|
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦!
数据可视化(六):Pandas爬取NBA球队排名、爬取历年中国人口数据、爬取中国大学排名、爬取sina股票数据、绘制精美函数图像
目录
数据可视化(六):Pandas爬取NBA球队排名、爬取历年中国人口数据、爬取中国大学排名、爬取sina股票数据、绘制精美函数图像1. 爬取NBA球队排名页面,并进行分析2. 爬取以下网址的历年中国人口数据进行并进行分析3. 获取大学排名数据并进行分析4. 获取sina股票数据并进行分析5. matplotlib模仿绘图6. matplotlib模仿绘图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['axes.unicode_minus']=False
1. 爬取NBA球队排名页面,并进行分析
页面url https://nba.hupu.com/standings
提示:
data = pd.read_html(url, header=0) #header=0 去掉第一行列索引
# 爬取数据并将东部和西部联盟存放到df1 df2
url = "https://nba.hupu.com/standings"
data = pd.read_html(url,header=0) #header=0 去掉第一行列索引
data_merge = pd.concat([df,data[0]])
data_merge.columns = data_merge.iloc[0,:]
data_merge = data_merge.iloc[1:]
# 重置索引,不保留原索引作为新列
data_merge.reset_index(drop=True, inplace=True)

# 东部数据
df1 = data_merge.iloc[0:15,:]
df1
# 西部数据
df2 = data_merge.iloc[17:,:]
df2.reset_index(drop=True, inplace=True)
df2


# 将df1增加一列"所属联盟",赋值为"东部赛区"
df1["所属联盟"] = "东部赛区"
df1
# 将df2增加一列"所属联盟",赋值为"西部赛区"
df2["所属联盟"] = "西部赛区"
df2
# 将df1、df2合并成df
df_merge = pd.concat([df1,df2], axis = 0)
df_merge.reset_index(drop=True,inplace=True)
df_merge


# 将df数据保存为csv文件 nba.csv
df_merge.to_csv('./nba.csv', encoding='utf-8', index=False,sep=",")
# 将所有球队按照 胜率(百分比) 降序排序,排名相同的队伍按 失分 升序排名
# 提示:ascending也可以接收列表参数
df_merge.sort_values(by=["胜率","失分"],ascending=[False,True]).reset_index(drop=True)

# 对df按“所属联盟”分组,计算胜、负、胜率的最大值、最小值、均值、标准差
# 注意:百分比不是数值,要转换成小数
# 转换数值类型
df_merge["胜"] = df_merge["胜"].astype(int)
df_merge["负"] = df_merge["负"].astype(int)
# 将百分比字符串转换为小数
df_merge['胜率'] = df_merge['胜率'].str.replace('%', '').astype(float) / 100
df_merge.head()
df_grouped = df_merge.groupby(by='所属联盟').agg(
{
'胜': ['max', 'min', 'mean', 'std'],
'负': ['max', 'min', 'mean', 'std'],
'胜率': ['max', 'min', 'mean', 'std']
})


# 柱状图显示东西赛区的胜率(百分比)均值
# 提取胜率均值列,并重置列名以简化后续操作
df_grouped_win_rate_mean = df_grouped['胜率']['mean'].reset_index()
df_grouped_win_rate_mean.columns = ['所属联盟', '胜率均值']
df_grouped_win_rate_mean
# 将胜率均值转换为百分比
df_grouped_win_rate_mean['胜率均值_百分比'] = df_grouped_win_rate_mean['胜率均值'] * 100
df_grouped_win_rate_mean
# 绘制柱状图
plt.figure(figsize=(10, 6)) # 设置图形大小
bars = plt.bar(df_grouped_win_rate_mean['所属联盟'], df_grouped_win_rate_mean['胜率均值_百分比'])
# 设置数据标签
def format_percent(x):
return "{:.2%}".format(x / 100)
# 添加百分比形式的数据标签
for rect in bars:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, format_percent(height),
ha='center', va='bottom')
plt.xlabel('所属联盟') # 设置x轴标签
plt.ylabel('胜率均值') # 设置y轴标签
plt.title('东西赛区胜率均值比较') # 设置图形标题
plt.xticks(rotation=0) # 设置x轴刻度标签的旋转角度为0
plt.tight_layout() # 调整布局
plt.ylabel('胜率均值 (%)') # 将y轴标签更改为百分比形式
plt.show() # 显示图形

2. 爬取以下网址的历年中国人口数据进行并进行分析
url = ‘https://population.gotohui.com/’
# 爬取数据并存放到df,并将df保存为population.csv
url = 'https://population.gotohui.com/'
data = pd.read_html(url,header=0) #header=0 去掉第一行列索引
df = data[0]
df.to_csv("./population.csv", encoding='utf-8', index=False,sep=",")

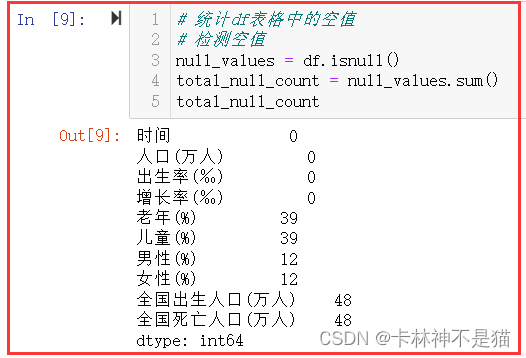
# 统计df表格中的空值
# 检测空值
null_values = df.isnull()
total_null_count = null_values.sum()
total_null_count
# 将空值的列'老年人(%)'、'儿童(%)'中数据用前值替换;'男性(%)'、'女性(%)'用均值替换
# 使用前一个非空值替换 '老年人(%)' 和 '儿童(%)' 列中的空值
df['老年(%)'].fillna(method='ffill', inplace=True)
df['儿童(%)'].fillna(method='ffill', inplace=True)
# 计算 '男性(%)' 和 '女性(%)' 列的均值,并替换这些列中的空值
mean_male = df['男性(%)'].mean()
mean_female = df['女性(%)'].mean()
df['男性(%)'].fillna(mean_male, inplace=True)
df['女性(%)'].fillna(mean_female, inplace=True)
df

# 将除了 时间(年) 列外所有的列的数据改成保留小数点后2位小数
# 提示:采用lambda函数和applymap函数
# 保留除了'时间'字段之外的列的小数点后两位
columns_to_round = ['人口(万人)', '出生率(‰)', '增长率(‰)', '老年(%)', '儿童(%)', '男性(%)', '女性(%)']
df[columns_to_round] = df[columns_to_round].apply(lambda x: x.round(2))
# 查看格式化后的输出,可以设置显示选项 (空值输出时浮点数格式)
pd.options.display.float_format = '{:.2f}'.format
# 显示修改后的DataFrame
df.head()

# 在同一张表上绘制历年人口出生率和增长率曲线
# 确保'时间'列是日期类型,这样可以按时间顺序绘制曲线
df['时间'] = pd.to_datetime(df['时间'], format='%Y') # 假设时间格式为'年'
# 绘制出生率曲线
plt.plot(df['时间'], df['出生率(‰)'], label='出生率(‰)', marker='o')
# 绘制增长率曲线
plt.plot(df['时间'], df['增长率(‰)'], label='增长率(‰)', marker='o', linestyle='--')
# 设置图表标题和坐标轴标签
plt.title('历年人口出生率和增长率曲线')
plt.xlabel('时间')
plt.ylabel('比率')
# 显示图例
plt.legend()
# 显示网格
plt.grid(True)
# 格式化x轴以显示年份
plt.gcf().autofmt_xdate()
# 显示图表
plt.show()

# 绘制男女比率差绝对值的曲线图
# 计算男女比率差的绝对值
df['比率差绝对值'] = abs(df['男性(%)'] - df['女性(%)'])
df
# 绘制男女比率差绝对值的曲线图
plt.plot(df['时间'], df['比率差绝对值'], marker='o')
# 设置图表标题和坐标轴标签
plt.title('男女比率差绝对值曲线图')
plt.xlabel('时间')
plt.ylabel('比率差绝对值')
# 显示网格
plt.grid(True)
# 显示图表
plt.show()

# 在一个画布的四个子画布上(两行两列)分别画出:
# 1、近十年老人、儿童、其它(100减去老人、儿童占比)人群比率均值的柱状比较图
# 2、近五年男性、女性比率的柱状比较图
# 3、近十年人口增增长率和出生率的水平柱状图
# 4、2022年老人、儿童、其它的饼图
import matplotlib.pyplot as plt
import pandas as pd
# 假设df_1, df_2, df_3, df_4已经定义好,并且包含了需要绘制的数据
# 创建一个2x2的画布和子图
fig, axs = plt.subplots(2, 2, figsize=(12, 8))
# 第一幅图:近十年老人、儿童、其它人群比率均值的柱状比较图
bars = axs[0, 0].bar(df_1.columns, df_1.iloc[0])
bar_width = 0.35
axs[0, 0].set_title('近十年老人、儿童、其它人群比率均值的柱状比较图')
axs[0, 0].set_xlabel('人群')
axs[0, 0].set_ylabel('比率均值(%)')
for bar in bars:
height = bar.get_height()
axs[0, 0].text(bar.get_x() + bar_width / 2, height, '{:.2f}'.format(height), ha='center', va='bottom')
# 第二幅图:近五年男性和女性比例的柱状比较图
df_2 = df_2.sort_values(by='时间')
bar_width = 0.35
index_male = range(len(df_2))
index_female = [i + bar_width for i in index_male]
axs[0, 1].bar(index_male, df_2['男性(%)'], bar_width, label='男性比例')
axs[0, 1].bar(index_female, df_2['女性(%)'], bar_width, label='女性比例')
# 设置x轴的标签位置为index_male的中间位置,并且标签内容为df_2['时间']的值
tick_positions = [i + bar_width / 2 for i in index_male]
axs[0, 1].set_xticks(tick_positions)
axs[0, 1].set_xticklabels(df_2['时间']) # 设置x轴的标签内容
# 设置x轴刻度标签的旋转角度
axs[0, 1].tick_params(axis='x', rotation=45) # 旋转x轴刻度标签
axs[0, 1].set_title('近五年男性和女性比例的柱状比较图')
axs[0, 1].set_xlabel('年份')
axs[0, 1].set_ylabel('比例(%)')
axs[0, 1].legend()
# 第三幅图:近十年人口增长率和出生率水平柱状图
axs[1, 0].barh(df_3['时间'], df_3['增长率(‰)'], label='增长率', color='skyblue')
axs[1, 0].barh(df_3['时间'], df_3['出生率(‰)'], left=df_3['增长率(‰)'], label='出生率', color='lightcoral')
axs[1, 0].set_title('近十年人口增长率和出生率水平柱状图')
axs[1, 0].set_xlabel('千分比')
axs[1, 0].set_ylabel('年份')
axs[1, 0].legend()
axs[1, 0].grid(axis='x', alpha=0.75)
# 第四幅图:2022年老人、儿童、其他人群分布的饼图
labels = df_4.columns
sizes = df_4.iloc[0]
axs[1, 1].pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
axs[1, 1].axis('equal')
axs[1, 1].set_title('2022年老人、儿童、其他人群分布')
# 调整子图间距
plt.tight_layout()
# 显示整个画布
plt.show()

# 在同一幅图上画出'出生率(‰)', '增长率(‰)'箱线图。
import seaborn as sns
import matplotlib.pyplot as plt
# 设置图形大小
plt.figure(figsize=(10, 6))
# 绘制箱线图
sns.boxplot(data=df[['出生率(‰)', '增长率(‰)']])
# 设置标题和轴标签
plt.title('出生率和增长率的箱线图')
plt.xlabel('指标')
plt.ylabel('值 (‰)')
# 显示图形
plt.show()

# 利用散点图寻找 ‘增长率(‰)’ 异常值的年份,即寻找增长率背离正常变化范围的年份。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 计算增长率的四分位数
Q1 = df_6['增长率(‰)'].quantile(0.25)
Q3 = df_6['增长率(‰)'].quantile(0.75)
# 定义正常值范围,这里使用0.8倍IQR作为异常值的界限
lower_bound = Q1 - 0.8 * IQR
upper_bound = Q3 + 0.8 * IQR
# 识别异常值
outliers = df_6[(df_6['增长率(‰)'] upper_bound)]
# 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(df_6['时间'], df_6['增长率(‰)'], color='blue', label='正常值')
# 在图上标注异常值
plt.scatter(outliers['时间'], outliers['增长率(‰)'], color='red', label='异常值')
for index, row in outliers.iterrows():
plt.annotate(f'({row["时间"]}, {row["增长率(‰)"]})', (row['时间'], row['增长率(‰)']))
# 设置标题和轴标签
plt.title('增长率随时间变化的散点图及异常值标注')
plt.xlabel('时间')
plt.ylabel('增长率(‰)')
# 显示图例
plt.legend()
# 显示网格线
plt.grid(True)
# 显示图形
plt.show()

# 利用正态分布方法(类似3𝜎方法,采用1.5𝜎)找出增长率异常值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 计算增长率的均值和标准差
mean_growth_rate = df_7['增长率(‰)'].mean()
std_growth_rate = df_7['增长率(‰)'].std()
# 设定异常值的阈值,这里使用1.5倍标准差
threshold = mean_growth_rate + 1.5 * std_growth_rate
# 对于低于均值的异常值,使用负的1.5倍标准差
lower_threshold = mean_growth_rate - 1.5 * std_growth_rate
# 识别异常值
outliers_upper = df_7[df_7['增长率(‰)'] > threshold]
outliers_lower = df_7[df_7['增长率(‰)'] |