| MySQL的排序和分页语句(十八) | 您所在的位置:网站首页 › mysql排序后分页 › MySQL的排序和分页语句(十八) |
MySQL的排序和分页语句(十八)
|
我看到了那天的夕阳,美得如此骄艳,我便决定,追寻夕阳,拼尽余生。 上一章简单介绍了 MySQL的分组和分组后筛选语句(十七),如果没有看过,请观看上一章 一. MySQL的排序和分页当查询数据时,可以通过 where语句和 group by+having 语句进行筛选,得到正确的数据,然而数据是正确的,但展示的时候,可能是杂乱无章的。 就像 Excel中展示数据一样,按照字母大小写的顺序,按照成绩从高到低,进行展示一样, 我们也希望定义一个规则,让筛选出来的结果按照我们自定义的规则进行展示。 排序,需要用到 order by 关键字。 当数据量过多时,我们不希望全部展示,只希望展示其中的某一个部分,即可以进行分页展示,分页需要用到 limit 关键字。 其中,排序主要分为两部分: 单字段排序多字段排序下面,对排序和分页进行详细的讲解。 仍然用的是 yuejl数据库中的 user 表。
可以看出来,是按照 id 进行从小到大的展示的。 二. 单字段排序所用命令: select 列名1,聚集函数(列) from 表名 where 条件语句 group by 分组列名1 having 分组后筛选 order by 列名1 asc|desc;其中, asc 为升序排序, desc为降序排序, 默认是升序排列 asc. 排列的字段,常常是 数字类型的,或者英文字符串类型的。 不建议使用中文,直接进行排序。 二.一 按照某一字段 进行升序排列 asc如 按照 年龄 age 进行升序排列: select * from user order by age asc;
会按照年龄,进行升序排列。 二.二 按照某一字段进行降序排列 desc如 按照部门编号 进行降序排列,先展示部门编号为3的,再展示部门编号为2的,最后展示部门编号为1的. select * from user order by deptId desc;
会按照部门编号 deptId 进行降序排列。 二.三 省略asc 或者desc, 默认升序如,还是按照年龄进行排序, 最后省略 asc, 看其默认按照什么方式排列。 select * from user order by age;
省略时,默认是按照升序进行排列的。 三. 多字段进行排序 select *|列名 from 表名 order by 列名1 asc|desc,列名2 asc|desc;其中,列名1,列名2,谁先写在前面,谁先写在后面,是有讲究的。 先按照列名1进行排序, 如果列名1相同的话,再按照列名2进行排序, 以列名1,即先写的那个为主,以列名2,即后写的那个为辅。 其中 如果是升序的话, asc同样可以省略。 三.一 多字段排序举例如 按照部门进行排序,如果部门编号相同,则按照年龄进行从大到小排列。 select * from user order by deptId,age desc;
以部门编号为主,以age为辅。 如果将age desc 放置在前面呢? select * from user order by age desc,deptId;
以age 为主,以deptId 为辅。 很明显,两者的查询结果是不一致的。 三.二 审批状态的排序处理在业务中,排序时也通常与 if()或者case() 条件函数进行连用, 来将某些特定状态的记录放置在前面。 如 将 退回状态的放置在最前面,将待审批的放置在第二,将成功的审批记录放置在最后面。 如状态 status 为: 1 待审批2 审批中3 成功4 退回可以 写类型 order by (if(status=4,0,status)) asc 或者 order by (case status when 4 then 0 else status end) asc; 提示: 可以使用不在SELECT列表中的列排序。在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。 四. 分页语句 limit分页 limit 所使用的命令是: select 列名1,聚集函数(列) from 表名 where 条件语句 group by 分组列名1 having 分组后筛选 order by 列名1 asc|desc limit [位置偏移量] 行数;其中,位置偏移量 可以省略,那么limit 就有两种写法了. 第一种: limit 行数;第二种: limit 位置偏移量,行数下面,分别对这两种情况进行分析。 按照年龄从大到小查时: select * from user order by age desc;
limit 后面只跟一个参数, 表示 从1开始查询,查询 n 条记录。 如按照年龄从大到小排序,查询4条记录。 select * from user order by age desc limit 4;
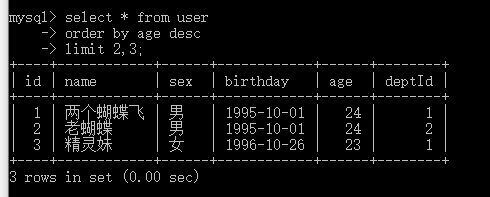
年龄从大到小,查询4条。 MySQL数据库是从1 开始的。 如果 n>=最大的记录条数, 表示全部查询, 从1开始,到最后记录结束为止。 四.二 limit m,n 情况limit 后面跟两个参数,表示从 m+1处开始查询,往后查询n 条记录。 即最后的结果位置为 (m+n). 如果m+n> 最大的记录条数, 那么从 m+1处开始查询,到最后记录结束为止。 其中 第一种情况实际上是第二种情况的一种缩写版本,为 limit 0,n. 如年龄 同样从大到小排序,查询3条记录,从位置2处开始查询。 select * from user order by age desc limit 2,3;
变成 0,n 时,看是否与第一种情况相同。 select * from user order by age desc limit 0,4;
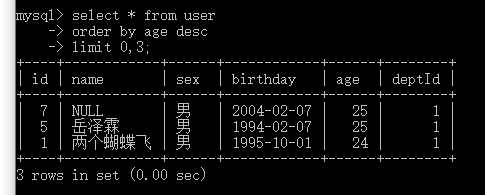
与第一种情况是相同的。 四.三 实际项目中的分页情况实际项目中,从前台传递过来两个值, 一个是 页数,一个是每页所显示的最大条数, 如10. 那么 第一页便显示的是: 0,10第二页便显示的是: 11,10第三页便显示的是: 21,10…第n页便显示的是: (n-1)*10,10即第 n页 显示的数据为: (n-1)*最大条数, 最大条数。 user中共7条数据,每页显示3条数据,可以分3页。 (前2页都是满的,最后一页只有1条数据) 查询第一页的数据为: select * from user order by age desc limit 0,3;
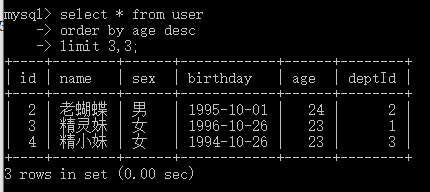
查询第二页的数据为: select * from user order by age desc limit 3,3;
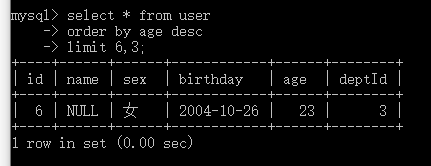
查询第三页的数据为: select * from user order by age desc limit 6,3;
MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT 4,3;”返回的结果相同。 分页显式公式**:(当前页数-1)每页条数,每页条数* SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize; 注意:LIMIT 子句必须放在整个SELECT语句的最后!使用 LIMIT 的好处约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。如果我们知道返回结果只有 1 条,就可以使用LIMIT 1,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。 拓展: 在不同的 DBMS 中使用的关键字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。 如果是 SQL Server 和 Access,需要使用 TOP 关键字,比如: SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC 如果是 DB2,使用FETCH FIRST 5 ROWS ONLY这样的关键字: SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY 如果是 Oracle,你需要基于 ROWNUM 来统计行数: SELECT rownum,last_name,salary FROM employees WHERE rownum < 5 ORDER BY salary DESC;需要说明的是,这条语句是先取出来前 5 条数据行,然后再按照 hp_max 从高到低的顺序进行排序。但这样产生的结果和上述方法的并不一样。我会在后面讲到子查询,你可以使用 SELECT rownum, last_name,salary FROM ( SELECT last_name,salary FROM employees ORDER BY salary DESC) WHERE rownum < 10;得到与上述方法一致的结果。 五 查询总结 五.一 SELECT 执行顺序你需要记住 SELECT 查询时的两个顺序: 1. 关键字的顺序是不能颠倒的: SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同): FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的: SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5 FROM player JOIN team ON player.team_id = team.team_id # 顺序 1 WHERE height > 1.80 # 顺序 2 GROUP BY player.team_id # 顺序 3 HAVING num > 2 # 顺序 4 ORDER BY num DESC # 顺序 6 LIMIT 2 # 顺序 7在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。 需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。 五.二 SQL 的执行原理SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤: 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。 这个过程得到是我们的原始数据。 当我们拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1,就可以在此基础上再进行 WHERE 阶段。 在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2。 然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段。在这个阶段中, 实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4。 当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT 阶段。 首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表 vt5-1 和 vt5-2。 当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6。 最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段,得到最终的结果,对应的是虚拟表 vt7。 当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。 同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序, 所谓底层运行的原理,就是我们刚才讲到的执行顺序。 谢谢 !!! |










【本文地址】