| MySql数据结构以及时间复杂度 | 您所在的位置:网站首页 › mysql根据索引查询数据 › MySql数据结构以及时间复杂度 |
MySql数据结构以及时间复杂度
|
MySql数据结构以及时间复杂度
1.数据结构分类1.1.数据结构分类
2.时间复杂度3.算法3.1.算法的时间和空间复杂度
4.空间复杂度5.关于时间复杂度得出的结果6.普通二叉树6.1.检索原理6.2.问题
7.AVL平衡二叉树8.BTree索引8.1.【B树的介绍】8.2.【检索原理图】
9.B+Tree索引9.1.【B+树的介绍】9.2.【检索原理图】9.3.【BTree和B+Tree比较】
1.数据结构分类
1.1.数据结构分类
数据结构有很多种,一般来说,按照数据的逻辑结构对其进行简单的分类,包括线性结构和非线性结构两类。 线性结构: •线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。 •线性结构有两种不同的存储结构,即顺序存储结构和链式存储结构。 ◦顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的 ◦链式存储的线性表称为链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息 •线性结构常见的有:数组、链表、队列和栈。
同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在于选择合适算法和改进算法。 http://www.99cankao.com/algebra/log2.php常见的算法时间复杂度由小到大依次为:O—理解为一个函数 Ο(1)<Ο(log2N)<Ο(n)<Ο(nlog2N)<Ο(n2)<Ο(n3)< Ο(n^k) <Ο(2^n)
算法:解决问题的方案 3.1.算法的时间和空间复杂度时间复杂度:是指执行算法所需要的基本运算次数。 空间复杂度:是指执行算法所需要的内存空间。 4.空间复杂度•类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模n的函数。 •空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元。 •在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间。 5.关于时间复杂度得出的结果加速查找速度的数据结构,常见的有两类: (1)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1); (2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(log2N); 可以看到,不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些, 那为什么,索引结构要设计成树型呢? 索引:数据库的索引 -树! 想想范围/排序等其它SQL条件: 哈希型的索引,时间复杂度会退化为O(n)而树型的“有序”特性,依然能够保持O(log2N) 的高效率。 备注:InnoDB并不支持哈希索引。 6.普通二叉树 6.1.检索原理 https://www.cs.usfca.edu/~galles/visualization/Algorithms.html二叉树的特点: 1、一个节点只能有两个子节点,也就是一个节点度不能超过2 2、左子节点 小于 本节点;右子节点大于等于 本节点,比我大的向右,比我小的向左 这种方式查找:时间复杂度会再次上升 第1种情况 如果id的值是持续递增的话,会是什么样的结构? AVL树全称G.M. Adelson-Velsky和E.M. Landis,这是两个人的人名。 在插入数据的时候会自动发生n多次旋转操作,旋转操作会消耗一定的性能!旋转的目的就是保证这个棵数的平衡。平衡二叉树要求左子树与左子树的高度差不能超过1 https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
解决问题: 我们为了减少磁盘IO的次数,就必须降低树的深度,将“瘦高”的树变得“矮胖”。 (1)每个节点存储多个元素 (2)摒弃二叉树结构,采用多叉树 红黑树: 插入顺序:2,1,4,5,3,6 B-Tree树即B树,B即Balanced,平衡的意思。 •B-Tree即B树,Balance Tree,平衡树。 •2-3树是最简单的B树结构。 •B树的阶:节点的最多子节点个数。比如2-3树的阶是3,2-3-4树的阶是4。 •B树通过重新组织节点,降低树的高度,并且减少IO读写次数来提升效率。 •关键字集合分布在整颗树中,即叶子节点和非叶子节点都存放数据。 https://www.cs.usfca.edu/~galles/visualization/BTree.html 8.2.【检索原理图】黄色:指针,存储子节点的信息地址 红色:键值,表中记录的主键 蓝色:数据,记录表中除主键外的数据 B+Tree 即B+树: •B+树是B树的升级版本,区别是所有数据只出现在叶子结点中,即叶只有叶子节点存放数据,非叶子节点只是叶子结点中数据的键值和指针。 •所有的叶子结点中包含了全部数据信息,及指向含这些数据记录的指针,叶子节点之间通过指针相连,且叶子结点本身依键值的大小自小而大顺序链接。 •由于B+树的非叶子节点不存储数据,因此每个节点可以存储更多的信息,假设每个节点能存储4个键值和指针信息,则变成B+树后其结构如下图所示:
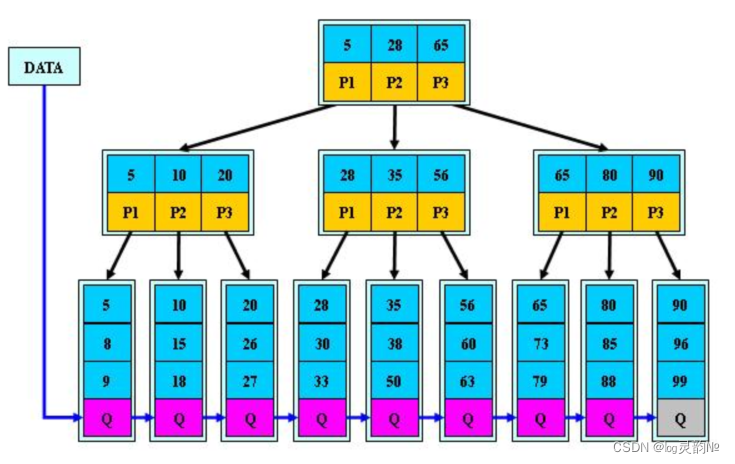
由于B+树的非叶子节点只存储键值和指针信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+树后其结构如下图所示: |
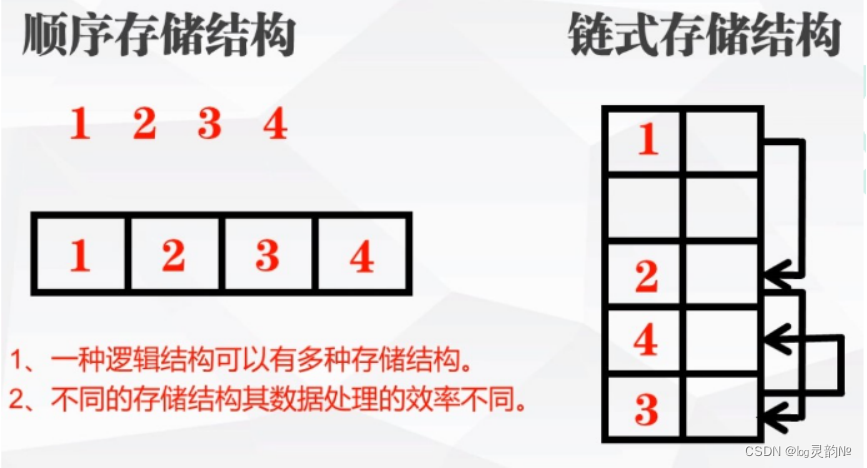 非线性结构: 非线性结构包括:二维数组,多维数组,树结构,图结构
非线性结构: 非线性结构包括:二维数组,多维数组,树结构,图结构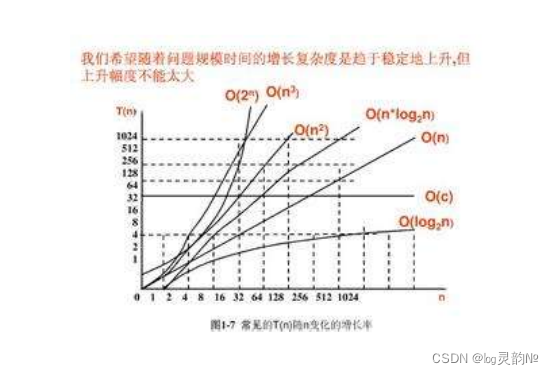
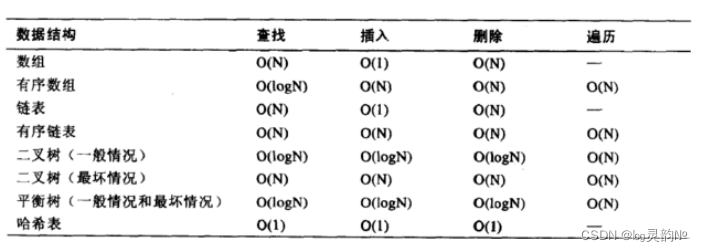 Hash 最好,次之平衡树!
Hash 最好,次之平衡树!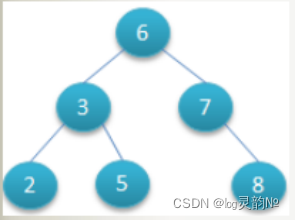
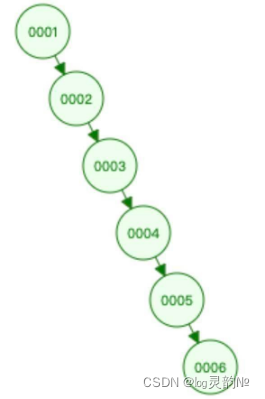 第2种情况
第2种情况 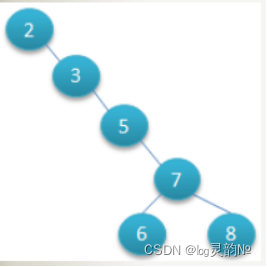
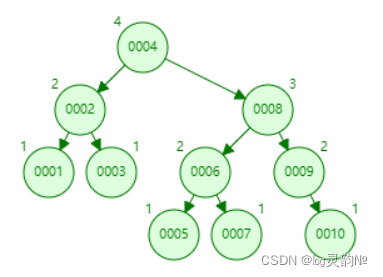 问题: 1.在构建二叉树时,需要多次进行i/o操作(海量数据存在数据库或文件中),节点海量,构建二叉树时,速度有影响。 2.节点海量,也会造成二叉树的高度很大,会降低操作速度。
问题: 1.在构建二叉树时,需要多次进行i/o操作(海量数据存在数据库或文件中),节点海量,构建二叉树时,速度有影响。 2.节点海量,也会造成二叉树的高度很大,会降低操作速度。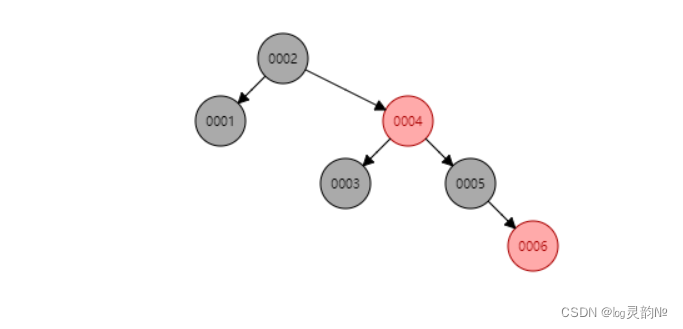 当再次插入7的时候,这棵树就会发生旋转
当再次插入7的时候,这棵树就会发生旋转  在这个棵严格的平台树上又进化为“红黑树”{是一个非严格的平台树 左子树与左子树的高度差不能超过1},红黑树的长子树只要不超过短子树的两倍即可!
在这个棵严格的平台树上又进化为“红黑树”{是一个非严格的平台树 左子树与左子树的高度差不能超过1},红黑树的长子树只要不超过短子树的两倍即可!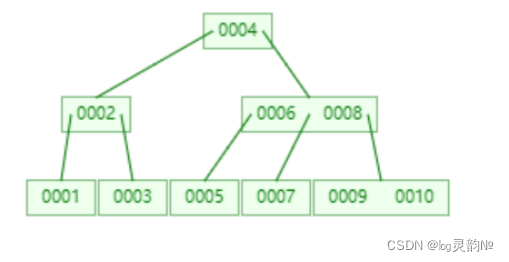
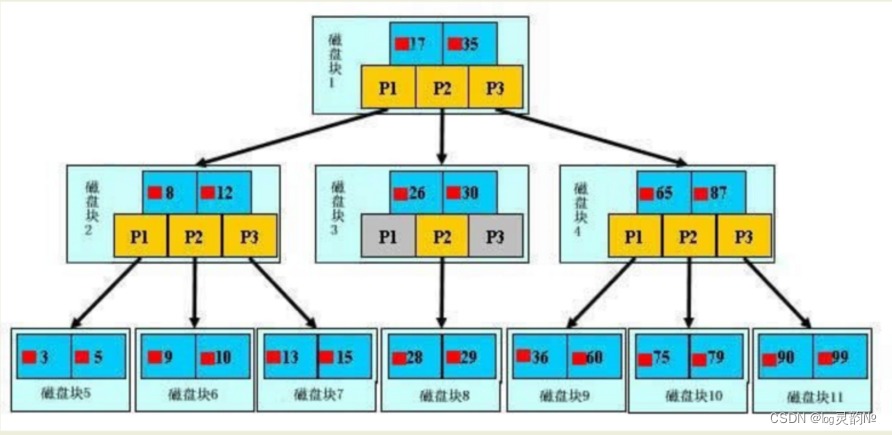 以上图为例:若查询的数值为5: 第一次磁盘IO:根据根节点找到磁盘块1,读入内存,执行二分查找,比17小,根据指针P1,找左子树; 第二次磁盘IO:找到磁盘块2,读入内存,执行二分查找,比8小,根据指针P1,找左子树; 第三次磁盘IO:找到磁盘块5,读入内存,执行二分查找,找到5,终止。 整个过程中,我们可以看出:BTree相对于平衡二叉树降低了树的高度,缩减了节点个数,减少了I/O操作,提高了查询效率 还可以优化!让每个磁盘块存储更多的指针
以上图为例:若查询的数值为5: 第一次磁盘IO:根据根节点找到磁盘块1,读入内存,执行二分查找,比17小,根据指针P1,找左子树; 第二次磁盘IO:找到磁盘块2,读入内存,执行二分查找,比8小,根据指针P1,找左子树; 第三次磁盘IO:找到磁盘块5,读入内存,执行二分查找,找到5,终止。 整个过程中,我们可以看出:BTree相对于平衡二叉树降低了树的高度,缩减了节点个数,减少了I/O操作,提高了查询效率 还可以优化!让每个磁盘块存储更多的指针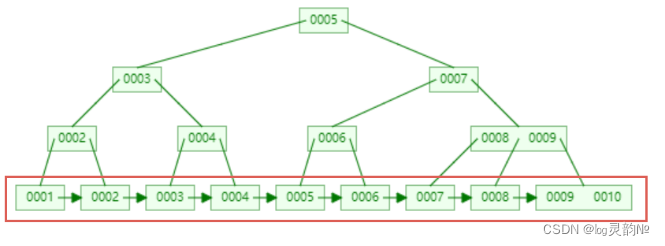
【本文地址】