| Attention 注意力机制流程框图 | 您所在的位置:网站首页 › no作用机制流程图 › Attention 注意力机制流程框图 |
Attention 注意力机制流程框图
|
借助Attention机制提高神经网络对于信息处理能力 Attention 机制主要分为两部分 第一部分:self-attention (提高注意力方式),第二部分:transformer(定义encode-decode 过程) 如下所示: Attention机制实质寻址过后过程 给定一个查询向量Q,通过计算与Key的注意力并附加到value,得到Attention Value 优点: 不需要计算所有的N的输入信息到神经网络中进行计算,从X中选择一些与任务相关信息输入到神经网络中 信息输入 计算注意力分布A,A = Softmax(s(key,q)) 根据注意力分布A来计算信息加权平均 Attention 机制 在 RNN,CNN 解决输入序列长距离依赖问题传统的神经网络中,想要建立输入序列之间长距离依赖 使用两种方法: 第一种方法增加网络层数,利用深层神经网络远距离信息交互; 第二中方式:使用权连接网络(无法处理变长序列,不同输入长度,连接权重大小相同) 采用 Self-Attetntion 动态生成不用连接权重,从而处理变长信息序列。 Attention 机制函数计算原理:
|
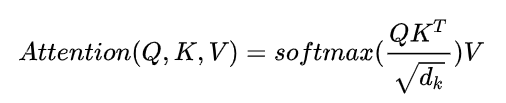 Q 表示Query,k(Key), V(Value) , key == value 普通模型, Key!= Value 键值对的模型 4. Q与K dot 点乘,防止结果过大 会除以一个尺度标度 d k \sqrt{d_k} dk
, d k d_k dk 为query和key 向量维度 5. 利用Softmax 将结果归一化成概率分布 6. 乘以矩阵V 得到权重求和
Q 表示Query,k(Key), V(Value) , key == value 普通模型, Key!= Value 键值对的模型 4. Q与K dot 点乘,防止结果过大 会除以一个尺度标度 d k \sqrt{d_k} dk
, d k d_k dk 为query和key 向量维度 5. 利用Softmax 将结果归一化成概率分布 6. 乘以矩阵V 得到权重求和【本文地址】
公司简介
联系我们