| 揭秘重度MMORPG手游后台性能优化方案 | 您所在的位置:网站首页 › mmorpg手游要多少人开发 › 揭秘重度MMORPG手游后台性能优化方案 |
揭秘重度MMORPG手游后台性能优化方案
|
本文节选自《2018腾讯移动游戏技术评审标准与实践案例》手册,由腾讯互娱工程师王杰分享《仙剑奇侠传online》项目中游戏后台的优化经验,深度解析寻路算法、视野管理、内存优化、同步优化等常见问题。 一、服务器CPU性能优化 1.1寻路算法JPS优化 MMORPG游戏中服务器中需要对NPC寻路,然而A*算法及其各种优化并不让人满意,因此寻路算法也成为瓶颈之一。 因此,本文介绍JPS的效率、多线程、内存、路径优化算法。为了测试搜索算法的优化性能,实验中设置游戏场景使得起点和终点差距200个格子,需要寻路104次。结果发现,A*寻路总时间约2.6074x1011纳秒(一秒为109纳秒);基础版JPS寻路总时间1.7037x1010纳秒;利用位运算优化的JPS(下文称JPS-Bit)寻路总时间3.2364x109纳秒;利用位运算和剪枝优化的JPS(下文称JPS-BitPrune)寻路总时间2.3703x109纳秒;利用位运算和预处理的JPS(下文称JPS-BitPre)寻路总时间2.0043x109纳秒;利用位运算、剪枝和预处理三个优化的JPS(下文称JPS-BitPrunePre)寻路总时间9.5434x108纳秒。 上述结果表明,寻路200个格子的路径,JPS的五个版本,平均消耗时间分别为1.7毫秒、0.32毫秒、0.23毫秒、0.02毫秒、0.095毫秒,寻路速度分别为A*算法的15倍、81倍、110倍、130倍、273倍,大幅度超越A*算法,标志着寻路已经不会成为性能的瓶颈。 事实上,在2012到2014年举办的三届(目前为止只有三届)基于Grid网格寻路的比赛GPPC(The Grid-Based Path Planning Competition)中,JPS已经被证明是基于无权重格子,在没有预处理的情况下寻路最快的算法。 1.1.1 JPS算法介绍 JPS又名跳点搜索算法(Jump Point Search),是由澳大利亚两位教授于2011年提出的基于Grid格子的寻路算法。A*算法整体流程如表1.1.1.1.1所示,JPS算法在保留A*算法的框架的同时,进一步优化了A*算法寻找后继节点的操作。为了说明JPS在A*基础上的具体优化策略,我们在图1.1.1.1.1中给出A*和JPS的算法流程图对比。由图1.1.1.1.1看出,JPS与A*算法主要区别在后继节点拓展策略上,不同于A*算法中直接获取当前节点所有非关闭的可达邻居节点来进行拓展的策略,JPS根据当前结点current的方向、并基于跳点的策略来扩展后继节点,遵循“两个定义、三个规则”(见表1.1.1.1.2,两个定义确定强迫邻居、跳点,三个规则确定节点的拓展原则),具体流程如下: 一,若current当前方向是直线方向: (1)如果current左后方不可走且左方可走(即左方是强迫邻居),则沿current左前方和左方寻找不在closedset的跳点; (2)如果current当前方向可走,则沿current当前方向寻找不在closed集合的跳点; (3)如果current右后方不可走且右方可走(右方是强迫邻居),则沿current右前方和右方寻找不在closedset的跳点; 二,若current当前方向为对角线方向: (1)如果current当前方向的水平分量可走(例如current当前为东北方向,则水平分量为东),则沿current当前方向的水平分量寻找不在closedset的跳点; (2)如果current当前方向可走,则沿current当前方向寻找不在closedset的跳点; (3)如果current当前方向的垂直分量可走(例如current当前为东北方向,则垂直分量为北),则沿current当前方向的垂直分量寻找不在closedset的跳点。 JPS寻找跳点的过程有三种优化:一,位运算;二;预处理;三;剪枝中间跳点。 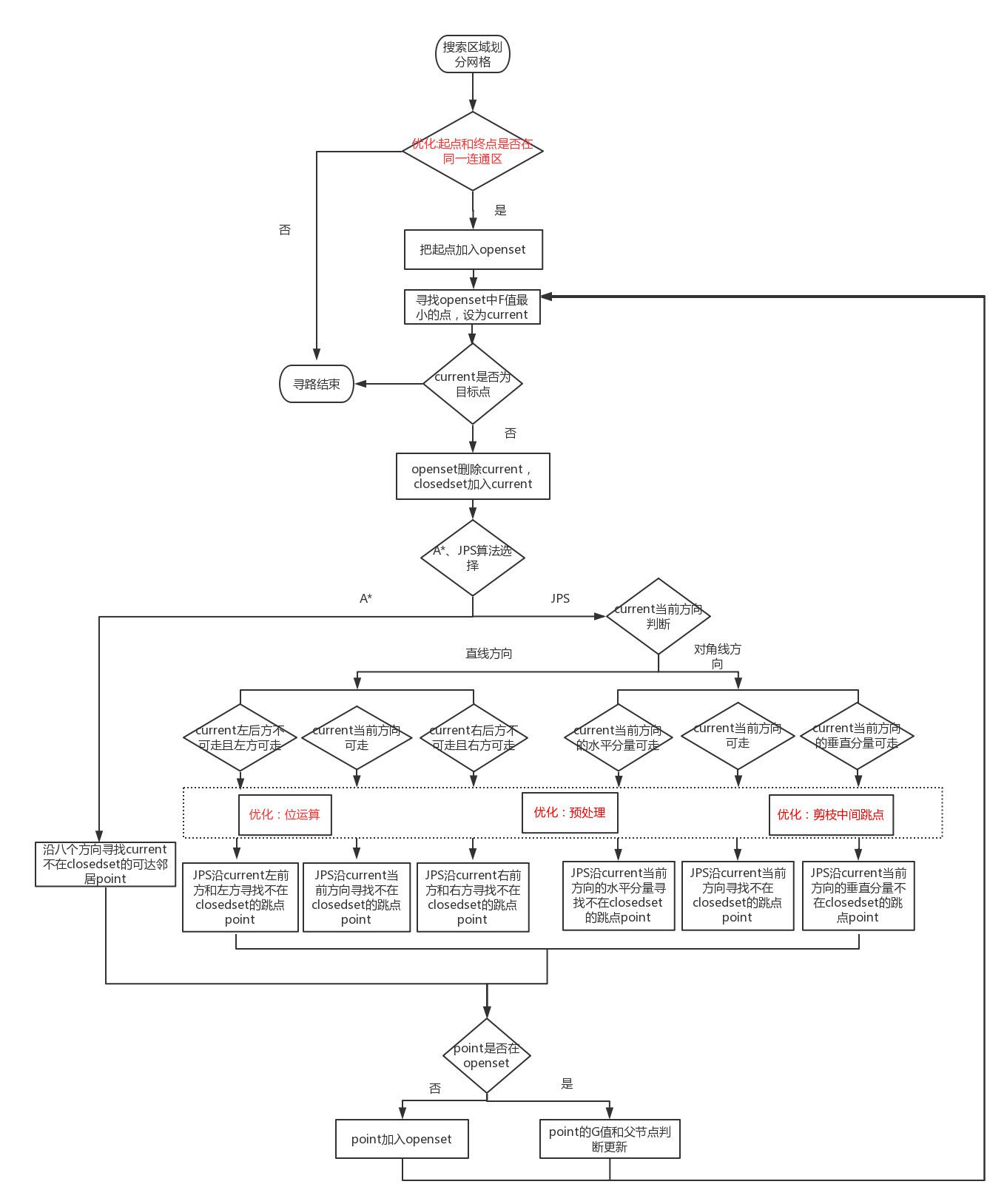
图1.1.1.1.1 A*和JPS的算法流程图对比

表1.1.1.1.1 A*算法流程

表1.1.1.1.2 JPS算法的“两个定义、三个规则”
1.1.1.2 JPS算法举例 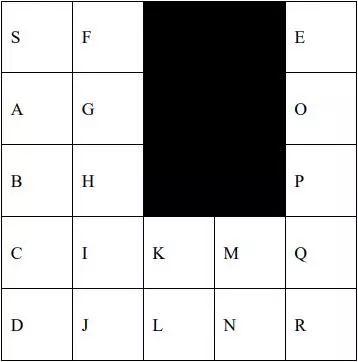
图1.1.1.2.1 寻路问题示例场景(5*5的网格)
下面举例说明JPS具体的寻路流程。问题示例如图1.1.1.2.1所示,5*5的网格,黑色代表阻挡区,S为起点,E为终点。JPS要寻找从S到E的最短路径,首先初始化将S加入openset。从openset取出F值最小的点S,并从openset删除,加入closedset,S的当前方向为空,则沿八个方向寻找跳点,在该图中只有下、右、右下三个方向可走,但向下遇到边界,向右遇到阻挡,因此都没有找到跳点,然后沿右下方向寻找跳点,在G点,根据上文定义二的第(3)条,parent(G)为S,praent(G)到S为对角线移动,并且G经过垂直方向移动(向下移动)可以到达跳点I,因此G为跳点 ,将G加入openset。从openset取出F值最小的点G,并从openset删除,加入closedset,因为G当前方向为对角线方向(从S到G的方向),因此在右、下、右下三个方向寻找跳点,在该图中只有向下可走,因此向下寻找跳点,根据上文定义二的第(2)条找到跳点I,将I加入openset。从openset取出F值最小的点I,并从openset删除,加入closedset,因为I的当前方向为直线方向(从G到I的方向),在I点时I的左后方不可走且左方可走,因此沿下、左、左下寻找跳点,但向下、左下都遇到边界,只有向左寻找到跳点Q(根据上文定义二的第(2)条)),因此将Q加入openset。从openset取出F值最小的点Q,并从openset删除,加入closedset,因为Q的当前方向为直线方向,Q的左后方不可走且左方可走,因此沿右、左、左上寻找跳点,但向右、左上都遇到边界,只有向左寻找到跳点E(根据上文定义二的第(1)条)),因此将E加入openset。从openset取出F值最小的点E,因为E是目标点,因此寻路结束,路径是S、G、I、Q、E。 注意,本文不考虑从H能走到K的情况,因为对角线有阻挡(这点和论文不一致,但和代码一致,因为如果H到K能直接到达,会走进H右边的阻挡区,大部分的JPS开源代码根据论文都认为H到K能直接到达,所以存在穿越阻挡的情况),如果需要H到K能走,则路径是S、G、H、K、M、P、E,修改跳点的计算方法即可。 上述的JPS寻路效率是明显快于A*的,原因在于:在从S到A沿垂直方向寻路时,在A点,如果是A*算法,会将F、G、B、H都加入openset,但是在JPS中这四个点都不会加入openset。对F、G、H三点而言,因为从S、A、F的路径长度比S、F长,所以从S到F的最短路径不是S、A、F路径,同理S、A、G也不是最短路径,根据上文规则二的第(1)条,走到A后不会走到F、G,所以F、G不会加入openset,虽然S、A、H是S到H的最短路径,但因为存在S、G、H的最短路径且不经过A,据上文规则二的第(1)条,从S走到A后,下一个走的点不会是H,因此H也不会加入openset;对B点而言,根据上文规则三,B不是跳点,也不会加入openset,直接走到C即可。 表1.1.1.2.1所示为A*和JPS在寻路消耗中的对比,D. Age: Origins、D. Age 2、StarCraft为三个游戏龙腾世纪:起源、、龙腾世纪2、星际争霸的场景图集合,M.Time表示操作openset和closedset的时间,G.Time表示搜索后继节点的时间。可见A*大约有58%的时间在操作openset和closedset,42%时间在搜索后继节点;而JPS大约14%时间在操作openset和closedset,86%时间在搜索后继节点。避免在openset中加入太多点,从而避免过多的维护最小堆是JPS比A*快的原因((最小堆插入新元素时间复杂度log(n),删除最小元素后调整堆,时间复杂度也为log(n))),实际上在从S到E的寻路过程中,进入openset的只有S、G、I、Q、E。 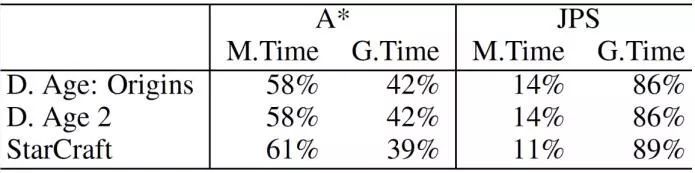
表1.1.1.2.1 A*和JPS的寻路消耗对比
1.1.2 JPS五个优化算法 1.1.2.1 JPS优化之一JPS-Bit:位运算优化 利用位运算优化的JPS-Bit的关键优化思路在于利用位运算来优化JPS中节点拓展的效率。下面以图1.1.2.1.1中的场景示例说明如何将位运算融合于JPS算法中,其中黑色部分为阻挡,假设当前位置为I(标蓝位置),当前方向为右,位运算中使用1代表不可走,0代表可走,则I当前行B的八位可以用八个bit:00000100表示,I上一行B-的八位可以用八个bit:00000000表示,I的下一行B+的八位可以用八个bit:00110000表示。在当前行寻找阻挡的位置可以用CPU的指令__builtin_clz(B)(返回前导0的个数),即当前阻挡在第5个位置(从0开始)。寻找当前行的跳点可以用__builtin_clz(((B->>1) && !B-) ||((B+>>1) && !B+)) 寻找,例如本例中(B+>>1) && !B+为:(00110000 >> 1) && 11001111,即00001000,而(B->>1) &&!B为00000000,所以__builtin_clz(((B->>1) && !B-) ||((B+>>1) && !B+))为__builtin_clz(00001000)为4,所以跳点为第4个位置M(从0开始)。注意论文中使用_builtin_ffs(((B- GameServer1,请求消息共需要转发四次。同时,查看离线玩家信息时,通常需要对数据库进行操作,这都导致查看玩家信息需要被优化。 为此,本文通过对玩家信息进行缓存(玩家cache)实现玩家信息查看优化。具体上,1)同一游戏服务器下的用户不需缓存,譬如,GameServer1玩家A查看GameServer1的玩家B不通过缓存就可以很容易地获取玩家B信息;2)不同游戏服务器下需进行玩家缓存,且缓存按需更新。譬如,GameServer1玩家A查看GameServer2的玩家C,在GameServer1的玩家cache中查看玩家C,如果玩家C进入缓存时间超过10秒,更新缓存中玩家C信息,如果玩家C不在缓存中,则从数据库加载;3)查看离线玩家同样利用玩家cache,每逢玩家离线,通知所有GameServer更新玩家cache中该玩家信息。 因为被查看的玩家往往都是等级、战力等特别高的玩家,这些玩家会被大量玩家查看,所以本文提出的玩家缓存机制往往命中率极高,实测中缓存命中率达到80%-90%左右。 二、服务器内存优化 2.1 内存统计 在对内存优化之前,需要先确定程序每个模块的内存分配。程序的性能有perf、gprof等分析工具,但内存没有较好的分析工具,因此需要自行统计。在linux下/proc/self/statm有当前进程的内存占用情况,共有七项:指标vsize虚拟内存页数、resident物理内存页数、share 共享内存页数、text 代码段内存页数,lib 引用库内存页数、data_stack 数据/堆栈段内存页数、dt 脏页数,七项指标的数字是内存的页数,因此需要乘以getpagesize()转换为byte。在每个模块结束后统计vsize的增加,即可知该模块占用的内存大小。 在面向对象开发中,内存的消耗由对象的消耗组成,因此需要统计每个类的成员变量的占用内存大小。使用CLion或者visual studio都可以导出类中定义的所有成员变量,然后在gdb使用命令: p ((unsigned long)(&((ClassName*)0)->MemberName)),即可打印出类ClassName的成员变量MemberName相对类基地址的偏移,根据偏移从小到大排序后,变量的顺序即为定义的顺序,根据偏移相减即可得出每个成员变量大小,然后优化占用内存大的成员变量。 2.2 内存泄露 内存泄露是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,导致内存一直增长。虽然有valgrind等工具可以检查内存泄露,但valgrind虚拟出一个CPU环境,在该环境上运行,会导致内存增大、效率降低,对于大规模程序,基本无法在valgrind上运行。因此需要自行检查内存泄露,glibc提供的内存管理器的钩子函数可以监控内存的分配、释放。如图2.2.2、2.2.3所示,分别为钩子函数的分配内存和释放内存。因为服务器启动时需要预先分配很多内存,比如内存池,这些内存是在服务器停止时才释放,因此为了避免这些内存的干扰,在服务器启动之后才能开始内存泄露的统计。 首先申请固定大小的vec_stack,记录所有分配的内存,如果有释放,则从vec_stack中删除,最后vec_stack中的元素即为泄露的内存,vec_stack必须为固定大小,否则vector扩容中会有内存分配,也不可以用map,map的红黑树旋转也会有内存分配,会造成干扰;然后通过图2.2.1所示的my_back_hook记录原有的malloc、free;并通过图2.2.2所示的my_init_hook将malloc、free换成自定义的钩子函数。 每次分配内存时,都会进入自定义钩子函数my_malloc_hook中,如图2.2.2所示。在my_malloc_hook中首先通过my_recover_hook将malloc恢复成默认的,否则会造成死递归,然后通过默认的malloc分配大小为size的空间,为了分线程统计内存泄露,还需要对线程号做判断,在stTrace.m_pAttr记录内存分配的地址,m_nSize记录大小,m_szCallTrace记录调用栈,如果vec_stack已满,需要根据m_nSize从大到小排序,如果当前分配内存大于vec_stack记录的最小的分配内存,则替换;如果未满,则直接加入vec_stack,在my_malloc_hook结束时,将malloc替换成自定义的malloc。 每次释放内存时,都会进入自定义钩子函数my_malloc_free中,如图2.2.3所示。在my_malloc_free中首先通过my_recover_hook将free恢复成默认的,否则会造成死递归,对线程号判断,然后在vec_stack中删除对应的分配,并将free替换成自定义free。 
图2.2.1
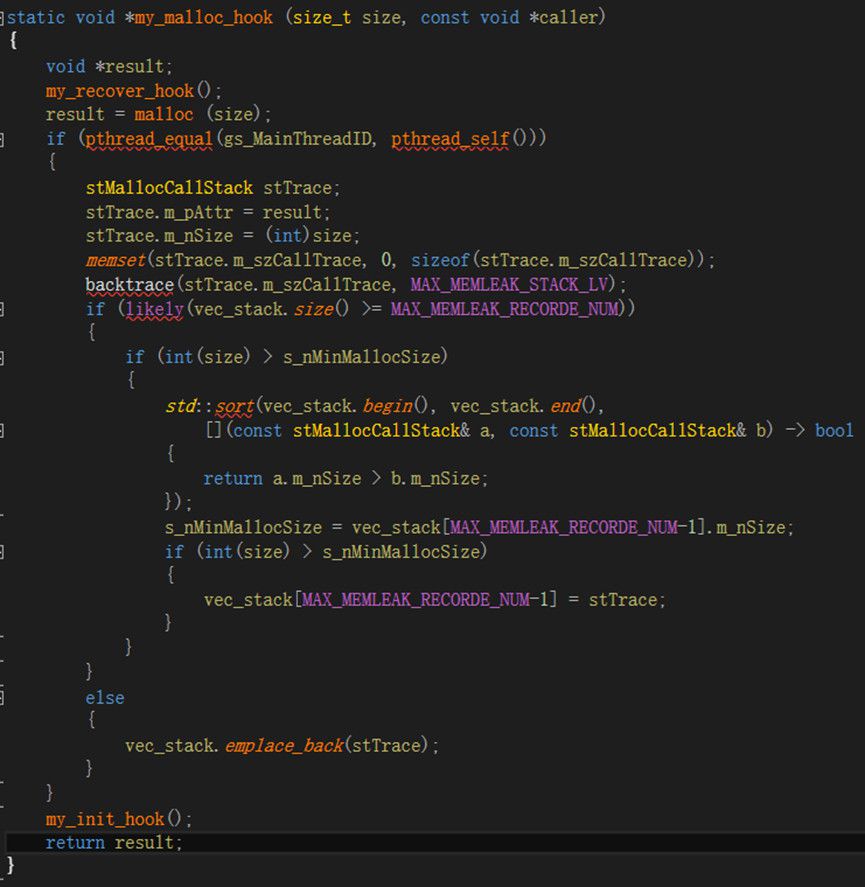
图2.2.2
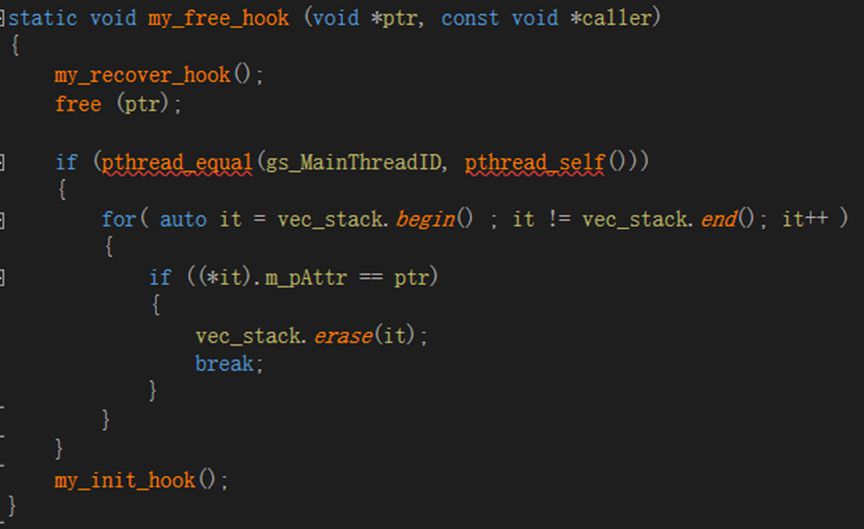
图2.2.3
2.3 内存池 在游戏服务器内存分配过程中,glibc中的malloc采用的是ptmalloc,ptmalloc在对小对象进行分配时会产生大量内部碎片,同时也会有外部碎片的产生。因此往往需要自行设计并实现模板化的内存池,采用内存池的好处是,避免内部、外部碎片,对象New/Delete均为O(1)复杂度,同时有利于监控。例如当模板参数为宠物时,首先new出60个宠物的空间,对这60个宠物空间,当60个空间被全部使用时,再分配60个空间。本文在内存池设计中实现两个数据管理器,分别是空闲数据管理器freeList和使用空间管理器usedList,freeList采用queue实现即可,usedList采用vector。 由于这部分较复杂,因此用代码辅以说明。如图2.3.1,在Init函数中传入要创建的对象数目capacity,pointer根据capacity预先分配空间,用于建立所有对象索引,pointer主要用来校验。本文按块Chunk创建对象,每块Chunk有objectperchunk个T类型对象。chunksize记录当前总共创建了多少对象。虽然Init函数设定了capacity,但是初始并没有创建capacity个T对象,而是先创建objectperchunk个T对象供使用,并记录到freelist中。 如图2.3.2所示,每次新创建对象时调用NewObj函数,如果freelist为空,说明所有已创建的对象均被使用,则再调用NewChunk创建objectperchunk个T对象;如果不为空,直接返回freeList头部的指针。 如图2.3.3所示,每次删除对象时调用DeleteObj函数,参数为待删除对象指针,除了必要的校验以外,将对象指针从usedList删除,并将usedList最后一个对象指针移动到删除位置,记录删除位置deleteusedlistindex。同时将对象指针所指的对象清空加入freeList,以便再次使用,好处时内存不回收可以重复使用。 如图2.3.4所示,对象的遍历在usedList上进行,但在遍历中可能会删除对象,此时deleteusedlistindex == iterateindex,因为删除对象后,会将usedList最后一个对象指针移动到deleteusedlistindex位置,因此iterateindex不能增加。 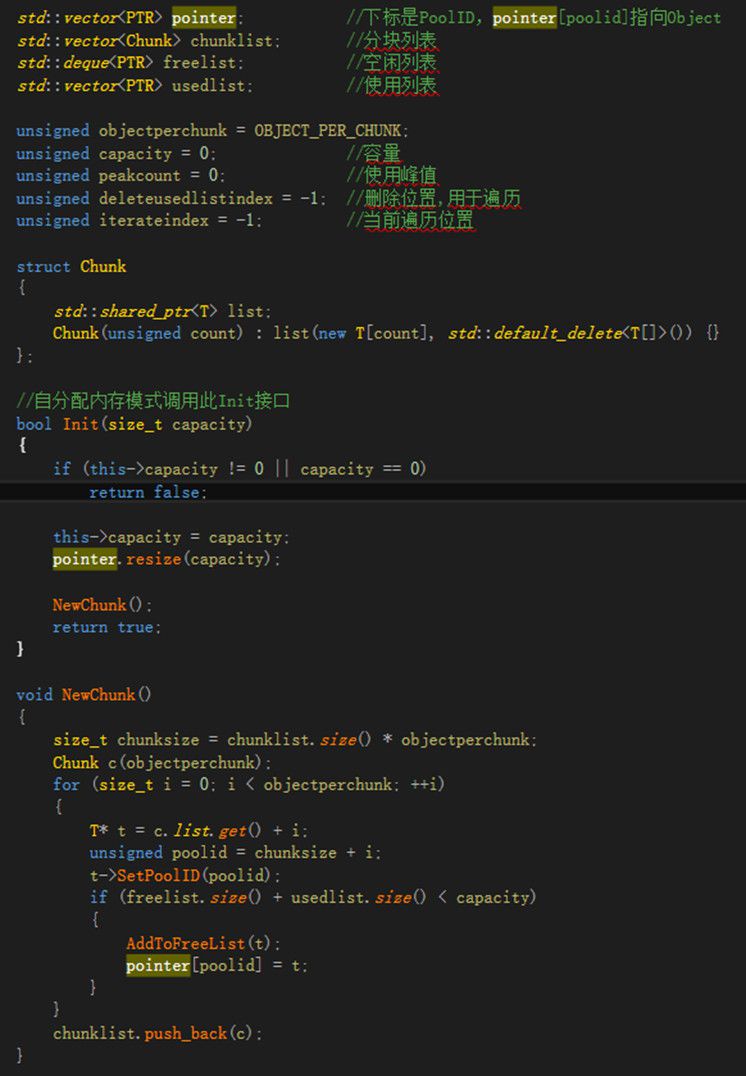
图2.3.1
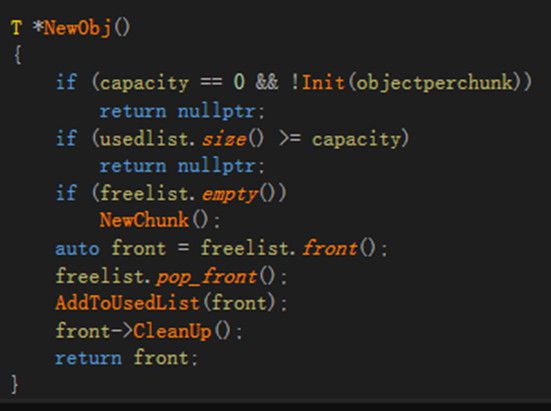
图2.3.2
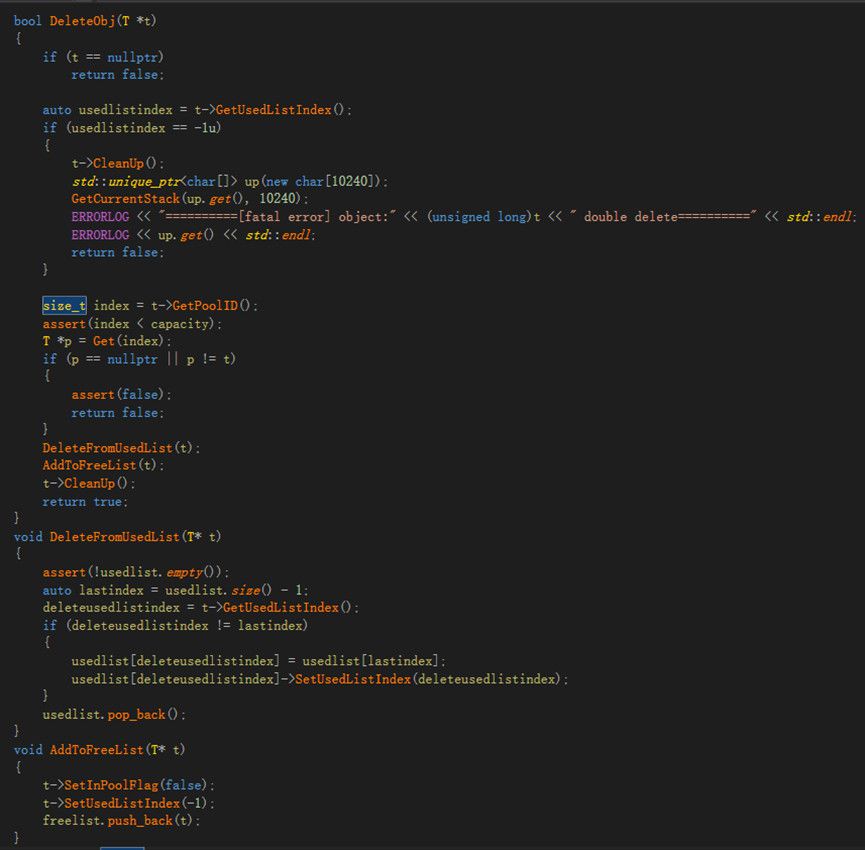
图2.3.3
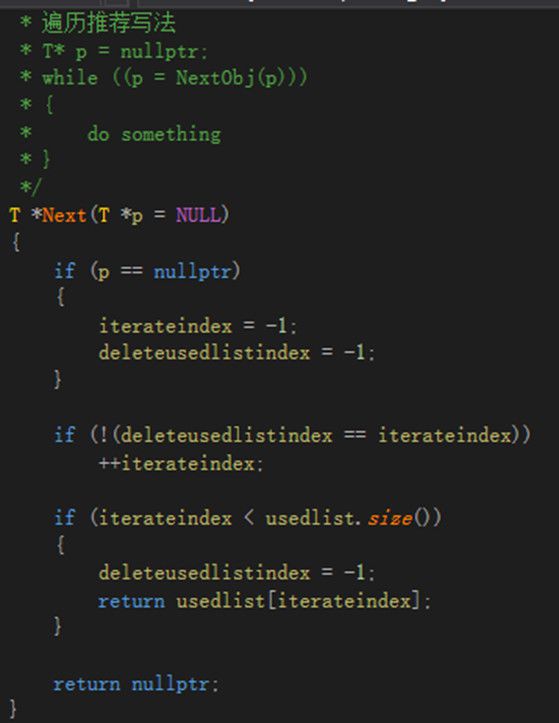
图2.3.4
2.4 内存分配(ptmalloc vs tcmalloc) 即使使用内存池,程序中仍然需要大量使用malloc分配空间。但主流使用的ptmalloc存在如下缺点:一,ptmalloc采用多个线程轮询加锁主分配区和非主分配的方式,造成锁的开销;二,多线程间的空闲内存无法复用,利用线程A释放一块内存,由于并不一定会释放给操作系统,线程B申请同样大小的内存时,不能复用A释放的内存,导致使用内存增加;三,ptmalloc分配的每块chunk需要8个字节记录前一个空闲块大小和当前块大小以及一些标记位。 为此,本文提倡使用tcmalloc进行内存分配。tcmalloc对每个线程单独维护ThreadCache分配小内存;针对ptmalloc多线程内存无法复用的问题,tcmalloc为进程内的所有线程维护公共的CentralCache,ThreadCache会阶段性的回收内存到CentralCache;针对ptmalloc每块chunk使用8个字节表示其他信息,tcmalloc对每块chunk使用大概百分之一的空间表示其他信息,对小对象分配,空间利用率远高于ptmalloc。 三、服务器启动时间优化 3.1 读取阻挡文件优化 服务器启动时,需要读大量文件,其中最大的文件就是阻挡文件,每个阻挡文件大约有几M,采用c++的ifstream可以一次读取一个字节,也可以一次读取整个文件,后者的速度比前者快几十倍以上。如图3.1.1所示,MATRIX_LEN为4096,阻挡文件为4096*4096byte,共16M,图3.1.1按byte读取阻挡文件需要2564ms,图3.1.2一次性读取阻挡文件需要50ms。 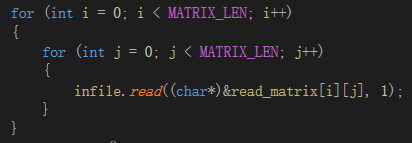
图3.1.1

图3.1.2
来源:腾讯游戏学院原地址:https://mp.weixin.qq.com/s/1WN9rA4yK6Wi2-BhQFIn5Q |
【本文地址】