| 【奶奶看了都会】云服务器部署开源ChatGLM | 您所在的位置:网站首页 › love修改器 › 【奶奶看了都会】云服务器部署开源ChatGLM |
【奶奶看了都会】云服务器部署开源ChatGLM
|
1.背景 大家好啊,我是小卷。 最近ChatGPT不仅发布了GPT-4,而且解除封印可以联网了。不得不赞叹AI更新迭代的速度真快,都跟不上节奏了。但是大家也注意到了吧,随着ChatGPT的每次更新,OpenAI对其开放使用的限制也越来越大。之前国内网随便访问GPT3,现在动不动就封号 所以,今天就来教大家部署国内清华大学开源的ChatGLM-6B。简单介绍下,ChatGLM是对话语言模型,对中文问答和对话进行了优化。当前训练模型有62亿参数,后续还会推出1300亿参数的大模型,期待国内的ChatGLM能越做越强大。 ChatGLM的开源地址:THUDM/ChatGLM-6B 废话不多说了,直接上效果,以下是由ChatGLM中文对话的结果(不是ChatGPT哦) (PS:文末给大家准备了ChatGLM的免费体验地址 和 算力平台免费体验方式,一定看到文章结尾哦)  2.准备工作 2.准备工作官方说明ChatGLM对硬件的配置要求至少13G的显存 要准备的东西如下: 一台GPU云服务器(16GB显存,32G内存)云服务器上已安装好显卡驱动cuda和pytorch框架(平台都有现成的镜像,直接安装即可)再来说说服务器厂商的选择,GPU服务器比较贵,所以小卷对比了一些大厂和小厂的GPU规格,这里只看配置符合要求且价钱合适的 厂商配置价钱优势阿里云4核-15G内存-16显存NVIDIA T41878/月大厂服务,但是价钱太贵腾讯云10核-40G- NVIDIA T48.68/小时大厂服务,但独占1颗GPU价钱略高华为云8核-32G-16显存NVIDIA T43542/月太贵mistGPU8核-32G-24G显存NVIDIA 30904.5/小时缺点:只有1GB免费存储揽睿星舟10核-40G-24G显存NVIDIA 30901.9/小时推荐,配置高且价钱低,现在NVIDIA 3090有特价我们这里使用揽睿星舟这个算力平台的服务器,价钱就是优势哦。 需要注意的是,GPU服务器要选按量计费,就是你用的时候按使用时长计费,不用时关掉就不会计费 3.服务器配置这一步购买服务器并安装环境,比较简单 3.1注册使用打开揽睿星舟官网注册地址: 注册账号时邀请码填写4104,这样平台会给你免费充值一笔钱 咱们就可以免费体验服务器了。右上角也可以给自己账户充值  3.2购买服务器并安装镜像 3.2购买服务器并安装镜像在网站的算力市场购买需要的服务器配置,这里我选的是3090-24G这款,点击使用按钮进入镜像安装界面  运行环境镜像选公共镜像 -> pytorch 直接用最新的就行,然后高级设置里选择预训练模型chatglm-6b(这样会预先加载chatGLM的模型到服务器,无需再手动下载)然后创建实例(确保自己账号里有足够的余额)  等待5分钟左右,工作空间就创建好了,点击进入 -> JupyterLab 进入服务器,接下来就准备ChatGLM的安装就行了  4.部署ChatGLM4.1Git加速配置 4.部署ChatGLM4.1Git加速配置为了避免git clone太慢,提前在命令行设置git学术资源加速 # 执行下面2条命令,设置git学术资源加速 git config --global http.proxy socks5h://172.16.16.39:8443 git config --global https.proxy socks5h://172.16.16.39:8443后面的步骤中再执行git clone命令就不会卡住了。 要取消git学术加速也简单,执行下面的命令(所有步骤执行完后再取消哦~) # 取消git学术资源加速 git config --global --unset https.proxy git config --global --unset http.proxy4.2下载ChatGLM源代码进入Jupyter的页面后,可以看到2个目录,对目录做下说明: data目录,存放数据,平台共享的imported_models目录,存放预训练模型,即创建工作空间时你选择的模型点击data目录下,可以看到ChatGLM-6B文件夹,里面是ChatGLM的源代码。 如果没有ChatGLM-6B目录,那么我们这一步需要下载代码,操作如下: 页面打开一个Terminal终端,在Terminal终端执行命令 git clone https://github.com/THUDM/ChatGLM-6B.git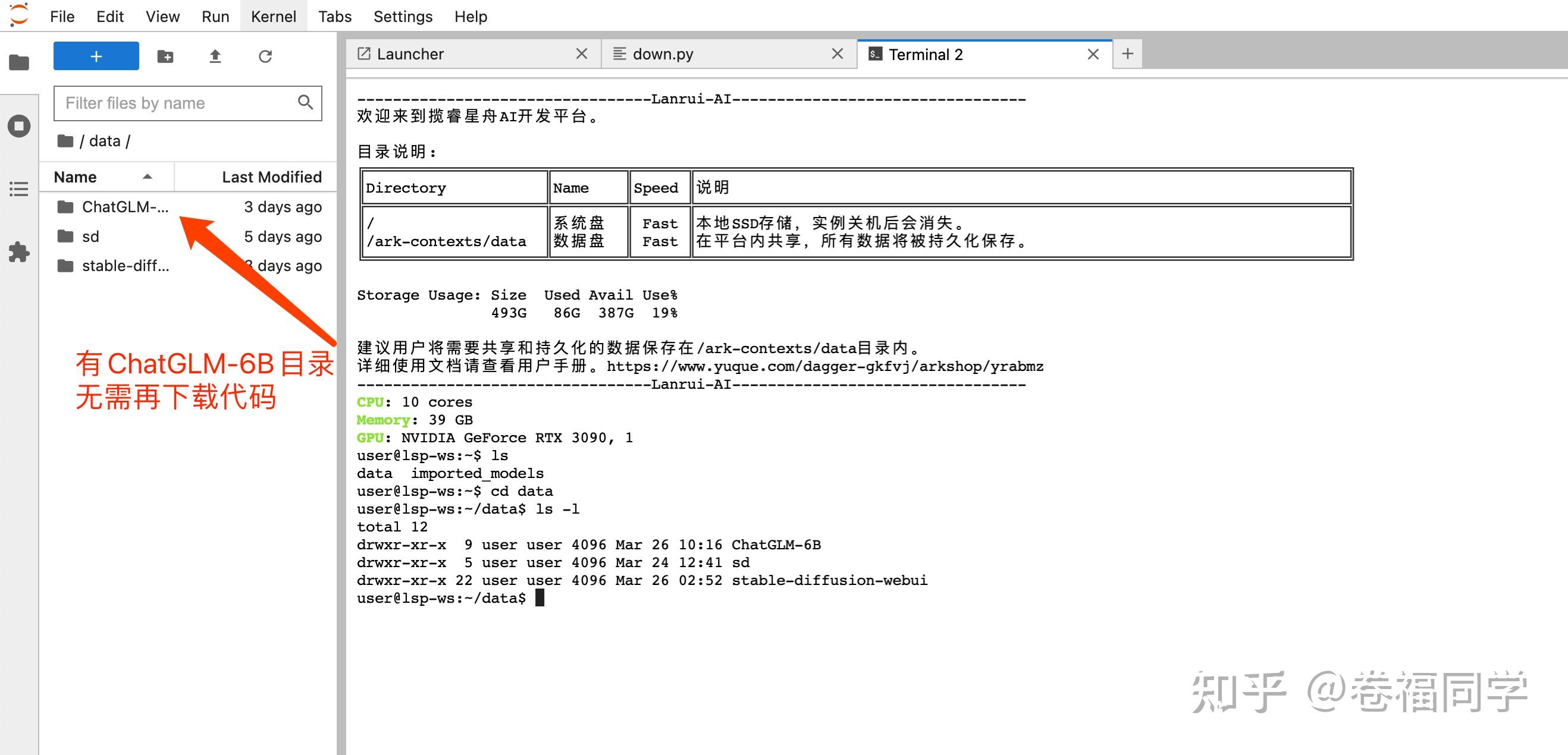  4.3 安装依赖 4.3 安装依赖1.执行命令切换到ChatGLM-6B的目录 cd ChatGLM-6B2.接着修改requirements.txt文件,把后续所有需要的依赖都加上,下面的配置加在文件末尾即可,如果文件里已加上这3个依赖,无需再修改。 chardet streamlit streamlit-chat3.加完之后save保存下文件,如图  4.接着命令行执行下面命令安装依赖 # 使用默认镜像源下载会超时,这里用了清华的pip镜像源地址 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ 这一步可能会执行报错 ERROR: Could not install packages due to an OSError: Missing dependencies for SOCKS support. 解决方法:切换到root用户后再执行命令 # 切换root用户 sudo su # 重新执行 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/4.4 启动脚本修改因为模型是单独文件夹存储的,所以需要修改启动脚本中读模型文件的代码为了能从公网访问我们的ChatGLM,需要修改监听地址为0.0.0.0,端口为27777,这个是揽睿星舟平台的调试地址修改步骤: 1.修改web_demo2.py文件中的模型路径,替换为模型的绝对路径,修改方法如下: 修改前的代码 tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()修改后的代码 tokenizer = AutoTokenizer.from_pretrained("/home/user/imported_models/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("/home/user/imported_models/chatglm-6b", trust_remote_code=True).half().cuda()修改完后ctrl + s保存一下 4.5启动ChatGLM在ChatGLM-6B目录下,命令行执行 python3 -m streamlit run ./web_demo2.py --server.port 27777 --server.address 0.0.0.0启动ChatGLM的webui界面  看到http://0.0.0.0:27777字样说明成功启动了 5.使用我们需要从浏览器访问刚部署的服务,回到揽睿星舟平台 在工作空间页面上点击自定义服务拷贝调试链接,然后把拷贝的链接在浏览器上打开 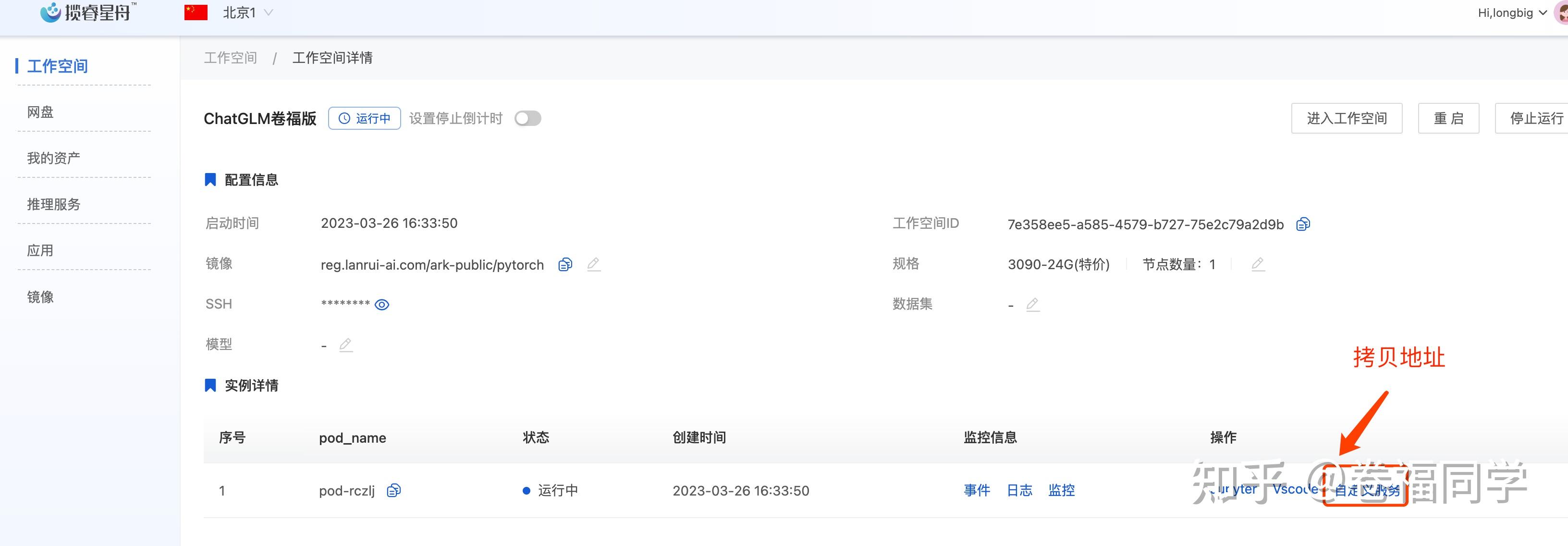  然后你就可以在这个页面开始对话了 注意第一次对话时,程序会加载模型文件,耗时会比较长,可以从刚才启动的命令行查看加载进度。 等第一次加载完成后,后面再对话,响应就很快了 6.对话效果到这一步,所有安装部署过程就成功完成了,我们来看看效果吧,拷贝的链接在手机端也能打开,下面是手机端的效果  7.关闭服务以及重启服务因为我们的服务按使用量收费的,所以不用时在页面上点击停止运行即可 7.关闭服务以及重启服务因为我们的服务按使用量收费的,所以不用时在页面上点击停止运行即可 然后想重新运行服务的时候,点工作空间页面上的启动按钮。工作空间重新创建后,进入Jupyter,通过命令行再次启动 # 进入ChatGLM-6B目录
cd data/ChatGLM-6B/
# 没挂系统盘时,要重新安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 启动服务
python3 -m streamlit run ./web_demo2.py --server.port 27777 --server.address 0.0.0.0 然后想重新运行服务的时候,点工作空间页面上的启动按钮。工作空间重新创建后,进入Jupyter,通过命令行再次启动 # 进入ChatGLM-6B目录
cd data/ChatGLM-6B/
# 没挂系统盘时,要重新安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 启动服务
python3 -m streamlit run ./web_demo2.py --server.port 27777 --server.address 0.0.0.0 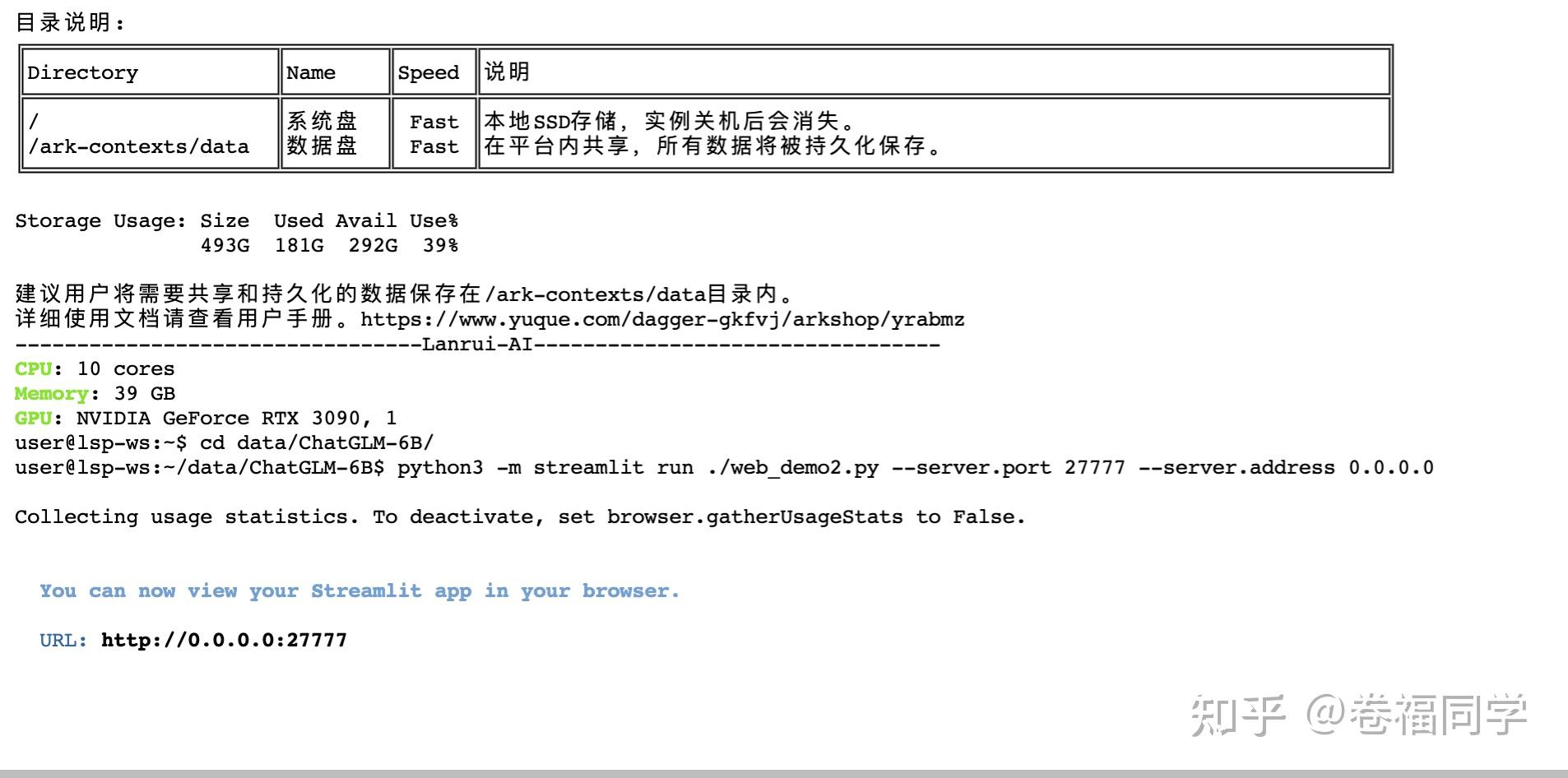 8.免费体验ChatGLM 8.免费体验ChatGLM小卷给大家准备了2个免费体验的方式: (1)通过下面链接注册平台账号,邀请码填4104,平台会免费充点钱,然后可自行部署体验。 (2)小卷给大家准备了自己的ChatGLM体验地址,能用几天。给这篇文章点赞收藏后,关注小卷,找小卷拿哦~ |
【本文地址】