| Hive参数调优系列1:控制map个数与性能调优 | 您所在的位置:网站首页 › map数取决于 › Hive参数调优系列1:控制map个数与性能调优 |
Hive参数调优系列1:控制map个数与性能调优
|
本系列⼏章系统地介绍了开发中Hive常见的⽤户配置属性(有时称为参数、变量或选项),并说明了哪些版本引⼊了哪些属性,常见有哪些属性的使⽤,哪些属性可以进⾏Hive调优,以及如何使⽤的问题。以及⽇常Hive开发中如何进⾏性能调优。 1.Hive有哪些参数,如何查看这些参数1. Hive⾃带的配置属性列表封装在HiveConfJava类中,因此请参阅该HiveConf.java⽂件以获取Hive版本中可⽤的配置属性的完整列表。具体可以下载hive.src通过idea查看。全部属性有上千个吧,⼀般Hive的⾃带属性都是以hive.开头的,每个属性且⾃带详细的描述信息,其次Hive官⽹也有,但是属性不是特别全。
很显然,对于这个控制每个map的split输⼊⼤⼩的参数,不是hive⾃带的参数,⽽是MR提供的参数,但是Hive可以通过set的形式配置使⽤,⽽且对于调优有很⼤的作⽤。但是这个参数实际上要配合HDFS的blocksize⼀起使⽤。下⾯以我们公司开发环境的默认配置参数。 -- 每个Map最⼤输⼊⼤⼩, hive> set mapred.max.split.size; mapred.max.split.size=256000000 这也是官⽅默认值 -- 每个Map最⼩输⼊⼤⼩ hive> set mapred.min.split.size; mapred.min.split.size=10000000 这也是官⽅默认值 hive> set dfs.block.size; dfs.block.size=134217728 我们集群默认hdfs的block块⼤⼩是128Mb,但注意这个参数通过hive设置更改实际没有⽤的,只能hdfs设置。 2.1数据准备,两张表如下进⾏两张表join,其中每张表的⼤⼩,hdfs上存储的⽂件总个数,以及每个⽂件的⼤⼩。 1. ⼤表总共158749566⾏,⽂件总⼤⼩4.4G,存储个数22个⽂件,每个⼤⼩200Mb左右。 2. ⼩表总共1979375 ⾏,⽂件⼤⼩50.7Mb,存储个数2个⽂件,⼤⼩50Mb以内。 2.2两个表进⾏关联,其中⼩表在前,⼤表在后结果分析:hive启动了24个map函数,17个reduce函数。 在hadoop中,⼀般默认的split切⽚⼩于等于blocksize(128Mb),如果是⼩⽂件的话(未进⾏⼩⽂件的合并)则每个⼩⽂件启动⼀个map函数。⽽实际在hive中,并不是split的⼤⼩要⼩于等于blocksize,⽽是可以远⼤于blocksize。⽐如这⾥,4.4G⽂件表,按128Mb切⽚算的话,⾄少实际需要35个map,⽽实际只需要24个,平均每个map处理了187Mb的⽂件。这是为什么呢?此外这⾥明明设置了set mapred.max.split.size=134217728,每个map最⼤split块128Mb,⽽实际为什么参数没有⽤呢? 3.案例演⽰决定map个数的因素其实决定map个数的因素有很多,⽐如⽂件是否压缩,压缩的后的⽂件是否⽀持切分,⽐如⽂件默认的inputfort格式,不同实现类的split算法也不同,那么map的个数调优⽅式也不同,下⾯按分类详细说明hive中决定map个数的因素与常见map调优的使⽤。⾸先分类:处理的⽂件是否压缩,且压缩算法是否⽀持⽂件的切分 如下我们公司,对于hive关于压缩的配置,使⽤了压缩,且使⽤的是默认的压缩算法是deflate⽅法 hive> set io.compression.codecs; --配置了哪些压缩算法 io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com hive> set hive.exec.compress.output; hive.exec.compress.output=true --是否开启压缩 hive> set mapreduce.output.fileoutputformat.compress.codec; --使⽤的压缩算法 mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec 我们知道hive中有些压缩算法是不⽀持⽂件切分的,如下我们使⽤的默认的deflate算法,就不⽀持⽂件切分。
------------------------使⽤不同参数执⾏上⾯代码产⽣的map个数--------------------------------- --1.使⽤系统配置的默认值 set mapred.max.split.size = 256000000; -- set mapred.min.split.size = 256000000; Hadoop job information for Stage-1: number of mappers: 24; number of reducers: 17 --2.降低系统默认值 set mapred.max.split.size=134217728; set mapred.min.split.size=134217728; Hadoop job information for Stage-1: number of mappers: 24; number of reducers: 17 --3.调⾼系统默认值 set mapred.max.split.size=500000000; set mapred.min.split.size=256000000; Hadoop job information for Stage-1: number of mappers: 9; number of reducers: 17 --4.调⾼系统默认值 set mapred.max.split.size=1024000000; set mapred.min.split.size=1024000000; Hadoop job information for Stage-1: number of mappers:6 ; number of reducers: 1 如上我们使⽤不同的参数配置,来运⾏上⾯同⼀段代码,看系统产⽣的map个数,细⼼的⼈会发现,当我们使⽤默认值是产⽣了24个 map,平均每个map处理了187Mb⽂件,但当我们调低set mapred.max.split.size=134217728时(每个map最多处理128Mb),相应的 map个数并没有增加,这是为什么呢? 关于这个问题就要说到决定map个数的⾸要因素:⽂件是否启动压缩,且压缩算法是否⽀持⽂件切分了。因为这⾥⽂件存储使⽤默认 的deflate算法,不⽀持⽂件切分,所以设置的参数split.size=134217728没有⽣效。因为每个map处理的splitsize实际上要⼤于等于每 个⽂件存储的⼤⼩。这⾥每个⽂件存储的⼤⼩200Mb左右,所以每个map处理的最⼩尺⼨要⼤于200Mb。 ⽽当我们将set mapred.max.split.size=102400000设置的很⼤时,为什么⼜可以控制map个数了呢?因为deflate压缩算法虽然不 ⽀持⽂件切分,但是可以进⾏⽂件合并哇。从hive0.5开始就默认map前进⾏⼩⽂件合并了。如下,我们公司使⽤的也是默认的开启map前 ⽂件合并。但是注意即使这⾥⽀持⽂件合并,也是基于⽂件块的整个⽂件块合并,⽽不是基于blocksize的block合并。 hive> set hive.input.format; --hive0.5开始的默认值,这个值会影响map个数的控制 hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat 提⽰1: 通过上⾯分析总结,当hive需要处理的⽂件是压缩,且压缩算法不⽀持⽂件切分的时候,决定map个数的因素主要是⽂件块实际存储的⼤⼩,如果⽂件块本⾝很⼤,⽐如500Mb左右,那么每个map处理的splitsize⾄少要是500Mb左右。这个时候我们不能⼈为通过参数降低每个map的splitsize来增加map个数,只能通过增加splitsize,减少map个数。 但是⼀般经验来说,每个map处理的splitsize最好是128Mb(等于blocksize),这样效率最⾼。所以这个时候如果我们想增加map个数,只能通过临时表或者insert ...select的形式,通过参数配置将⽂件块重新存储成较⼩的⽂件块,然后再进⾏处理。反之,如果⽂件块本⾝很⼩,那么我们可以通过增加splitsize来减少map,进⽽调优提⾼程序的运⾏效率。 总结1: 如果hive处理的⽂件是压缩模式,且压缩模式不⽀持⽂件切分,那么这个时候我们只能通过控制参数来减少map个数,⽽不能通过配置参数来增加map个数,所以Hive对于压缩不可切分⽂件的调优有限。可以⾸先通过hadoop fs -du -s -h命令查看⽂件的存储⼤⼩结果,然后根据实际进⾏调优。常⽤的配置参数如下: set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --hive0.5开始就是默认值,执⾏map前进⾏⼩⽂件合并 ---------------------------------------------------------------------- set mapred.max.split.size=256000000 set mapred.min.split.size=10000000 set mapred.min.split.size.per.node=8000000 --每个节点处理的最⼩split set mapred.min.split.size.per.rack=8000000 --每个机架处理的最⼩slit. ------------------------------------------------------------------------ 1.注意⼀般来说这四个参数的配置结果⼤⼩要满⾜如下关系。 max.split.size >= min.split.size >= min.size.per.node >= min.size.per.node 2.这四个参数的作⽤优先级分别如下 max.split.size = min.size.per.node 2.这四个参数的作⽤优先级分别如下 max.split.size |
 2. Hive除了⾃⾝带了⼀些配置属性,因为其底层使⽤的是hadoop(HDFS,MR,YARN),所以有些HADOOP的配置属性Hive也可以使⽤,进⾏配置,但是有些则使⽤不了。⽐如mapred.max.split.size 就属于MR的参数,但是hive可以使⽤
2. Hive除了⾃⾝带了⼀些配置属性,因为其底层使⽤的是hadoop(HDFS,MR,YARN),所以有些HADOOP的配置属性Hive也可以使⽤,进⾏配置,但是有些则使⽤不了。⽐如mapred.max.split.size 就属于MR的参数,但是hive可以使⽤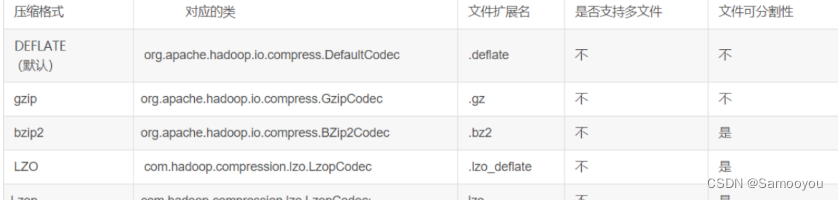
【本文地址】