| 线性模型:线性回归、逻辑回归、线性判别分析、多分类学习与类别不平衡问题 | 您所在的位置:网站首页 › lr和线性回归的联系和区别 › 线性模型:线性回归、逻辑回归、线性判别分析、多分类学习与类别不平衡问题 |
线性模型:线性回归、逻辑回归、线性判别分析、多分类学习与类别不平衡问题
|
一、基本形式
x x x 有 d d d 个属性,即 x = ( x 1 , x 2 , . . . , x d ) \textbf{x}=(x_1,x_2,...,x_d) x=(x1,x2,...,xd) , 线性模型试图学得一个通过属性的线性组合来进行预测的函数。 一般形式: f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b f(x)=w_1x_1+w_2x_2+...+w_dx_d+b f(x)=w1x1+w2x2+...+wdxd+b向量形式: f ( x ) = w T x + b f(\textbf{x})=\textbf{w}^T\textbf{x}+b f(x)=wTx+b线性模型简单、易于建模、具有很好的可解释性(understandability),很多非线性模型都是在线性模型的基础上引入层级结构或高维映射获得的。 一般范式 在进行典型线性模型介绍之前,先总结一下回归问题的基本框架: Model Hypothesis 模型假设Optimize Parameters 参数估计Minimize cost function 最小化损失函数Goal results 目标结果 二、线性回归线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。——百度百科 1. 模型假设最简单的情况是,输入属性只有一个,即一元线性回归。比如探究工龄和工资之间的关系,以工资为y,工龄为x,建立一元线性回归模型 y = w x + b y=wx+b y=wx+b 只要求出w和b该模型就固定下来了。 再考虑复杂一些的情况: (1)如果不是连续数值属性怎么办? 属性值之间存在序(order)的关系,可以转化为数值。属性“身高”取值为“高”,“矮”,可以转化为{1.0, 0.0} 属性“身高”取值为“高”,“中”,“矮”,可以转化为{1.0, 0.5, 0.0} 因为高和矮虽然是离散的非数值,但是它们之间是有大小关系的,对于身高而言,“高”肯定大于“矮”,因此可以这样转化。 属性值之间不存在序的关系,可以采用one-hot编码one-hot编码简介 西瓜的属性“瓜类”有“西瓜”“南瓜”“黄瓜”三个取值,可转化为(0,0,1),(0,1,0),(1,0,0) (2)不止一个属性 相当于多元线性回归,建立模型 f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b f(x)=w_1x_1+w_2x_2+...+w_dx_d+b f(x)=w1x1+w2x2+...+wdxd+b,根据已有的数据求出参数的值,令求得参数下计算出的 f ( x ) f(x) f(x)尽可能的等于实际的 y y y. 以只有一个属性的情况为例进行说明。要令 f ( x ) f(x) f(x) 尽可能的等于实际的 y y y,那这个衡量的标准是什么,用什么指标来显示 f ( x ) f(x) f(x) 和 y y y 之间的差别呢?——均方误差(mean-square error, MSE) 通俗的说明什么是均方误差:有100条数据,第 i i i 条数据的输出变量实际值 y i y_i yi,而根据模型计算出的为 f ( x i ) f(x_i) f(xi) , 则 M S E = ∑ i = 1 100 ( f ( x i ) − y i ) 2 MSE=\sum\limits_{i=1}^{100}(f(x_i)-y_i)^2 MSE=i=1∑100(f(xi)−yi)2均方误差是回归任务中最常用的性能度量,它在几何意义上对应了欧几里得距离,因此我们可以试图让均方误差最小化,这种基于均方误差最小化来进行模型求解的方法成为 “最小二乘法” ,也就是找一条直线,是所有样本到直线上的欧式距离之和最小,即: ( w ∗ , b ∗ ) = a r g m i n ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 (w^*,b^*)=\underset{(w,b)}{arg min}\sum\limits_{i=1}^m(f(x_i)-y_i)^2 (w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2 ( w ∗ , b ∗ ) = a r g m i n ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 (w^*,b^*)=\underset{(w,b)}{arg min}\sum\limits_{i=1}^m(y_i-wx_i-b)^2 (w∗,b∗)=(w,b)argmini=1∑m(yi−wxi−b)2此处 argmin 的意思就是求使得后面的式子达到最小时w,b的值, ( w ∗ , b ∗ ) (w^*,b^*) (w∗,b∗) 表示最优取值,加“ * ” 是运筹学里的“最优”的表示法~ 2. 参数估计求解 w w w和 b b b使均方误差(用 E E E表示)最小化的过程,称为线性回归模型的最小二乘“参数估计”,通过高等数学知识不难知道, E E E分别对 w w w和 b b b求偏导,并令偏导数为0,此时的 w w w和 b b b即为最优解。 ∂ E ( w , b ) ∂ w = 2 ( w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ) \frac{\partial E_{(w,b)}}{\partial w}=2\left(w\sum\limits_{i=1}^mx_i^2-\sum\limits_{i=1}^m(y_i-b)x_i\right) ∂w∂E(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi) ∂ E ( w , b ) ∂ b = 2 ( m b − ∑ i = 1 m ( y i − w x i ) ) \frac{\partial E_{(w,b)}}{\partial b}=2\left( mb-\sum\limits_{i=1}^m(y_i-wx_i)\right) ∂b∂E(w,b)=2(mb−i=1∑m(yi−wxi))如果初学者对于求导这一步不太转得过来的话,只要将均方误差表达式的平方都乘开,再来求导就很容易看出结果啦 可能有人疑惑,偏导数为0应为极值点,可能极大也可能极小,在这里为什么一定是最优/最小呢? 这里 E E E是关于 w w w 和 b b b 的凸函数,当它关于 w w w 和 b b b 的导数均为0时,得到 w w w和 b b b的最优解。这里其实是二元函数无条件极值的相关内容,具体证明指路:线性回归证明 
在证明过程中可以清楚地看到,此处 A C − B 2 > 0 AC-B^2>0 AC−B2>0 , 且 A > 0 A>0 A>0 ,可取极小值。 再拓展到多个属性的情况,如果有d个属性,那线性回归模型就有d+1个参数(d个w和1个b),在参数很多成千上万的情况下是非常麻烦的,一方面计算消耗大,另一方面,许多任务中可能会遇到大量的变量,数目可能会超过样例数,这样会求出多组解。 3. 广义线性回归线性模型的预测值逼近真实标记y,就得到了线性回归模型: y = w T x + b y=\textbf{w}^T\textbf{x}+b y=wTx+b 而模型预测值也可以逼近 y的衍生物,考虑单调可微函数 g ( ⋅ ) g(\cdot) g(⋅) ,令 y = g − 1 ( w T x + b ) y=g^{-1}(\textbf{w}^T\textbf{x}+b) y=g−1(wTx+b)这样的模型成为 “广义线性模型” 。 对数线性回归 就是典型的广义线性模型,它以输出标记y的对数作为逼近的目标,实际上是在让 e w T x + b e^{\textbf{w}^T\textbf{x}+b} ewTx+b逼近 y,即 l n y = w T x + b lny=\textbf{w}^T\textbf{x}+b lny=wTx+b 在形式上仍然是线性回归,但实质上已经是在求取输入空间到输出空间的非线性函数映射。 三、对数几率回归(逻辑回归) 1. 模型建立机器学习的几个基本任务:回归、聚类、分类、优化。上面用线性模型解决了回归问题,那如果要做的是分类任务该怎么办呢? ——利用广义线性模型,找一个单调可微的函数,把真实标记 y 与线性回归模型的预测值联系起来。 对于二分类问题,其输出标记为{0,1},而线性回归模型产生的预测值是实值,于是需要将其转换为0-1值,最理想的是“单位阶跃函数”: y = { 0 , z < 0 0.5 , z = 0 1 , z > 0 y=\begin{cases} 0, & z0 \end{cases} y=⎩⎪⎨⎪⎧0,0.5,1,z0但是“单位阶跃函数”不连续,所以要找一个一定程度上近似的替代函数,对数几率函数(logistic function)就是常用的替代函数,它是一种 sigmoid函数: y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1 sigmoid函数即形似S的函数,对数几率函数是它的重要代表,在神经网络中有重要应用。它的作用相当于将z值挤压到0和1附近。 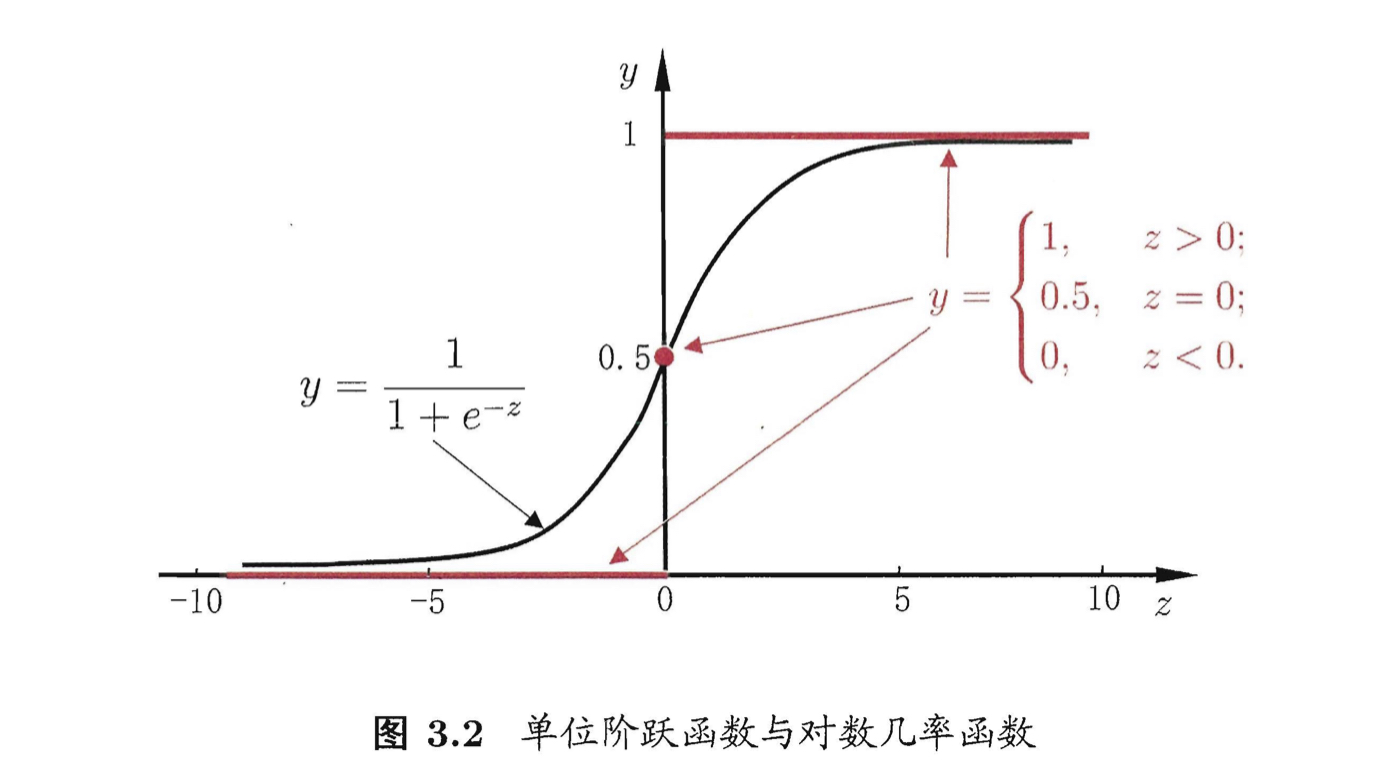
把对数几率函数作为 g − 1 ( ⋅ ) g^{-1}(\cdot) g−1(⋅)代入,得到 y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-(\textbf{w}^T\textbf{x}+b)}} y=1+e−(wTx+b)1 l n y 1 − y = w T x + b ln\frac{y}{1-y}=\textbf{w}^T\textbf{x}+b ln1−yy=wTx+b若 y 作为样本为正例的可能性,则 1-y 为样本为负例的可能性,二者相处为正例的相对可能性,对 [几率] 取对数则得到 [对数几率] (log odds,logit) 一句话总价以上工作:用线性回归模型的预测结果去毕竟真实标记的对数几率,得到“对数几率回归模型”(logistic regression,logit regression),虽然称作回归模型,但是用于解决 分类问题。 注:西瓜书中称为 “对数几率回归 ”,实际上就是我们常说的 “逻辑回归 ” ● 逻辑回归有一些明显的优点: 直接对分类可能性进行建模,无需实现假设数据分布,避免了假设分布不准确带来的问题;不仅可以预测出类别,还可以得到近似概率预测,对于许多需利用概率辅助决策的任务很有用;对数几率函数是任意阶可到的凸函数,有很好的数学性质。 2. 参数估计下面的工作就是要确定 w 和 b \textbf{w}和b w和b 。——极大似然法(maximum likelihood method) 参数估计包括点估计和区间估计,而点估计主要有 矩估计法和极大似然估计法,极大似然估计法是建立在极大似然原理基础上的。所谓极大似然,可直观理解为“最大可能性”,即令每个样本属于其真实标记的可能性越大越好。 设一个随机试验有若干可能结果 A 1 , A 2 , . . . , A n A_1,A_2,...,A_n A1,A2,...,An,若在一次结果中 A k A_k Ak 出现,则认为 A k A_k Ak 出现的概率较大,那未知参数的取值应当满足 A k A_k Ak 发生概率最。 似然函数 设 X 1 , X 2 , . . . , X N X_1,X_2,...,X_N X1,X2,...,XN 为来自总体X的简单随机样本, x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn 为样本观测值,称 L ( θ ) = ∏ i = 1 n p ( x i , θ ) L(\theta)=\prod\limits_{i=1}^np(x_i,\theta) L(θ)=i=1∏np(xi,θ) 为参数 θ \theta θ 的似然函数,实际上就是样本 X 1 , X 2 , . . . , X N X_1,X_2,...,X_N X1,X2,...,XN 恰好取观测值 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn (或其邻域)的概率。 存在一个只与观测值 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn 有关是实数 θ ^ ( x 1 , x 2 , . . . , x n ) \hat{\theta}(x_1,x_2,...,x_n) θ^(x1,x2,...,xn) ,使 L ( θ ^ ) = m a x L ( θ ) L(\hat{\theta})=max\ L(\theta) L(θ^)=max L(θ) ,则称 θ ^ ( x 1 , x 2 , . . . , x n ) \hat{\theta}(x_1,x_2,...,x_n) θ^(x1,x2,...,xn) 为参数 θ \theta θ 的最大似然估计值。 再利用经典的数值优化算法如梯度下降法、牛顿法求其最优解。 四、线性判别分析LDA给定训练样例集,设法将样例投影到一条直线上,使得: 同类样例的投影点尽可能接近——最小化协方差 异类样例投影点尽可能远离——最大化中心距离 在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。 五、多分类学习遇到多分类学习任务,一种常用的策略是:利用二分类器解决多分类问题。基本思路是:拆解法 ——先拆分再集成。此处只介绍拆分策略。 经典拆分策略 一对一(One vs. One , OvO):假设有N个类别,这N个类别两两配对,每次令其中一个作为正例,另一个作为反例,产生 N ( N − 1 ) 2 \frac{N(N-1)}{2} 2N(N−1) 个二分类任务。一对其余(One vs. Rest , OvR):每次将一个类的样例作为正例,其他所有类作为反例,训练 N N N 个分类器。多对多(Many vs. Many , MvM):每次将若干类作为正类,其他若干类作为反类,正反类构造不能随意选取,而是有一定的设计——纠错输出码ECOC。 OvOOvR分类器个数N(N-1)/2N训练耗费更大的内存空间和测试时间较小的内存空间和测试时间所需数据每个二分类器只用两类数据所有数据都被使用面临问题如果样本数少,每个分类器训练样本过少,会过拟合样本数据可能会非常不平衡ECOC纠错输出码 将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性。而“容错性”也是其之所以被称为纠错输出码的原因,ECOC编码对分类器的错误有一定的容忍和修正能力。下面将通过例子来进行展示。 ECOC编码主要有两类: 二元码:将每个类别分别指定为正类和反类。三元码:在正、反类之外,还制定 “停用类”。
如图3.5所示, f i f_i fi 表示分类器, C i C_i Ci 表示类别样本,横向来看就是一个类别样本在不同分类器中的分类结果,纵向来看就是一个分类器对不同样例的分类结果。 测试样例在 f 1 f_1 f1中被分为负类,在 f 3 f_3 f3 中被认为是正类,它最终的编码为(-1,-1,+1,-1,+1),将这个编码和 C 1 C_1 C1 到 C 4 C_4 C4 的编码进行比较,并归入与其最接近的类。而衡量接近与否也有不同的指标,主要有海明距离和欧式距离。 海明距离可以直观理解为,测试用例和某一已知类别在各个分类器中结果不同的次数,例如测试用例和 C 1 C_1 C1 在 f 1 f_1 f1, f 2 f_2 f2, f 3 f_3 f3 中结果不同,则海明距离为3,碰到图3.5(b)中不标+1、-1的停用类,则计为0.5 。 计算测试用例和 C 1 C_1 C1 的欧式距离,每一位编码相减,再平方相加。 C 1 C_1 C1 的编码为(-1,+1,-1,+1,+1),测试样例为(-1,-1,+1,-1,+1),故欧式距离为 [ ( − 1 ) − ( − 1 ) ] 2 + [ 1 − ( − 1 ) ] 2 + [ ( − 1 ) − 1 ] 2 + [ 1 − ( − 1 ) ] 2 + ( 1 − 1 ) 2 = 2 3 \sqrt{[(-1)-(-1)]^2+[1-(-1)]^2+[(-1)-1]^2+[1-(-1)]^2+(1-1)^2}=2\sqrt{3} [(−1)−(−1)]2+[1−(−1)]2+[(−1)−1]2+[1−(−1)]2+(1−1)2 =23 ,停用类的编码计为0. 可以看到,图3.5(a)中,测试用例应当被归为 C 3 C_3 C3 ,虽然 f 2 f_2 f2 分类器在预测时出错了,但基于编码最终还是得到了正确的结果。一般ECOC码越长,纠错能力越强,但并不是越多越好。一方面意味着所需要的分类器越多,计算和存储开销都会增大;另一方面,有限类别数可能的组合数目也是有限的,码长超过一定范围后就失去了意义。 六、类别不平衡问题类别不平衡为什么会造成问题?好比有1000个样例,其中998个为正例,2个反例,那么学习方法只需返回一个永远将新样本预测为正例1的学习器也可以有高达99.8%的正确率,但是这样的学习器没有任何价值。 如何处理类别不平衡问题 首先,明确线性模型解决分类问题的原理:用 y = w T x + b y=\textbf{w}^T\textbf{x}+b y=wTx+b 对新样本 x \textbf{x} x 进行预测,得到的 y 值与阈值进行比较,一般是以0.5为阈值。当 y>o.5判别为正例,否则为负例。 这个阈值实际表明分类器认为真实的正反例可能性相同,即分类器决策规则为: 若 y 1 − y > 1 , 则 预 测 为 正 例 若\frac{y}{1-y}>1,则预测为正例 若1−yy>1,则预测为正例 而正反例可能性不同时,可以调节这个阈值为观测几率 (以训练集中正反例比例为观测几率,这是基于假设“训练集是真实样本总体的无偏采样”从而推断出真实几率,但是这个假设往往并不成立) ,若 m + m^+ m+ 为正例数目, m − m^- m− 为反例数目,则分类器决策规则为: 若 y 1 − y > m + m − , 则 预 测 为 正 例 若\frac{y}{1-y}>\frac{m^+}{m^-},则预测为正例 若1−yy>m−m+,则预测为正例 进行一定变换,也就是 若 y ′ 1 − y ′ = y 1 − y × m − m + > 1 , 则 预 测 为 正 例 若\frac{y^\prime}{1-y^\prime}=\frac{y}{1-y}\times\frac{m^-}{m^+}>1,则预测为正例 若1−y′y′=1−yy×m+m−>1,则预测为正例 ● 目前有三类做法: 欠采样,去除一些样例使正反例平衡,代表算法EasyEnsemble,将反例划分成若干个集合供不同学习器使用。若直接随意丢弃可能会丢失重要信息;过采样,增加一些样例使正反例平衡,代表算法SMOTE,对正例进行插值产生额外的正例。如果直接重复采样可能造成严重的过拟合;阈值转移。 若 y ′ 1 − y ′ = y 1 − y × m − m + > 1 , 则 预 测 为 正 例 若\frac{y^\prime}{1-y^\prime}=\frac{y}{1-y}\times\frac{m^-}{m^+}>1,则预测为正例 若1−y′y′=1−yy×m+m−>1,则预测为正例 |
【本文地址】