):Tensors |
PyTorch入门(一):Tensors
|
PyTorch入门(一):Tensors
张量(Tensors)是线性代数中的重要概念,它在数学和物理学中扮演着重要的角色,并在计算机科学领域中得到广泛应用。张量可以被看作是多维数组(或矩阵)的推广,它可以包含任意数量的维度。 在数学和物理学中,张量被用于描述物理量的属性和变换规律。它可以表示向量、矩阵、标量等,以及它们之间的运算和相互关系。张量具有坐标无关性,这意味着它的表示方式与坐标系的选择无关,只与物理量的本质属性有关。 在计算机科学领域,张量广泛应用于机器学习和深度学习等领域。在这些领域中,张量被用于表示和处理多维数据。例如,在图像处理中,一幅图像可以表示为一个三维张量,其中的每个元素代表像素的值。在PyTorch中,张量(Tensors)是最基本的数据结构,用于表示和操作多维数组。PyTorch是一个广泛用于深度学习的开源框架,它提供了张量作为核心数据类型,以支持高效的数值计算和自动微分。 PyTorch中的张量类似于NumPy中的多维数组,但具有额外的功能和优化,使其适用于深度学习任务。PyTorch的张量是可以在GPU上进行加速计算的,这使得它在大规模深度学习模型的训练和推理中非常有用。 首先,我们导入必要的库: import torch import numpy as np这两行代码导入了PyTorch和NumPy库。下面是代码的解释: • import torch: 这行代码导入了PyTorch库,它是一个用于构建深度学习模型的开源机器学习库。PyTorch提供了丰富的函数和类,用于张量计算、自动微分和构建神经网络等任务。 • import numpy as np: 这行代码导入了NumPy库,并将其命名为np。NumPy是一个常用的Python库,用于进行科学计算和数值操作。它提供了高性能的多维数组对象(例如ndarray)、数学函数、线性代数运算等功能,是许多数据科学和机器学习任务的核心工具之一。 通过导入这两个库,可以在代码中使用PyTorch和NumPy提供的函数和类,以便进行深度学习和数值计算。 一、初始化Tensor创建Tensor有多种方法,如: 1. 直接从数据创建可以直接利用数据创建tensor,数据类型会被自动推断出: data = [[1, 2],[3, 4]] x_data = torch.tensor(data)这段代码创建了一个名为 data 的 Python 列表,其中包含两个子列表 [[1, 2], [3, 4]]。然后,使用 torch.tensor() 函数将 data 转换为一个 PyTorch 张量,并将其赋值给名为 x_data 的变量: • torch.tensor() 函数用于从现有的数据创建张量。通过传递一个可迭代对象(如列表)作为参数,函数会创建一个与输入数据具有相同形状和数据类型的张量。在这种情况下,输入数据 data 是一个二维列表,包含两个子列表,每个子列表都包含两个整数。 通过执行这段代码,你创建了一个名为 x_data 的 PyTorch 张量,其形状为 (2, 2),即 2 行 2 列。张量 x_data 中的数据与输入的 data 相同,即 [[1, 2], [3, 4]]。这样,你可以利用 PyTorch 提供的各种功能和方法对这个张量进行进一步的操作和分析。 2. 从Numpy创建Tensor 可以直接从 numpy 的 array 创建: np_array = np.array(data) x_np = torch.from_numpy(np_array)这段代码首先使用 np.array() 函数将 data 转换为一个 NumPy 数组,并将其赋值给 np_array 变量: • np.array() 函数用于从现有数据创建一个 NumPy 数组。在这个例子中,data 是一个二维列表,通过调用 np.array(data),我们将其转换为一个形状为 (2, 2) 的 NumPy 数组。 接下来,使用 torch.from_numpy() 函数将 np_array 转换为一个 PyTorch 张量,并将其赋值给 x_np 变量。 • torch.from_numpy() 函数用于从 NumPy 数组创建一个 PyTorch 张量。通过调用 torch.from_numpy(np_array),我们将 np_array 转换为一个与其形状和数据类型相匹配的 PyTorch 张量。 通过执行这段代码,你创建了一个名为 x_np 的 PyTorch 张量,其形状为 (2, 2),数据与输入的 data 相同。不同于 torch.tensor(),torch.from_numpy() 并不会创建新的张量,而是将 NumPy 数组与 PyTorch 张量共享相同的底层数据。这意味着在不复制数据的情况下,你可以在 PyTorch 张量上利用 NumPy 数组的功能。 3. 从其他tensor创建新的 tensor 保留了参数 tensor 的一些属性(形状,数据类型),除非显式覆盖。 x_ones = torch.ones_like(x_data) print(f"Ones Tensor: \n {x_ones} \n") x_rand = torch.rand_like(x_data, dtype=torch.float) print(f"Random Tensor: \n {x_rand} \n")运行结果如下: 这段代码中,首先使用 torch.ones_like() 函数创建一个形状与 x_data 相同的张量 x_ones,其中的元素值都设为1: • torch.ones_like() 函数用于创建一个与输入张量形状相同的张量,并将所有元素初始化为1。在这个例子中,由于 x_data 的形状是 (2, 2),所以 x_ones 也将具有相同的形状,并且所有元素的值都是1。 • 接下来,使用 torch.rand_like() 函数创建一个形状与 x_data 相同的张量 x_rand,其中的元素值是从均匀分布中随机采样得到的。 • torch.rand_like() 函数用于创建一个与输入张量形状相同的张量,并将所有元素初始化为从均匀分布中随机采样得到的值。在这个例子中,x_rand 的形状与 x_data 相同,元素的数据类型为 torch.float。 4. 从常数或者随机数创建shape 是关于 tensor 维度的一个元组,在下面的函数中,它决定了输出 tensor 的维数: shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape) print(f"Random Tensor: \n {rand_tensor} \n") print(f"Ones Tensor: \n {ones_tensor} \n") print(f"Zeros Tensor: \n {zeros_tensor}")运行结果如下: 这段代码创建了三个张量:rand_tensor、ones_tensor 和 zeros_tensor,它们的形状均为 (2, 3): • 首先,使用 torch.rand() 函数创建了一个形状为 (2, 3) 的随机张量 rand_tensor。torch.rand() 函数会生成一个张量,其中的元素值是从均匀分布中随机采样得到的。 • 接着,使用 torch.ones() 函数创建了一个形状为 (2, 3) 的张量 ones_tensor,其中所有的元素值都设为1。torch.ones() 函数会生成一个张量,其中的所有元素都被初始化为1。 • 最后,使用 torch.zeros() 函数创建了一个形状为 (2, 3) 的张量 zeros_tensor,其中所有的元素值都设为0。torch.zeros() 函数会生成一个张量,其中的所有元素都被初始化为0。 二、Tensor的属性Tensor的属性包括形状,数据类型以及存储的设备。 tensor = torch.rand(3,4) print(f"Shape of tensor: {tensor.shape}") print(f"Datatype of tensor: {tensor.dtype}") print(f"Device tensor is stored on: {tensor.device}")运行结果如下: 第一行代码打印了 tensor 的形状,使用 tensor.shape 可以获取张量的形状。在这个例子中,tensor 的形状是 (3, 4)。 第二行代码打印了 tensor 的数据类型,使用 tensor.dtype 可以获取张量的数据类型。在这个例子中,由于 tensor 是通过 torch.rand() 函数创建的,因此它的数据类型是由函数默认的数据类型决定的,通常为 torch.float32。 第三行代码打印了 tensor 存储的设备信息,使用 tensor.device 可以获取张量所存储的设备。在这个例子中,由于没有显式指定设备,所以 tensor 被存储在默认的设备上,通常是 CPU。 三、Tensor的操作Tensor有超过100个操作,包括 transposing, indexing, slicing, mathematical operations, linear algebra, random sampling,更多详细的介绍请点击这里。 尝试列表中的一些操作。如果你熟悉 NumPy API,你会发现 tensor 的 API 很容易使用。 1. 标准的 numpy 类索引和切片: tensor = torch.ones(4, 4) tensor[:,1] = 0 print(tensor)运行结果如下: 例如,如果 tensor 的初始值为: tensor([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]])经过修改后,tensor 的值将变为: tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])其中,所有行的第二列元素的值由1变为0,而其他列的元素保持为1。 2. 合并 tensors可以使用torch.cat来沿着特定维数连接一系列张量。 torch.stack另一个加入op的张量与torch.cat有细微的不同: t1 = torch.cat([tensor, tensor, tensor], dim=1) print(t1)运行结果如下: • torch.cat() 函数的第一个参数是一个张量列表,这里输入了3个相同的张量 tensor,表示将3个张量在列维度上拼接。第二个参数 dim=1 表示在列维度上进行拼接。 通过执行这段代码,你将得到一个新的张量 t1,其形状为 (4, 12),其中行数不变,列数为原来的3倍。新的张量中,原来的张量 tensor 在列维度上被拼接了3次,每次占用4列。 3. 增加 tensors print(f"tensor.mul(tensor) \n {tensor.mul(tensor)} \n") print(f"tensor * tensor \n {tensor * tensor}")运行结果如下: 这段代码演示了两种计算张量元素之间逐元素乘法的方法: • 第一种方法使用了 tensor.mul(tensor),其中 mul() 是 torch.mul() 函数的简写形式。这个操作将两个张量 tensor 逐元素相乘,生成一个新的张量。输出结果通过 print() 函数打印出来。 • 第二种方法使用了 tensor * tensor,它直接使用了乘法运算符 * 对两个张量 tensor 进行逐元素相乘操作。同样,输出结果通过 print() 函数打印出来。 通过执行这段代码,你会看到两个输出结果是相同的,都是计算了张量 tensor 中元素的逐元素乘积。这意味着对应位置上的元素相乘,生成了一个与输入张量形状相同的新张量。 例如,如果初始时 tensor 的值为: tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])经过元素逐元素乘法后,输出结果将是: tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])即每个元素与自身相乘,结果仍然保持不变。 print(f"tensor.matmul(tensor.T) \n {tensor.matmul(tensor.T)} \n") print(f"tensor @ tensor.T \n {tensor @ tensor.T}")运行结果如下: • 第一种方法使用了 tensor.matmul(tensor.T),其中 matmul() 是 torch.matmul() 函数的简写形式。这个操作将张量 tensor 与其转置矩阵 tensor.T 进行矩阵乘法运算,生成一个新的张量。输出结果通过 print() 函数打印出来。 • 第二种方法使用了 tensor @ tensor.T,它直接使用了 @ 符号对两个张量 tensor 进行矩阵乘法操作。同样,输出结果通过 print() 函数打印出来。 通过执行这段代码,你会看到两个输出结果是相同的,都是计算了张量 tensor 与其转置矩阵 tensor.T 的矩阵乘法。输出结果的形状将根据乘法运算规则进行调整。 4. 原地操作带有后缀_的操作表示的是原地操作,例如: x.copy_(y), x.t_()将改变 x. print(tensor, "\n") tensor.add_(5) print(tensor)运行结果如下: • 首先,通过 print() 函数打印输出了张量 tensor 的初始值。 • 接着,使用 tensor.add_(5) 进行原地加法操作,将张量 tensor 的每个元素都加上了5。这里使用了 _ 后缀的原地版本 add_(),表示直接在原始张量上进行修改,而不是创建一个新的张量。 • 最后,再次通过 print() 函数打印输出了修改后的张量 tensor。 通过执行这段代码,你会看到两个输出结果。第一个输出是张量 tensor 的初始值,第二个输出是经过原地加法操作后的张量 tensor。 例如,如果初始时 tensor 的值为: tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])经过原地加法操作后,张量 tensor 的值将变为: tensor([[6., 5., 6., 6.], [6., 5., 6., 6.], [6., 5., 6., 6.], [6., 5., 6., 6.]])即每个元素都加上了5,得到了一个新的张量。注意,原地操作会直接修改原始张量,而不会创建新的张量对象。因此,在第二次打印输出中,你将看到修改后的张量 tensor 的值。 四、Tensor 转换为 Numpt 数组 t = torch.ones(5) print(f"t: {t}") n = t.numpy() print(f"n: {n}")运行结果如下: • 首先,通过 torch.ones(5) 创建了一个形状为 (5,) 的张量 t,其中所有元素的值都为1。然后使用 print() 函数打印输出了张量 t 的值。 • 接下来,使用 t.numpy() 将张量 t 转换为 NumPy 数组。这里使用了 .numpy() 方法,它可以将 PyTorch 张量转换为对应的 NumPy 数组。将转换后的数组赋值给变量 n。 • 最后,使用 print() 函数分别打印输出了原始的张量 t 和转换后的 NumPy 数组 n。 通过执行这段代码,你会看到两个输出结果。第一个输出是张量 t 的值,它是一个 PyTorch 张量。第二个输出是转换后的 NumPy 数组 n 的值,它是一个 NumPy 数组对象。 例如,如果初始时张量 t 的值为: t: tensor([1., 1., 1., 1., 1.])转换后的 NumPy 数组 n 将是: n: [1. 1. 1. 1. 1.]转换后的数组 n 与原始张量 t 具有相同的数值,但它们的类型不同。t 是 PyTorch 张量,而 n 是 NumPy 数组。 t.add_(1) print(f"t: {t}") print(f"n: {n}")运行结果如下: • 首先,使用 t.add_(1) 进行原地加法操作,将张量 t 的每个元素都加上了1。这里使用了 _ 后缀的原地版本 add_(),表示直接在原始张量上进行修改。 • 接下来,分别使用 print() 函数打印输出了修改后的张量 t 和转换后的 NumPy 数组 n 的值。 通过执行这段代码,你会看到两个输出结果。第一个输出是修改后的张量 t 的值,第二个输出是转换后的 NumPy 数组 n 的值。 例如,假设在初始时,张量 t 的值为: t: tensor([1., 1., 1., 1., 1.])经过原地加法操作后,张量 t 的值将变为: t: tensor([2., 2., 2., 2., 2.])转换后的 NumPy 数组 n 的值将保持与原始张量 t 的值相同,即: n: [2. 2. 2. 2. 2.]可以看到,原地操作 t.add_(1) 修改了原始张量 t 的值,并且转换后的 NumPy 数组 n 也反映了这个修改,它们保持同步。这是因为 n 是 t 的一个视图,即 n 和 t 共享相同的底层数据存储。因此,对原始张量的修改也会反映在转换后的 NumPy 数组上。 五、Numpy数组转换为Tensor n = np.ones(5) t = torch.from_numpy(n)这段代码展示了如何将 NumPy 数组转换为 PyTorch 张量: • 首先,通过 np.ones(5) 创建了一个值全为1的长度为5的 NumPy 数组 n。然后,使用 torch.from_numpy(n) 将 NumPy 数组 n 转换为 PyTorch 张量。这个操作使用了 torch.from_numpy() 函数。然后将转换后的张量赋值给变量 t。 通过执行这段代码,你会得到一个名为 t 的 PyTorch 张量,它与原始的 NumPy 数组 n 具有相同的数值。 请注意,转换后的张量 t 和原始的 NumPy 数组 n 共享相同的底层数据存储。这意味着对张量 t 或原始数组 n 的修改都会反映在另一个对象上。 例如,如果初始时,NumPy 数组 n 的值为: [1. 1. 1. 1. 1.]那么转换后的 PyTorch 张量 t 也将具有相同的值: tensor([1., 1., 1., 1., 1.])转换后的张量 t 是一个 PyTorch 张量对象,你可以对其应用 PyTorch 提供的各种操作和方法。 NumPy数组的变化反映在tensor中 np.add(n, 1, out=n) print(f"t: {t}") print(f"n: {n}")运行结果如下: • 首先,使用 np.add(n, 1, out=n) 进行原地加法操作,将 NumPy 数组 n 的每个元素都加上了1。这里使用了 np.add() 函数,并指定了 out=n 参数,表示将结果保存在原始的 NumPy 数组 n 中进行原地修改。 • 接下来,分别使用 print() 函数打印输出了转换后的 PyTorch 张量 t 和原始 NumPy 数组 n 的值。 通过执行这段代码,你会看到两个输出结果。第一个输出是转换后的 PyTorch 张量 t 的值,第二个输出是原始的 NumPy 数组 n 的值。 例如,假设在初始时,原始的 NumPy 数组 n 的值为: n: [1. 1. 1. 1. 1.]经过原地加法操作后,原始的 NumPy 数组 n 的值将变为: n: [2. 2. 2. 2. 2.]转换后的 PyTorch 张量 t 的值也将反映这个修改: t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)可以看到,原地操作 np.add(n, 1, out=n) 修改了原始的 NumPy 数组 n 的值,并且转换后的 PyTorch 张量 t 也反映了这个修改,它们保持同步。这是因为转换后的张量 t 和原始数组 n 共享相同的底层数据存储。因此,对原始数组的修改也会反映在转换后的 PyTorch 张量上。 |


 这段代码创建了一个形状为 (3, 4) 的随机张量 tensor: 首先,使用 torch.rand() 函数创建了一个形状为 (3, 4) 的张量 tensor,其中的元素值是从均匀分布中随机采样得到的。 接着,通过使用 print() 函数结合 f-string,打印输出了一些关于 tensor 的属性信息:
这段代码创建了一个形状为 (3, 4) 的随机张量 tensor: 首先,使用 torch.rand() 函数创建了一个形状为 (3, 4) 的张量 tensor,其中的元素值是从均匀分布中随机采样得到的。 接着,通过使用 print() 函数结合 f-string,打印输出了一些关于 tensor 的属性信息: 这段代码创建了一个形状为 (4, 4) 的张量 tensor,其中所有的元素都被初始化为1。 接着,使用索引操作对 tensor 进行修改。tensor[:,1] 表示选取所有行(:)和索引为1的列,然后将这些元素的值设为0。 通过执行这段代码,你会看到输出结果中的 tensor 打印出来。其中,所有行的第二列元素(索引为1的列)的值都被修改为0,而其他列的元素值保持不变。这是由于索引操作 tensor[:,1] = 0 的作用。
这段代码创建了一个形状为 (4, 4) 的张量 tensor,其中所有的元素都被初始化为1。 接着,使用索引操作对 tensor 进行修改。tensor[:,1] 表示选取所有行(:)和索引为1的列,然后将这些元素的值设为0。 通过执行这段代码,你会看到输出结果中的 tensor 打印出来。其中,所有行的第二列元素(索引为1的列)的值都被修改为0,而其他列的元素值保持不变。这是由于索引操作 tensor[:,1] = 0 的作用。 这段代码使用 torch.cat() 函数将张量 tensor 沿着列维度(dim=1)进行拼接操作,得到一个新的张量 t1:
这段代码使用 torch.cat() 函数将张量 tensor 沿着列维度(dim=1)进行拼接操作,得到一个新的张量 t1:
 这段代码演示了两种计算张量之间的矩阵乘法的方法:
这段代码演示了两种计算张量之间的矩阵乘法的方法: 这段代码展示了张量 tensor 的原地(in-place)加法操作:
这段代码展示了张量 tensor 的原地(in-place)加法操作: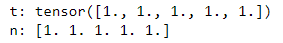 这段代码展示了如何将 PyTorch 张量转换为 NumPy 数组:
这段代码展示了如何将 PyTorch 张量转换为 NumPy 数组: 这段代码展示了在原地修改张量后,原始张量和转换后的 NumPy 数组的值的变化:
这段代码展示了在原地修改张量后,原始张量和转换后的 NumPy 数组的值的变化: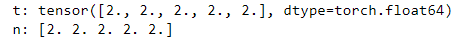 这段代码展示了在原地修改 NumPy 数组后,转换后的 PyTorch 张量和原始 NumPy 数组的值的变化:
这段代码展示了在原地修改 NumPy 数组后,转换后的 PyTorch 张量和原始 NumPy 数组的值的变化:【本文地址】