| MATLAB数据处理(1) | 您所在的位置:网站首页 › matlab怎么进行数据拟合 › MATLAB数据处理(1) |
MATLAB数据处理(1)
|
MATLAB数据处理(1)——拟合概率密度函数
序言一个简单的例子
fit函数fit函数的输入fit函数的输出
序言
最近因为一些工程上的问题需要学习一下matlab数据处理,将包含:数据清洗、小波变换、拟合概率密度函数等内容,由于网上没有很多相关的教程,并且相关的书籍讲的也比较浅,为了加深自己的学习成果,也为了给后来学习的同学一点帮助,下面将一些学习心得分享给大家。 一个简单的例子我们首先通过一个例子来简单认识一下一个简单的概率分布拟合的过程。 第一步,生成一系列的随机数,并对随机数进行统计,生成频率分布直方图,这里使用了一个重要的函数histogram clc;clear; y = randn(1,5001);%随机生成服从正态分布的样本点 nbins=100; %指定条形图bar的数量,并对区间进行等分 h=histogram(y,nbins);简要描述一下histogram,他主要是对我们手中的数据进行一个简单统计,并生成频数分布直方图: histogram(X)——默认设置生成histogram(X,nbins)——指定bar的数量histogram(X,edges)——指定edges生成频数分布直方图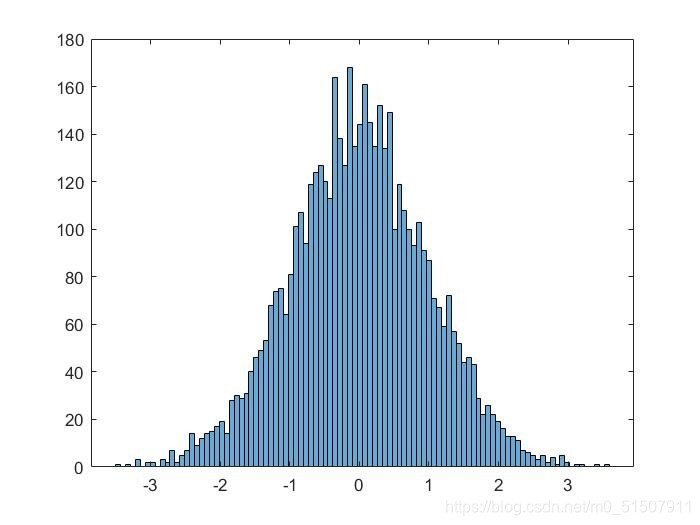 除了直方图,我们可以得到一些对于后面拟合有用的信息:
>> h
h =
Histogram - 属性:
Data: [1×5001 double]
Values: [1×100 double]
NumBins: 100
BinEdges: [1×101 double]
BinWidth: 0.078600000000000
BinLimits: [-3.640000000000001 4.220000000000000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0 0 0]
显示 所有属性 除了直方图,我们可以得到一些对于后面拟合有用的信息:
>> h
h =
Histogram - 属性:
Data: [1×5001 double]
Values: [1×100 double]
NumBins: 100
BinEdges: [1×101 double]
BinWidth: 0.078600000000000
BinLimits: [-3.640000000000001 4.220000000000000]
Normalization: 'count'
FaceColor: 'auto'
EdgeColor: [0 0 0]
显示 所有属性
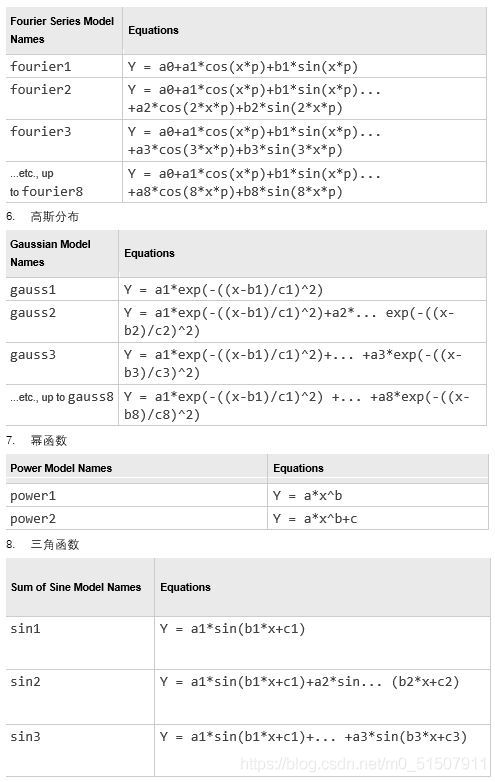
可以看到h.BinEdges这个参数就是直方图的横坐标,而h.Values就是每一个区间的频数,这对后面的拟合提供了初始参数。我们要对h.BinEdges做一点处理才能作为拟合的横坐标,这是因为我们要用bar的中心点作为拟合时候的横坐标: x=[]; for i = 2:nbins+1 x(i-1)=0.5*(h.BinEdges(i)+h.BinEdges(i-1)); end z=h.Values;由“经验”我们可以看出,这个频率分布直方图明显满足正态分布,所以我们要指定matlab用一阶高斯分布’gauss1’正态分布进行拟合: x=x'; %之前得到的都是行向量,要转化为列向量才可以使用fit函数 z=z'; [fitobject,gof] = fit(x,z,'gauss1');输出结果: 通过上面的例子,我们对fit有一个简单的了解,具体来说,使用fit有以下几种形式: fitobject = fit(x,y,fitType) 使用指定的fittype对以x为横坐标,y为纵坐标的二维数据进行拟合fitobject = fit([x,y],z,fitType) 使用指定的fittype对以x,y为横坐标,z为纵坐标的三维数据进行拟合fitobject = fit(x,y,fitType,fitOptions) 使用指定的fittype以及fitOptions算法选项对以x为横坐标,y为纵坐标的二维数据进行拟合[fitobject,gof] = fit(x,y,fitType) 使用指定的fittype以及fitOptions算法选项对以x为横坐标,y为纵坐标的二维数据进行拟合,并返回拟合优度(Goodness of Fit)[fitobject,gof,output] = fit(x,y,fitType) 返回拟合结果output可以看到,这里面有一个非常重要的fitType,即在进行拟合之前我们需要指定一个拟合的种类,这个可以根据自己的判断,matlab提供了其实不止以下这么几种,如果有需要可以去help中继续查找使用:
只有明白输出是什么,我们才可以对我们得到的这个拟合出的概率分布函数,作进一步的计算。 fit函数的输出我们还是使用刚开始的那个例子来讲解。在命令行输入fitobject >> fitobject fitobject = General model Gauss1: fitobject(x) = a1*exp(-((x-b1)/c1)^2) Coefficients (with 95% confidence bounds): a1 = 137.5 (135, 139.9) b1 = -0.0004399 (-0.02091, 0.02003) c1 = 1.411 (1.382, 1.44)可以看到实际上fitobject已经得到了这个拟合的具体的概率密度函数,实际上高斯分布的概率密度函数是: 我们还是先算一下其他两个系数: 这就是因为fit函数在这里并不是拟合概率密度函数,而是单纯的为了拟合(x,z)离散的点而得到的函数,他只不过是借用了高斯分布的形式。那我们怎么把这个函数变成gauss概率分布函数呢? 其实很简单,fitobject函数只是在gauss概率密度函数上乘了一个放大系数,以此来拟合(x,z),我们只需要把这个放大系数提出即可,或者说,直接将前面已经得到的 代回到gauss概率密度函数中即可。 mu=fitobject.b1; sigma=fitobject.c1/sqrt(2); xx=-10:0.001:10; fun=(1/sqrt(2*pi)/sigma).*exp(-((xx-mu)/(sigma*sqrt(2))).^2); figure(2) plot(xx,fun)输出结果: |
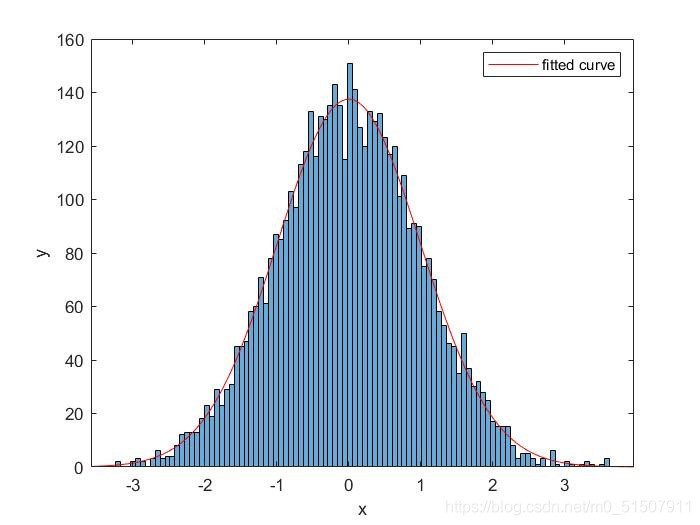 同学们可以用下面这个完整代码,在电脑中运行一遍:
同学们可以用下面这个完整代码,在电脑中运行一遍: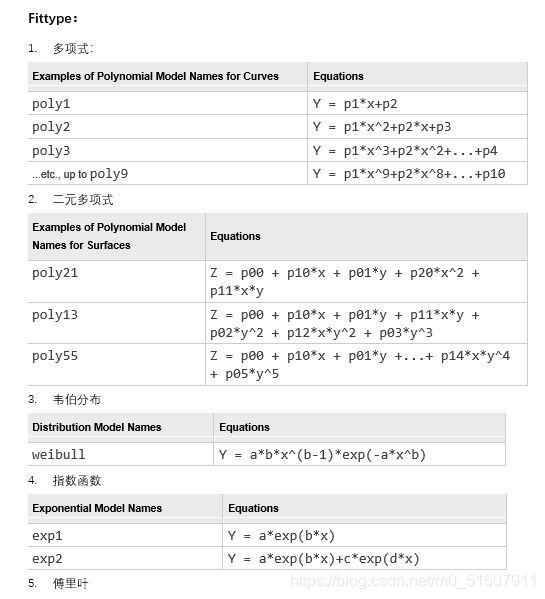
 其实就我目前接触到的实际项目而言,以上内容已经足以应付我们概率拟合的输入,关键是我们还要了解一下输出的东西是什么,经过fit函数,我们得到了什么?
其实就我目前接触到的实际项目而言,以上内容已经足以应付我们概率拟合的输入,关键是我们还要了解一下输出的东西是什么,经过fit函数,我们得到了什么?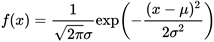 所以在这里a1实际上等于 ,换算后可以得到 =0.003,这和我们生成随机数时的N(0,1)正态分布差远了,这是为什么呢?
所以在这里a1实际上等于 ,换算后可以得到 =0.003,这和我们生成随机数时的N(0,1)正态分布差远了,这是为什么呢?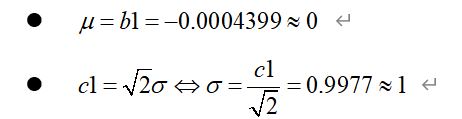 其他两个系数的计算非常符合N(0,1),究竟是怎么回事呢?
其他两个系数的计算非常符合N(0,1),究竟是怎么回事呢?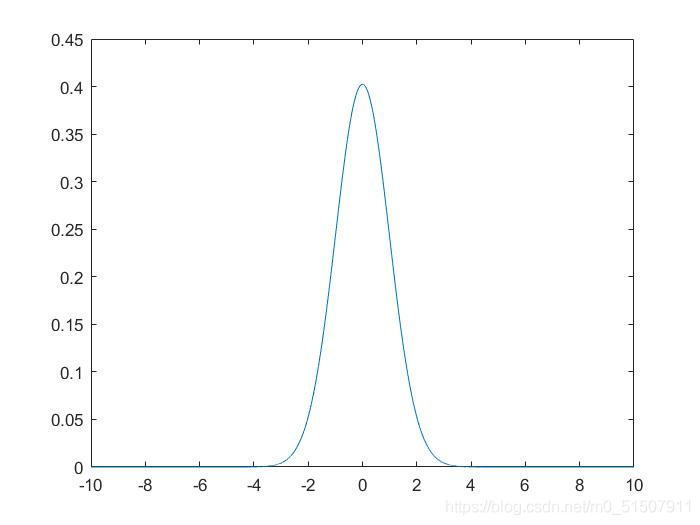
【本文地址】