| Python抓取动态网页数据基础知识(附:爬取NBA球员例子) | 您所在的位置:网站首页 › nba官网数据 › Python抓取动态网页数据基础知识(附:爬取NBA球员例子) |
Python抓取动态网页数据基础知识(附:爬取NBA球员例子)
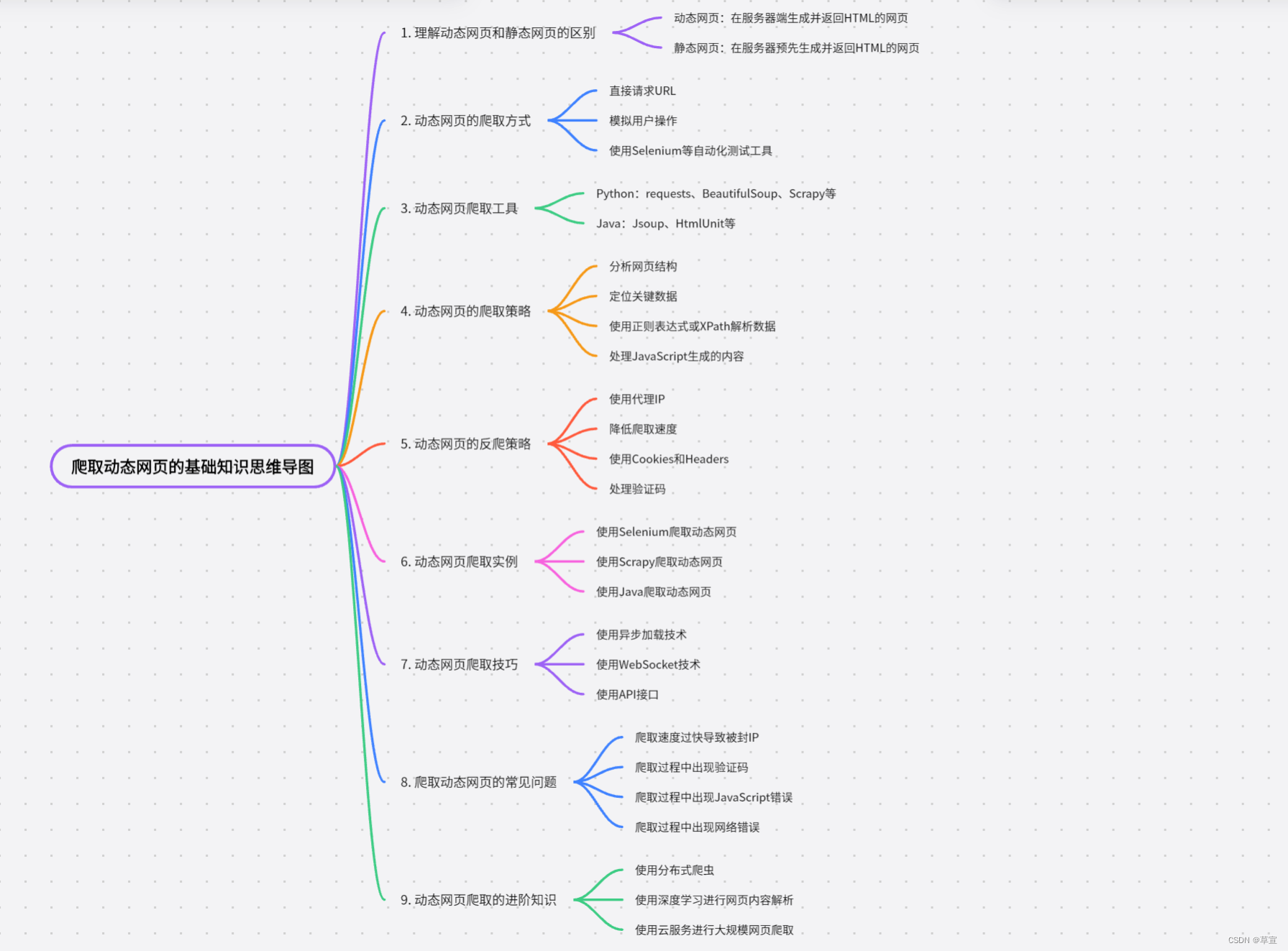 一、基础知识
一、基础知识
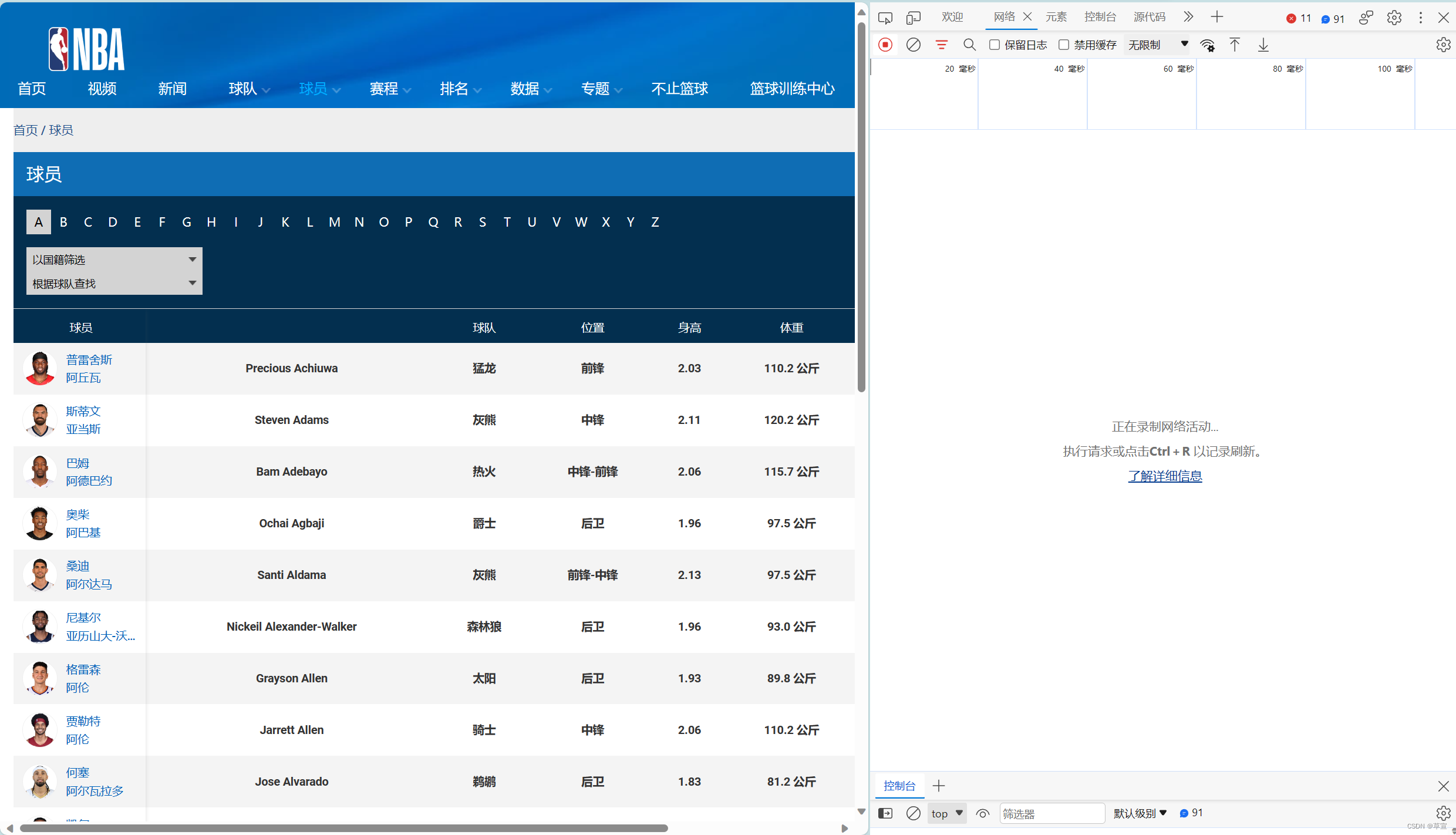
抓取动态网页数据是指从使用 JavaScript 或其他前端技术生成内容的网页中提取数据。相比于静态网页,动态网页的内容是通过 JavaScript 在客户端动态生成的,因此传统的静态网页抓取方法可能无法获取到动态生成的数据。 1.理解动态网页:动态网页是指使用 JavaScript 或其他前端技术在客户端生成内容的网页。这些技术可以通过 AJAX 请求从服务器获取数据,并使用 JavaScript 动态更新网页内容。 2.分析网页结构:在抓取动态网页数据之前,需要仔细分析网页的结构和行为。了解网页中使用的 JavaScript、AJAX 请求和数据渲染方式,以及数据所在的位置。 3.使用开发者工具:现代浏览器提供了开发者工具,可以帮助我们分析网页的结构和行为。通过查看网络请求、元素检查器和控制台等功能,可以获取有关网页加载和数据请求的详细信息。 4.模拟请求:了解网页中的数据请求方式(如 AJAX 请求),可以使用编程语言中的相应库来模拟这些请求,并获取返回的数据。通常,可以通过分析网络请求的 URL、请求方法、请求头和请求体等信息来模拟请求。 5.处理动态渲染:有些动态网页使用 JavaScript 在客户端动态渲染内容。在这种情况下,传统的静态网页抓取方法可能无法获取到完整的数据。可以使用无头浏览器(Headless Browser)来模拟浏览器行为,执行 JavaScript 并获取完整的渲染后的页面内容。 6.数据提取与解析:一旦获取到动态网页的内容,可以使用相应的数据提取和解析技术来从中提取所需的数据。可以使用正则表达式、XPath、CSS 选择器等方法来定位和提取数据。 二、爬取NBA球员数据并存入数据库 1.网址所爬取网页的网址: NBA中国官方网站 | 球员 因为传统的静态网页抓取方法可能无法获取到动态生成的数据,所以基础URL就不顶事了,经过分析的动态内容URL才是我们要的结果。 点击进入上面网页,按F12或右键检查进入以下界面并刷新。
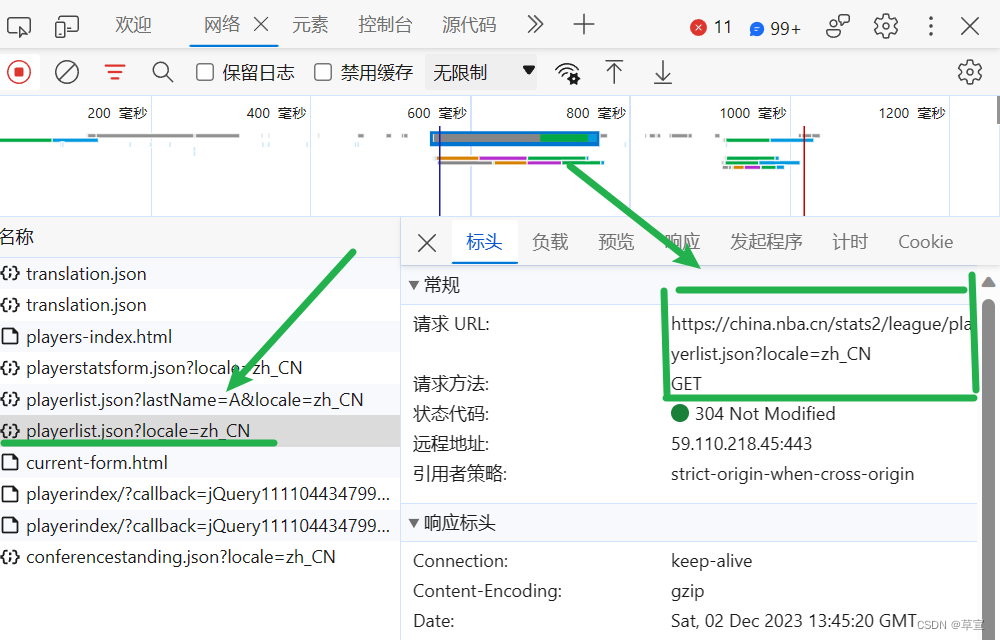
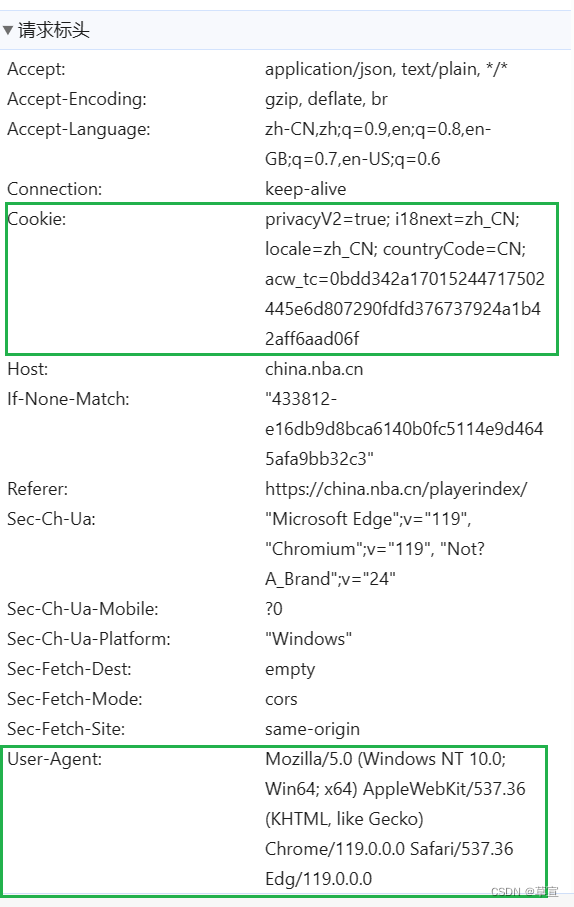
绿色横线的地方即是我们要寻找的json文件,绿色方框是我们所需要的URL。 2.发送HTTP请求使用Python中的requests库或类似的工具,发送HTTP请求来获取API的数据。你需要提供API的URL,可能还需要一些参数,例如身份验证令牌或查询参数。 import requests from pymongo import MongoClient url = "https://china.nba.cn/stats2/league/playerlist.json?locale=zh_CN" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36', 'Cookie': 'bid=hCw6GK7T3ko; _pk_id.100001.4cf6=e05499d4844cbfde.1697382901.; __yadk_uid=Y0K7d13OW6bvDo7Rfg4GEhEopPLKv9Vk; ll="118303"; _vwo_uuid_v2=D116B2284E0415DE6F0E8E62C0F3F1B7C|dbd80bec580d442e73cbc806b51e709a; ct=y; douban-fav-remind=1; __utmc=30149280; __utmz=30149280.1698504570.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=223695111; __utmz=223695111.1698504570.7.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1698504600; Hm_lpvt_16a14f3002af32bf3a75dfe352478639=1698504600; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1698558921%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DxUZ2pFPHLGI9UjAZ5BVOkGTqzr9mirz0hM9tSnQ4LgGBvkpYQRkEaveglj68M1Hs%26wd%3D%26eqid%3Dbd0c500a000673f800000006653d1f77%22%5D; __utma=30149280.1569954803.1697382901.1698557082.1698558922.11; __utma=223695111.1379090793.1697382901.1698557082.1698558922.10' }
如图所示,每台电脑不太一样。 3.解析JSON数据 result=requests.get(url,headers=headers) print(result.text) result=result.json()一旦你收到API的响应,它通常会以JSON格式返回数据。使用JSON解析库(如Python的json模块)将JSON数据解析为Python对象,以便进一步处理和提取数据。 4.提取和处理数据根据API返回的数据结构,提取需要的球员信息。这可能涉及到遍历嵌套的JSON对象或数组,并使用合适的键或索引来访问所需的数据。 首先,我们运行上面的代码得到以下内容:
或者双击:
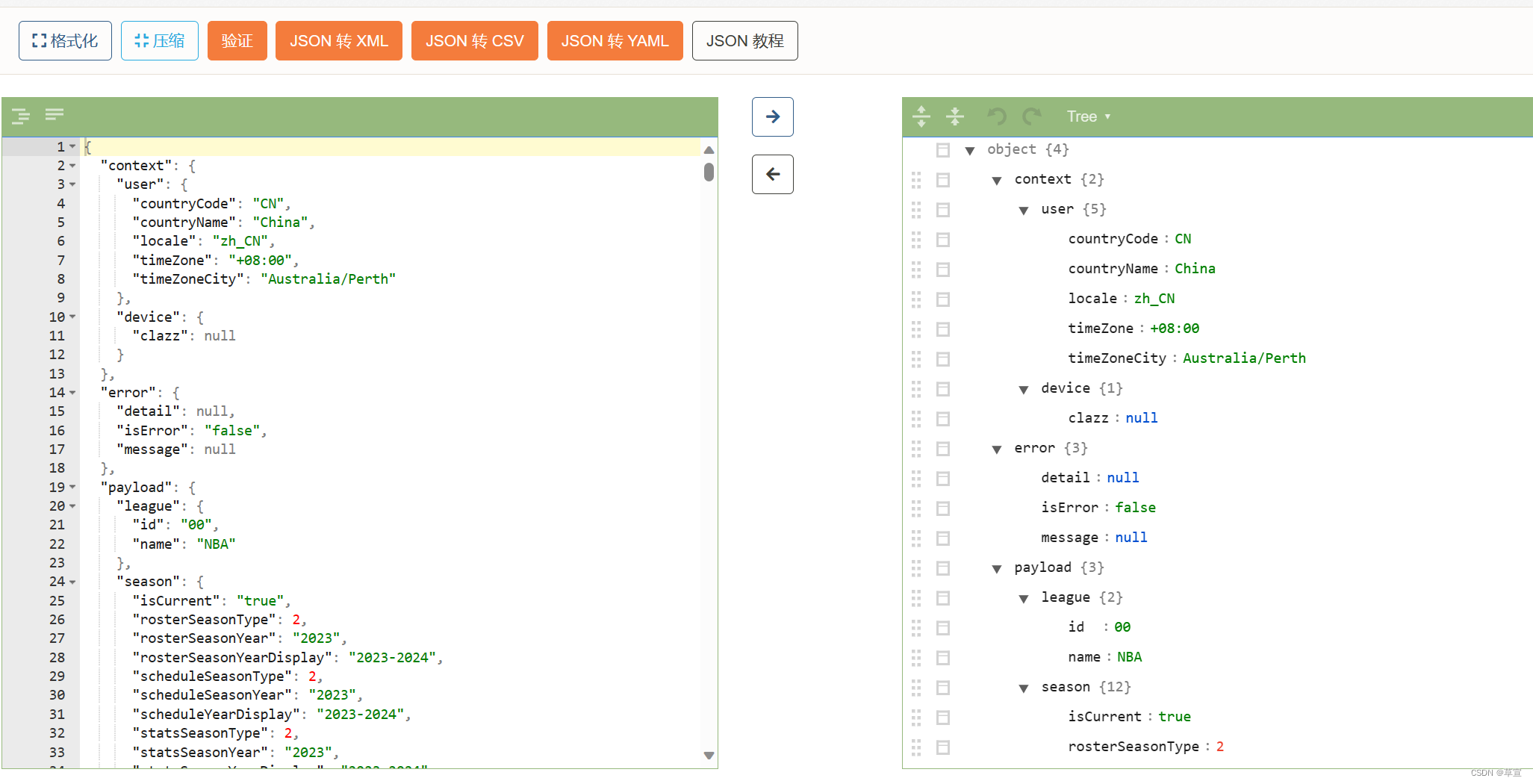
会得到很长一串代码,全部复制,接着将它复制到菜鸟的json格式化工具,将其解析 JSON 在线解析 | 菜鸟工具 (runoob.com) 就可以得到:
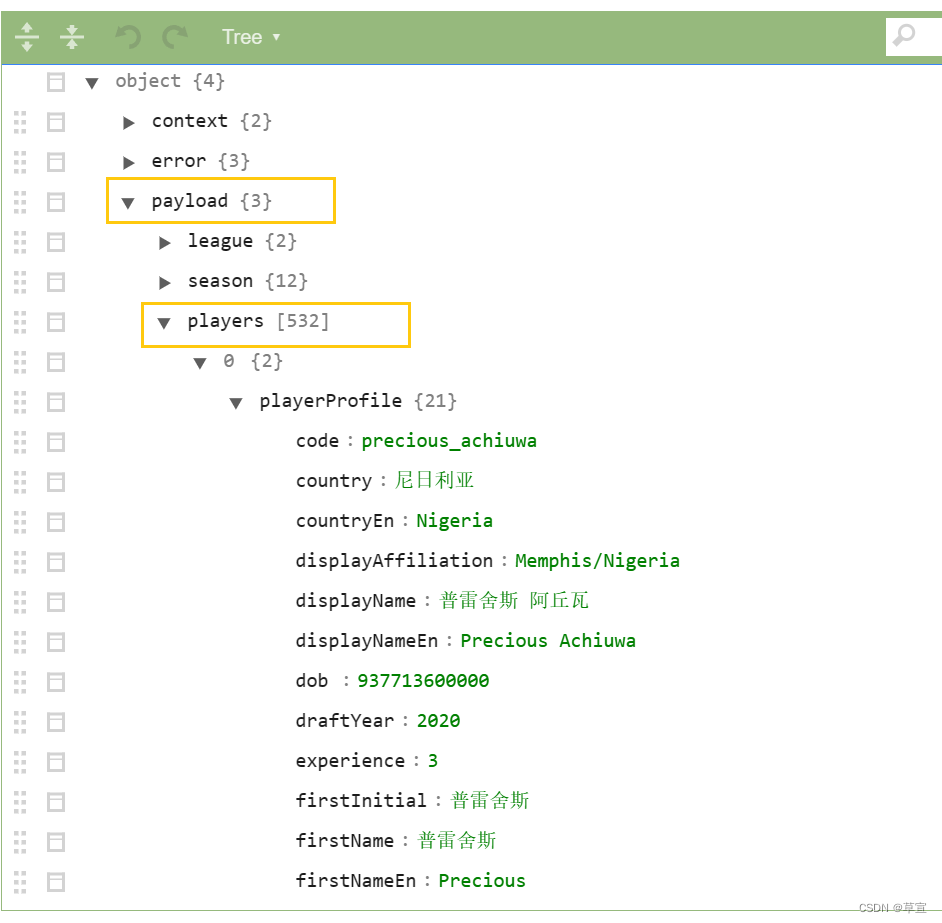
这时,我们将不需要的数据折叠起来,就可以发现我们所需要的数据在payload和players里,这也是我们构建循环所需要的键。
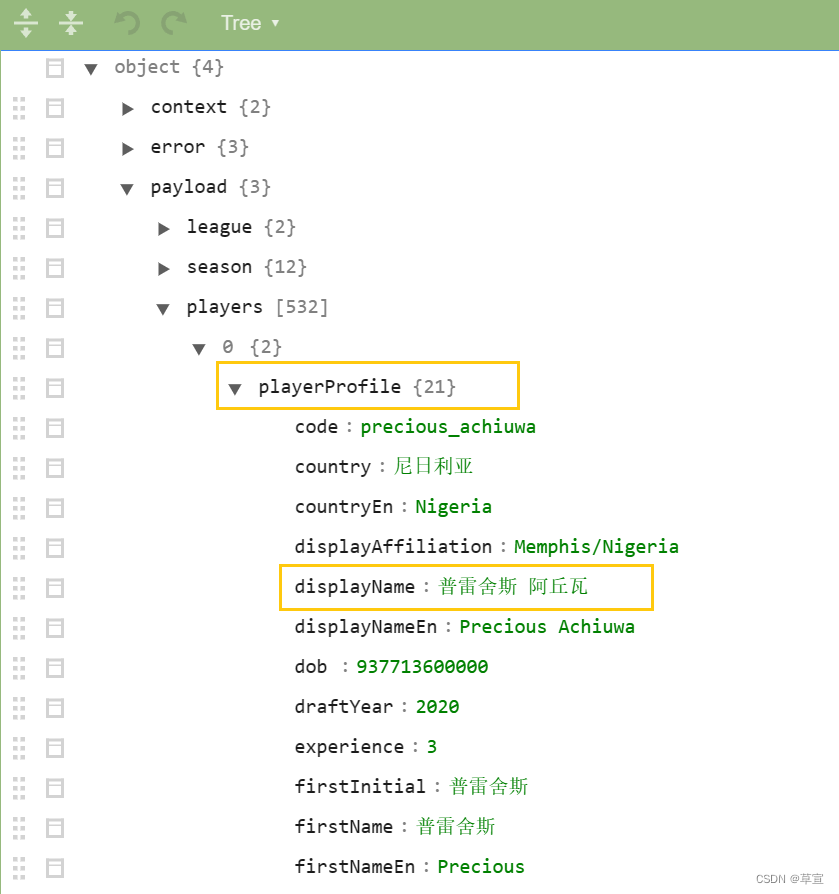
接着我们找球员的名字,它在playerProfile里的displayName中。
结合上面我们可以得到循环 result_json=result["payload"]["players"] for i in result_json: name=i["playerProfile"]["displayName"]球员、位置等信息的寻找同理,则可以得到: result_json=result["payload"]["players"]#构建循环的键 ps=[] for i in result_json:#找所需要的内容 name=i["playerProfile"]["displayName"] tearm=i["teamProfile"]["displayAbbr"] position=i["playerProfile"]["position"] height=i["playerProfile"]["height"] weight = i["playerProfile"]["weight"] experience=i["playerProfile"]["experience"] country=i["playerProfile"]["country"] p={ "name":name, "tearm":tearm, "position":position, "height":height, "experience":experience, "country":country } ps.append(p)p用于存储每个球员的相关信息。在每次循环迭代中,通过从result_json中提取相应的字段,将球员的姓名、球队、位置、身高、体重、经验和国籍等信息存储在字典p中。接下来,p字典被添加到列表ps中,以便在循环结束后,可以将所有球员的信息存储在列表中。最终,列表ps将包含所有球员的信息,可以根据需要进一步处理和使用这些数据。 5.存储数据 client=MongoClient("localhost",27017) datebase=client["db_nba"] collections=datebase['nba_players'] collections.insert_many(ps) query=collections.find({}) for doc in query: print(doc)首先,使用MongoClient对象连接到本地MongoDB数据库,并指定主机名和端口号。接着,创建一个名为db_nba的数据库,并将其赋值给datebase变量。然后,使用datebase['nba_players']创建了一个名为nba_players的集合(collection),并将其赋值给collections变量。 接下来,使用insert_many()方法将之前爬取到的球员信息列表ps插入到nba_players集合中。 然后,使用find({})方法查询nba_players集合中的所有文档,并将查询结果赋值给query变量。接着,使用for循环遍历query,对于每个文档(即每个球员信息),使用print(doc)打印输出。 查看数据库:
可以看见已经成功存入。 6.完整代码 import requests from pymongo import MongoClient url = "https://china.nba.cn/stats2/league/playerlist.json?locale=zh_CN" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36', 'Cookie': 'bid=hCw6GK7T3ko; _pk_id.100001.4cf6=e05499d4844cbfde.1697382901.; __yadk_uid=Y0K7d13OW6bvDo7Rfg4GEhEopPLKv9Vk; ll="118303"; _vwo_uuid_v2=D116B2284E0415DE6F0E8E62C0F3F1B7C|dbd80bec580d442e73cbc806b51e709a; ct=y; douban-fav-remind=1; __utmc=30149280; __utmz=30149280.1698504570.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=223695111; __utmz=223695111.1698504570.7.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1698504600; Hm_lpvt_16a14f3002af32bf3a75dfe352478639=1698504600; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1698558921%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DxUZ2pFPHLGI9UjAZ5BVOkGTqzr9mirz0hM9tSnQ4LgGBvkpYQRkEaveglj68M1Hs%26wd%3D%26eqid%3Dbd0c500a000673f800000006653d1f77%22%5D; __utma=30149280.1569954803.1697382901.1698557082.1698558922.11; __utma=223695111.1379090793.1697382901.1698557082.1698558922.10' } result=requests.get(url,headers=headers) print(result.text) result=result.json() result_json=result["payload"]["players"] print(result_json) ps=[] for i in result_json: name=i["playerProfile"]["displayName"] tearm=i["teamProfile"]["displayAbbr"] position=i["playerProfile"]["position"] height=i["playerProfile"]["height"] weight = i["playerProfile"]["weight"] experience=i["playerProfile"]["experience"] country=i["playerProfile"]["country"] p={ "name":name, "tearm":tearm, "position":position, "height":height, "experience":experience, "country":country } ps.append(p) client=MongoClient("localhost",27017) datebase=client["db_nba"] collections=datebase['nba_players'] collections.insert_many(ps) query=collections.find({}) for doc in query: print(doc) 三、结尾希望可以帮到大家! |



【本文地址】