| linux 指令使用大全 | 您所在的位置:网站首页 › linux常用命令jps › linux 指令使用大全 |
linux 指令使用大全
|
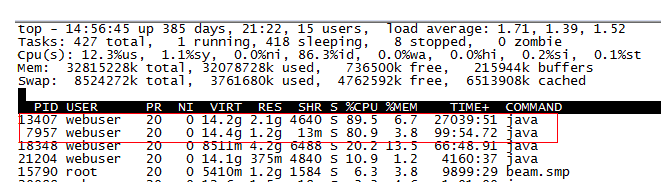
目录 md5sum su与su - 的区别 从windows上传下载文件 rz参数 sz参数 Linux命令行中的 符号 '\' ,' --'的作用 profile、bash_profile、bashrc的用途与区别 /和~的区别 Ifconfig: Ping 查看端口占用情况 查看端口属于哪个程序 lsof命令详解 ls linux多命令的顺序执行 文件下载 mkdir cd pwd touch vi/vim echo cat tac cp 软连接与硬链接 硬链接(Hard Link) 软链接 区别 挂载点 目录 ulimit java程序相关的Linux指令 jps jstack jstack查找高度占用CPU的java代码步骤 Jmap 总结 ps -ef|grep详解 rm 重定向(> />>/ ls 默认列出当前目录下的所有非隐藏文件。 -> ls -l(long)以长格式查看文件。 简写ll -> ls -d(directorys)查看目录。简写 ld 下面的以此类推 -> ls -F:给不同文件的结尾加标识。例如目录结尾会加"/" -> ls -p:只给目录结尾加标识"/" -> ls -a:显示所有文件,包括隐藏文件,默认点开头的文件是隐藏文件 -> ls -r:倒排序 -> ls -t:按修改时间排序,一般rt结合,查看最近被修改的文件。 -> \ls --color=auto:显示颜色,默认已经设置到别名里 -> ls -i /data/:显示inode,文件索引 -> ls -lh /data/:h参数表示人类可读,会将文件大小换成k、M等易读方式 -> ls -l --time-style=long-iso /data:规范时间显示(2016-03-04) linux多命令的顺序执行当我们需要一次执行多个命令的时候,命令之间需要用连接符连接,不同的连接符有不同的效果。 (1) ; 分号,没有任何逻辑关系的连接符。当多个命令用分号连接时,各命令之间的执行成功与否彼此没有任何影响,都会一条一条执行下去。 (2) || 逻辑或,当用此连接符连接多个命令时,前面的命令执行成功,则后面的命令不会执行。前面的命令执行失败,后面的命令才会执行。 (3) && 逻辑与,当用此连接符连接多个命令时,前面的命令执行成功,才会执行后面的命令,前面的命令执行失败,后面的命令不会执行,与 || 正好相反。 (4) | 管道符,当用此连接符连接多个命令时,前面命令执行的正确输出,会交给后面的命令继续处理。若前面的命令执行失败,则会报错,若后面的命令无法处理前面命令的输出,也会报错。 文件下载wget http://file.tgz mac下安装wget命令 curl http://file.tgz mkdir简述:创建目录。 -> mkdir /data 在根目录下创建data目录 -> mkdir -p /aa/bb/cc:递归创建目录 cd简述:切换目录 -> cd /etc 从当前目录切换到/etc路径下 Cd - 返回到执行cd之前的目录 pwd简述:打印工作目录。注意 pwd要大写 -> pwd (print work directory) 显示当前所在路径 -> echo $PWD:可以看到这个变量的值 touch简述:不存在就创建文件,存在则更新文件时间戳信息。 -> touch /data.txt 直接在/目录下创建data.txt文件。 Touch 后面可以一次创建多个文件夹或文件 文件或文件夹之间用空格隔开 例如 touch 1.txt 2.txt 3.txt -> cd /; touch data.txt 切换到/目录下,创建data.txt文件 vi/vimEsc进入命令格式 退出Vi的几种方法 在命令模式中,连按两次大写字母Z,若当前编辑的文件曾被修改过,则Vi保存该文件后退出,返回到shell;若当前编辑的文件没被修改过,则Vi直接退出, 返回到shell,在末行模式下,输入命令 :w Vi保存当前编辑文件,但并不退出,而是继续等待用户输入命令。在使用w命令时,可以再给编辑文件起一个新的文件名。 :w newfile 此时Vi将把当前文件的内容保存到指定的newfile中,而原有文件保持不变。若newfile是一个已存在的文件,则Vi在显示窗口的状态行给出提示信息: File exists (use ! to override) 此时,若用户真的希望用文件的当前内容替换newfile中原有内容,可使用命令 :w! newfile 否则可选择另外的文件名来保存当前文件。 在末行模式下,输入命令 :q 系统退出Vi返回到shell。若在用此命令退出Vi时,编辑文件没有被保存,则Vi在显示窗口的最末行显示如下信息: No write since last change (use ! to overrides) 提示用户该文件被修改后没有保存,然后Vi并不退出,继续等待用户命令。若用户就是不想保存被修改后的文件而要强行退出Vi时,可使用命令 :q! Vi放弃所作修改而直接退到shell下。 在末行模式下,输入命令 :wq Vi将先保存文件,然后退出Vi返回到shell。 在末行模式下,输入命令 :x 该命令的功能同命令模式下的ZZ命令功能相同。 -> vi /data.txt 打开data文件,打开默认为命令模式不可编辑。点击a或i进入插入状态,点击Esc退出编辑状态进入命令状态可以执行以:冒号后面执行以下命令。 命令状态按:wq保存退出。(wq为write quit) dd:光标点住哪一行直接删除一行或剪切一行 n dd 删除或剪切从光标开始的n行 p 粘贴 yy复制 Ctrl +z 挂起在后台 ,相当于最小化 Fg 取消挂起 ,相当于最大化 > set nu显示行号 记住不带/ -> set nonu 不显示行号 -> G或]]或:$ 光标移动到文件的最后一行 -> gg或[[或:0 光标移动到文件的第一行- -> o 开启新一行 I 光标调到开头 A 光标调到结尾 :n 第你 -> $或end键:从光标位置移动到当前行的结尾 -> u:取消上一次的动作-> /:向下搜索,继续搜索按n,配置文件时,可以搜索关键字 反向搜索按N-> ?:向上搜索,继续搜索按n,反向搜索按N 替换:%s/旧字符串/新的字符串/g 其中 % 匹配所有 s 从开始的地方开始 g 是全部的意思 S:start g:globle echo简述:打印。 -> echo ‘I like linux’ 打印后边的字符串 -> echo -n "abc"; echo "456":不换行输出 -> echo -e "123\t456":加特殊符号,比如制表符\t,换行\n等 注意 -n和-e要和echo之间有空格或制表符 cat简述:查看文件内容。 -> cat /data.txt 查看data.txt文件中的内容-> cat >>/test/test.txt和 cat test{1,2}.txt >/tmp/aa.txt:将test1.txt和test2.txt文件内容合并到aa.txt里面-> cat -T test.txt:区分tab键和空格,tab键会被^I替代-> cat -E test.txt:会在行尾加$符号,空行也会有 tac简述:和cat相反,倒序读取文件。最后一行先输出,然后倒数第二行…… rev 简述:每行倒读 -> echo 1234|rev:输出是4321 简述:显示行号 -> nl /data.txt:显示行号 cp简述:拷贝命令,可以拷贝文件或目录。 -> cp /data/aa.txt /test/ :将/data/aa.txt文件拷贝到/test/目录下。-> cp –r /data /test/ :将/data目录递归拷贝到/test/下面。-> cp –a /data /test/ :-a参数相当于-pdr -p:连同档案属性一块拷贝,而非默认属性。 -d: 若原文件为链接文件,则复制链接文件属性而非档案本身】 软连接与硬链接什么是目录 Linux 文件系统是树状结构的。根目录下存在一系列子目录。目录里边有文件或者子目录。 但问题在于: 目录是什么?文件又是什么?文件是:数据 + 属性(比如名字、创建时间、所有者之类) 目录是:一个列表,列表中的每一项是:inode –> filename Linux 文件系统把硬盘分为三个部分:超级块、inode 列表、数据区 inode 指示:该文件的数据存放在数据区的哪些块内。因为这个“映射”关系不能变更,因此,inode 相当于代表着文件本身。(值得注意的是,文件名与文件本身不是直接映射起来的,中间隔着 inode) 硬链接(Hard Link)硬链接指通过索引节点来进行连接,在 Linux 为文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号; 硬链接指的就是在 Linux 中,多个文件名指向同一索引节点; 常见用途:通过建立硬链接到重要文件,防止误删,删除其实对应的是删除其中的一个硬链接,当文件对应的硬链接都被删除了,该文件才真正被删除; 注意: 默认情况下,ln 命令产生硬链接; 创建硬链接命令:cp -l 1.txt 2.txt等同于ln 1.txt 2.txt # 为 1.txt 建立硬链接 2.txt [root@centos7 home]# vi 1.txt hello, this is 1.txt! [root@centos7 home]# cp -l 1.txt 2.txt # 为1.txt建立硬链接2.txt,等同于ln 1.txt 2.txt [root@centos7 home]# more 2.txt # 查看2.txt文件中的内容和1.txt文件内容一样 hello, this is 1.txt!这两个文件的索引节点号,可以看见索引号(inode)一样: [root@centos7 home]# ls -li 总用量 69868 33845219 -rw-r--r--. 2 root root 44 1月 21 10:12 1.txt 33845219 -rw-r--r--. 2 root root 44 1月 21 10:12 2.txt [root@centos7 home]# vi 2.txt # 编辑2.txt,在末未添加: hello, this is 2.txt! [root@centos7 home]# more 1.txt # 查看1.txt中是否内容改动 hello, this is 1.txt! hello, this is 2.txt! [root@centos7 home]# rm -f 1.txt # 删除1.txt [root@centos7 home]# more 2.txt # 查看2.txt的内容 hello, this is 1.txt! hello, this is 2.txt! 软链接也成为符号链接(Symbolic Link),类似于 Windows 的快捷方式,其中包含的是另一个文件的位置信息; 软连接就是一个文件的快捷方式,源文件删了 软连接也就失效了 ,创建软连接 会产生一个带有 ->标志,而应,硬链接却没有。 cp -s 2.txt sLink (sLink不用手动创建 会自定生成) 为2.txt文件建立符号链接sLink,等同于ln –s 2.txt sLink [root@centos7 home]# cp -s 2.txt sLink # 为2.txt文件建立符号链接sLink,等同于ln –s 2.txt sLink [root@centos7 home]# ls –li # 可以看到两个文件有不同的索引节点号 总用量 69864 33845219 -rw-r--r--. 1 root root 44 1月 21 10:12 2.txt 36830246 lrwxrwxrwx. 1 root root 5 1月 21 10:21 sLink -> 2.txt [root@centos7 home]# more sLink hello, this is 1.txt! hello, this is 2.txt! [root@centos7 home]# rm -f sLink # 删除符号链接,不影响源文件 [root@centos7 home]# more 2.txt hello, this is 1.txt! hello, this is 2.txt! [root@centos7 home]# rm -f 2.txt # 删除2.txt [root@centos7 home]# ls -li 总用量 69860 36830246 lrwxrwxrwx. 1 root root 5 1月 21 10:21 sLink -> 2.txt [root@centos7 home]# more sLink sLink: 没有那个文件或目录创建符号链接命令:cp -s 2.txt sLink 等同于ln –s 2.txt sLink # 为 2.txt 文件建立符号链接 sLink 符号连接相当于快捷方式。这意味着什么呢? 符号连接是一个文件,一个与被它连接的文件不一样的文件。它有自己的 inode。符号连接的内容应该是一个路径,该路径指示着它连接的文件。这意味着如果该路径的文件被删除了、改名字了,它即将访问不到。如果该路径下的文件被掉包了,它将访问错误的文件。 区别 挂载点只能在同种存储媒体上的文件之间创建硬链接(Hard Link),不能在不同挂载点下的文件间创建硬链接,对于后一种情况,可以使用软链接;(区分不同挂载点与同一挂载点不同目录) 如跨不同的挂载点建立硬链接的报错信息: [root@centos7 home]# ln 2.txt /dev/hLink ln: 无法创建硬链接"/dev/hLink" => "2.txt": 无效的跨设备连接 目录软连接就相当于 win 中的快捷方式即如果软链接一个目录只是一个目录的快捷方式到指定位置,操作系统找这个快捷方式会直接找到真实目录下的文件。但是硬链接的话,相当于镜像的方式,创建一个目录的硬链接之后,操作系统需要把这个目录下所有的文件都要做一次硬链接(复制一份过去),这样操作系统在访问这个链接的时候要不断去遍历,大大增加复杂度,而且很容易进入死循环。 硬链接不能对目录创建受限于文件系统的设计。Linux 文件系统中的目录均隐藏了两个特殊的目录,当前目录和父目录。其实是两个硬链接,若系统运行对目录创建硬链接,则会产生目录环。 ulimitulimit -a 用来显示当前的各种用户进程限制 Linux对于每个用户,系统限制其最大进程数,为提高性能,可以根据设备资源情况, 设置Linux用户的最大进程数,一些需要设置为无限制: 数据段长度:ulimit -d unlimited 最大内存大小:ulimit -m unlimited 堆栈大小:ulimit -s unlimited 选项 [options] 含义 例子 -H 设置硬资源限制,一旦设置不能增加。 ulimit – Hs 64;限制硬资源,线程栈大小为 64K。 -S 设置软资源限制,设置后可以增加,但是不能超过硬资源设置。 ulimit – Sn 32;限制软资源,32 个文件描述符。 -a 显示当前所有的 limit 信息。 ulimit – a;显示当前所有的 limit 信息。 -c 最大的 core 文件的大小, 以 blocks 为单位。 ulimit – c unlimited; 对生成的 core 文件的大小不进行限制。 -d 进程最大的数据段的大小,以 Kbytes 为单位。 ulimit -d unlimited;对进程的数据段大小不进行限制。 -f 进程可以创建文件的最大值,以 blocks 为单位。 ulimit – f 2048;限制进程可以创建的最大文件大小为 2048 blocks。 -l 最大可加锁内存大小,以 Kbytes 为单位。 ulimit – l 32;限制最大可加锁内存大小为 32 Kbytes。 -m 最大内存大小,以 Kbytes 为单位。 ulimit – m unlimited;对最大内存不进行限制。 -n 可以打开最大文件描述符的数量。 ulimit – n 128;限制最大可以使用 128 个文件描述符。 java程序相关的Linux指令jstat 命令格式 jstat - [-t] [-h] [ []]参数解释: Option — 选项,我们一般使用 -gcutil 查看gc情况 vmid — VM的进程号,即当前运行的java进程号 interval– 间隔时间,单位为秒或者毫秒 count — 打印次数,如果缺省则打印无数次 参数interval和count代表查询间隔和次数,如果省略这两个参数,说明只查询一次。假设需要每250毫秒查询一次进程5828垃圾收集状况,一共查询5次,那命令行如下: jstat -gc 5828 250 5option 选项option代表这用户希望查询的虚拟机信息,主要分为3类:类装载、垃圾收集和运行期编译状况,具体选项及作用如下: 常见术语 1、jstat –class : 显示加载class的数量,及所占空间等信息。 Loaded 装载的类的数量 Bytes 装载类所占用的字节数 Unloaded 卸载类的数量 Bytes 卸载类的字节数 Time 装载和卸载类所花费的时间 2、jstat -compiler 显示VM实时编译的数量等信息。 Compiled 编译任务执行数量 Failed 编译任务执行失败数量 Invalid 编译任务执行失效数量 Time 编译任务消耗时间 FailedType 最后一个编译失败任务的类型 FailedMethod 最后一个编译失败任务所在的类及方法 jps参数说明 -q 只显示pid,不显示class名称,jar文件名和传递给main 方法的参数 hollis@hos:/tmp/hsperfdata_hollis$ jps -q 2679 11421-m 输出传递给main 方法的参数,在嵌入式jvm上可能是null, 在这里,在启动main方法的时候,我给String[] args传递两个参数。hollis,chuang,执行jsp -m: hollis@hos:/tmp/hsperfdata_hollis$ jps -m 12062 JpsDemo hollis,chuang-l 输出应用程序main class的完整package名 或者 应用程序的jar文件完整路径名 hollis@hos:/tmp/hsperfdata_hollis$ jps -l 12356 sun.tools.jps.Jps 2679 /home/hollis/tools/eclipse//plugins/org.eclipse.equinox.launcher_1.3.0.v20130327-1440.jar 12329 com.JavaCommand.JpsDemo-v 输出传递给JVM的参数 在这里,在启动main方法的时候,我给jvm传递一个参数:-Dfile.encoding=UTF-8,执行jps -v: hollis@hos:/tmp/hsperfdata_hollis$ jps -v 2679 org.eclipse.equinox.launcher_1.3.0.v20130327-1440.jar -Djava.library.path=/usr/lib/jni:/usr/lib/x86_64-linux-gnu/jni -Dosgi.requiredJavaVersion=1.6 -XX:MaxPermSize=256m -Xms40m -Xmx512m 13157 Jps -Denv.class.path=/home/hollis/tools/java/jdk1.7.0_71/lib:/home/hollis/tools/java/jdk1.7.0_71/jre/lib: -Dapplication.home=/home/hollis/tools/java/jdk1.7.0_71 -Xms8m 13083 JpsDemo -Dfile.encoding=UTF-8PS:jps命令有个地方很不好,似乎只能显示当前用户的java进程,要显示其他用户的还是只能用unix/linux的ps命令。 jps是我最常用的java命令。使用jps可以查看当前有哪些Java进程处于运行状态。如果我运行了一个web应用(使用tomcat、jboss、jetty等启动)的时候,我就可以使用jps查看启动情况。有的时候我想知道这个应用的日志会输出到哪里,或者启动的时候使用了哪些javaagent,那么我可以使用jps -v 查看进程的jvm参数情况。 jstackstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源 jstack查找高度占用CPU的java代码步骤第一步:执行top命令 ,找到最耗CPU的java线程
找到最耗CPU的java线程 ps -mp pid -o THREAD,tid,time #或者 #ps -Lfp pid 执行ps -mp 7957 -o THREAD,tid USER %CPU PRI SCNT WCHAN USER SYSTEM TID webuser 85.6 - - - - - - webuser 0.0 19 - futex_ - - 7987 webuser 0.0 19 - futex_ - - 7988 webuser 0.0 19 - futex_ - - 7989 webuser 0.0 19 - futex_ - - 7990 webuser 0.0 19 - futex_ - - 7991 webuser 74.3 19 - - - - 7992 webuser 0.5 19 - futex_ - - 7993可以看出是在id为7957的进程中id为7992的线程高度占用cpu。 这个时候我们就找到具体哪段代码有问题! 我们先使用jstack命令把java堆栈信息打印到一个文件中。 jstack 7957 > test.txt 接着执行: grep `printf "%x\n" 7992` test -A 30 Jmapjmap是JDK自带的工具软件,主要用于打印指定Java进程(或核心文件、远程调试服务器)的共享对象内存映射或堆内存细节 用法摘要 Usage: jmap [option] (to connect to running process) jmap [option] rm /test/aa.txt :删除/test/aa.txt文件。 不加参数会提示确认删除。-> rm –f /test/aa.txt :强制删除,不会出提示。 -> rm –r /test :删除目录,目录下若有文件,则每个文件都会提示,可以加f参数 重定向(> />>/> 追加内容到文件-> echo ‘I like linux’>/data.txt 如果data.txt不存在则创建 并把内容输入进文件。如果文件存在则覆盖内容。 -> echo ‘I like linux’>>/data.txt 追加内容到文件尾部。 -> echo ‘aa bb cc’>>/data.txt 追加多行内容。 -> cat >>/data.txt和或1> 输出重定向:把前面输出的东西输入到后边的文件中,会清除文件原有内容。-> >>或1> 追加重定向:把前面输出的东西追加到后边的文件尾部,不会清除文件原有内容。-> 0 错误重定向:把错误信息输入到后边的文件中,会删除文件原有内容。-> 2>> 错误追加重定向:把错误信息追加到后边的文件中,不会删除文件原有内容。 箭头的指向就是数据的流向。 数字0表示标准输入(stdin),默认可以不用写。 数字1表示正常输出(stdout)。 数字2表示标准错误输出(stderr) -> echo 1 2 3 4 >/data.txt xargs –n 2 echo girl >a.txt 2>a.txt 将正确或者错误信息都输入到 a.txt。echo girl >a.txt 2>&1 和上面的意思一样,不同的写法,这个常用。 echo girl &>a.txt 和上面意思一样,正确和错误信息都放入a.txt man简述:查看命令的帮助信息。 -> man mv:查看mv命令的帮助信息 xargs简述:从标准输入获取内容创建和执行命令。 -n 接数字相当于分组。 -> echo 1 2 3 4 >/data.txt xargs –n 2 test.log“或"echo "" > test.log"或"echo > test.log" more,less,clearn more,less命令 这两个命令用于查看文件,如果一个文件太长,显示内容超出一个屏幕,用cat命令只能看到最后的内容,用more和less两个命令可以分页查看。more指令可以使超过一页的文件内容分页暂停显示,用户按键后才继续显示下一页。而less除了有more的功能以外,还可以用方向键往上或往下的滚动文件,更方便浏览阅读。 less的常用动作命令: less 在查看之前不会加载整个文件。可以尝试使用 less 和 vi 打开一个很大的文件,你就会看到它们之间在速度上的区别。 在 less 中导航命令类似于 vi。 当使用命令 less file-name 打开一个文件后,可以使用下面的指令操作所打开的文件。 搜索 //关键字 就可以搜索关键字 ,比如 /MAIL表示在文件中搜索MAIL单词 回车键 向下移动一行; y 向上移动一行; 空格键 向下滚动一屏; 下面的,命令要和shift一起使用 b 向上滚动一屏; d 向下滚动半屏; h less的帮助; u 向上洋动半屏; w 可以指定显示哪行开始显示,是从指定数字的下一行显示;比如指定的是6,那就从第7行显示; g 跳到第一行; G 跳到最后一行; p n% 跳到n%,比如 10%,也就是说比整个文件内容的10%处开始显示; v 调用vi编辑器; q 退出less !command 调用SHELL,可以运行命令;比如!ls 显示当前列当前目录下的所有文件; n clear命令 clear命令是用来清除当前屏幕显示的,不需任何参数,和dos下的cls命令功能相同。 Tail和head命令head命令是用来查看具体文件的前面几行的内容,具体格式如下: head : 你可以通过head命令查看具体文件最初的几行内容,该命令默认是前10行内容,如果你想查看前面更多内容,你可以通过一个数字选项来设置,head-20 例如 head -20 install.log 通过上面命令你可以查看install.log这个文件前面20行的内容 与head命令相反,tail命令是用来查看具体文件后面几行的内容,默认情况下,是查看该文件尾10行的内容,同样,如果想查看后面更多内容,也是通过数字选项来设置,例如 tail -20 install.log tail -n 100 查看文件的最后100行 你还可以使用 tail 来观察日志文件被更新的过程。使用 -f 选项,tail 会自动实时 -F删除后 重新创建名字相同的文件也可以继续监视。 地把打开文件中的新消息显示到屏幕上。例如,要即时观察 /var/log/messages的变化,以根用户身份在 shell 提示 下键入以下命令: tail -f /var/log/messages wc [option] filename统计文件字数功能:统计文件中的文件行数、字数和字符数。 选项: -l lines 统计文件的行数 Wc -l 1.txt 回车 -w words 统计文件的单词数 (英文单字) -c bytes 统计文件的字节数 -m chars 统计文件字符数 文件的拷贝,剪贴 ,重命名拷贝 拷贝文件: cp 文件目录 粘贴的文件目录/[重命名] 拷贝文件夹 cp 文件夹目录 粘贴的文件目录/[重命名] -r 剪切 mv 剪切 文件目录 粘贴的文件目录/[重命名] 其中MV 默认递归 Rename 重命名 rename支持通配符 ? 可替代单个字符 * 可替代多个字符 把一txt结尾的文件后缀改成tar rename .txt .txt.bar * Linux下对文件重命名有两种命令: mv ,rename mv很简单,move文件移动 mv /dir/file1 /dir2/file1 两个参数,第一个是源文件,第二个是目的地,如果第二个参数文件名不一样,则会重命名。 当两个参数不带目录,只有文件名时,那就是重命名了。这是单个文件的重命名。 rename arg1 arg2 arg3 rename才是真正的批量重命名命令。而且他是3个参数,不是2个。 arg1:旧的字符串 arg2:新的字符串 arg3:匹配要重命名的文件,可以使用3种通配符,*所有文件、?满足某个字符匹配的文件、[char],*表示任意多个字符,?表示单个字符,[char]匹配char单个自定的精确字符,可以填写任意字符,foo[a]*表示只匹配fooa开头的文件名,如果一个文件是foobcc.txt,是不会被匹配的。 值的注意的是,此命令在不同的linux版本也有不同,Debian一系的操作系统别有用法。举例说明: 比如/home下有两个文件 abbcc.txt, addbb.txt , a.txt 我想把a替换为xxx,命令是这样的 : rename “a” “xxx” *.txt 那么它会首先去匹配有哪些文件需要修改,这里凡是.txt后缀的文件都会被匹配,如果改成?.txt则只会匹配到一个文件,那就是a.txt。然后把匹配到的文件中的a字符替换为xxx,注意测试时abab.txt这样的,只会替换第一个a,有待再了解。 rename支持正则表达式 字母的替换 rename "s/AA/aa/" * //把文件名中的AA替换成aa S 从开头 开始 *匹配所有 修改文件的后缀 rename "s//.html//.php/" * //把.html 后缀的改成 .php后缀 批量添加文件后缀 rename "s/$//.txt/" * //把所有的文件名都以txt结尾 批量删除文件名 rename "s//.txt//" * //把所有以.txt结尾的文件名的.txt删出 ~线下的`可以转移指令, 例如 echo `ll` >> a.txt 一般用于 把一个指令的结果写到文件中 Linux 通配符*:匹配所有 ?:匹配单个字符 打包 压缩与解压打包tar:将多个文件打入一个包文件(tar文件; tar ball) 打包: 格式 tar -cf 打包到的文件夹 需要打包的文件 可以多个 用空格隔开 tar -cf doc.tar ./a.txt ./b.txt ./*.dat ## 将a.txt,b.txt *.dat打入doc.tar包 解包:tar -xf 要解包的文件 tar -xf doc.tar 压缩:gzip a.txt gzip doc.tar ## 得到 doc.tar.gz 解压:gzip -d doc.tar.gz ## 得到doc.tar 打包和压缩可以一次性完成: tar -zcf doc.tar.gz ./a.txt ./b.txt ./c.txt ## 将abc三个文件打包,然后压缩 解包和解压缩可以一次性完成: tar -zxvf doc.tar.gz ## 将doc.tar.gz解压,然后解包 tar -zxvf doc.tar.gz -C /home/ ## 将doc.tar.gz解压到/home目录下去 注意:有的文件可能不经过打包直接压缩的,此时解压只能使用gzip -d 从windows上传文件指令和安装指令文件ALT +P 可以直接把文件从windows下托过去 Rz 上传文件 如果无法使用说明没有安装rz软件 使用 yum list | grep rz 找到re的安装软件 然后安装 yum -y install lrzsz 可以试着安装其他的 如man 一样的方式 先搜 再按 Yum指令Yum list Yum list |gerp 关键字 从yum中搜索安装包 Yum -y install 安装包名字 安装软件 Yum info 安装包名字 显示安装包信息 网络指令:Ping 用于确定主机能不能和另一台主机进行数据包交换 Ping 后面加要测试的主机ip 修改主机名临时生效: hostname 主机名 永久生效:修改配置文件 vim /etc/sysconfig/network 显示主机名:# hostnamelinmu100 此主机的主机名是linmu100,不加参数是用来显示当前主机的主机名;临时设置主机名:# hostname test100# hostname 注:显示主机名test100 通过hostname 工具来设置主机名只是临时的,下次重启系统时,此主机名将不会存在;显示主机IP: # hostname -i192.168.1.100 修改映射关系修改主机名和ip地址之间的映射关系 vim /etc/hosts 192.168.2.120 node-1.edu.cn node-1 可配置别名 Chkconfig --list 查看所有linux下的所有服务 Ipconfig 查询本地ip 默认网关,子网掩码等信息 netstat 显示每个网络接口设备的连接状态信息 Netstat -ltnp 查看tcp的所有的网络端口 L 监听 t tcp n 数字 p port 查看具体某一个端口使用状态 Netstat -ltnp | grep 8080 防火墙操作防火墙无法启动 iptables -F service iptables save service iptables restart Service iptables status 查看防火墙的状态 service iptables stop 关闭防火墙 service iptables start 开启防火墙 Chkconfig iptables off 开机就关掉防火墙Chkconfig iptables on 开机重启防火墙 Tracert 追踪每个网点经过的每一个ip地址 如 tracert www.baidu.com 会显示 这次请求经过的所有的ip地址,最后一个是百度地址。第一是本地地址。 find命令路径:/bin/find 执行权限:所有用户 作用:查找文件或目录 语法:find [搜索路径] [匹配条件] 在哪里搜 怎么搜 搜索匹配 如果没有指定搜索路径,默认从当前目录查找 find命令选项 -name 按名称查找 精准查找 eg:find /etc -name “init” 在目录/etc中查找文件init -iname 按名称查找 find查找中的字符匹配: *:匹配所有 ?:匹配单个字符 eg:find /etc -name “init???” 在目录/etc中查找以init开头的,且后面有三位的文件 -size 按文件大小查找 以block为单位,一个block是512B,0.5K +大于 -小于 不写是等于 eg:find /etc -size -204800 在etc目录下找出大于100MB的文件 100MB=102400KB=204800block -type 按文件类型查找 f 二进制文件 l 软连接文件 d 目录 eg: find /dev -type c find查找的基本原则: 占用最少的系统资源,即查询范围最小,查询条件最精准 eg: 如果明确知道查找的文件在哪一个目录,就直接对指定目录查找,不查找根目录/ grep命令命令路径:/bin/grep 执行权限:所有用户 作用:在文件中搜寻字串匹配的行并输出 就是一般用于查找关键字。 常和 yum ps du 等命令查找某个命令的具体大属性 ps aux | grep sam 查看用户sam执行的进程 语法:grep [-cinv] '搜寻字符串' filename 选项与参数: -c :输出匹配行的次数(是以行为单位,不是以出现次数为单位) -i :忽略大小写,所以大小写视为相同 -n :显示匹配行及行号 -v :反向选择,显示不包含匹配文本的所有行。 eg:grep ftp /etc/services eg:#grep -v ^# /etc/inittab 去掉文件行首的#号 eg:# grep -n “init”/etc/inittab 显示在inittab文件中,init匹配行及行号 eg:# grep -c“init”/etc/inittab 显示在inittab文件中,init匹配了多少次 grep 搜索本身带有双引号的字符串,需要对双引号转义,在"前面加上 "\ 比如 :搜索"type":"2" grep "\"type"\":"\"2"\" which命令路径:/usr/bin/which 执行权限:所有用户 作用:显示系统命令所在目录(绝对路径及别名) which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令 # which ls alias ls='ls --color=auto' /bin/ls # which zs /usr/bin/which: no zs in (/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/ch/bin) whereis命令路径:/usr/bin/whereis 执行权限:所有用户 作用:搜索命令所在目录 配置文件所在目录 及帮助文档路径 eg: which passwd 和 whereis passwd eg:查看/etc/passwd配置文件的帮助,就用 man 5 passwd 在linux系统查找jdk的安装路径:whereis javawhich java (java执行路径) 磁盘空间命令df命令 系统的磁盘空间 作用:用于查看Linux文件系统的状态信息,显示各个分区的容量、已使用量、未使用量及挂载点等信息。看剩余空间 语法:df [-hkam] -h(human-readable)根据磁盘空间和使用情况 以易读的方式显示 KB,MB,GB等 -k 以KB 为单位显示各分区的信息,默认 -M 以MB为单位显示信息 -a 显示所有分区包括大小为0 的分区 du命令 文件大小 作用:用于查看文件或目录的大小(磁盘使用空间) 语法:du [-ahs] [文件名目录] -a 显示子文件的大小 -h以易读的方式显示 KB,MB,GB等 -s summarize 统计总占有量 eg: du -a(all) /home 显示/home 目录下每个子文件的大小,默认单位为kb du -h /home 以K,M,G为单位显示/home 文件夹下各个子目录的大小 du -sh /home 以常用单位(K,M,G)为单位显示/home 目录的总大小 -s summarize df命令和du命令的区别: df命令是从文件系统考虑的,不仅考虑文件占用的空间,还要统计被命令或者程序占用的空间。 du命令面向文件,只计算文件或目录占用的空间。 #df –h / 作用:查看内存及交换空间#du –sh / free 内存使用状态 语法: free [-kmg] -k: 以KB为单位显示,默认就是以KB为单位显示 -m: 以MB为单位显示 -g: 以GB为单位显示 清理缓存命令: echo 1 > /proc/sys/vm/drop_caches toptop命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器 常用操作: top //每隔5秒显式所有进程的资源占用情况top -d 2 //每隔2秒显式所有进程的资源占用情况top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数 参数含义 top - 01:06:48 up 1:22, 1 user, load average: 0.06, 0.60, 0.48Tasks: 29 total, 1 running, 28 sleeping, 0 stopped, 0 zombieCpu(s): 0.3% us, 1.0% sy, 0.0% ni, 98.7% id, 0.0% wa, 0.0% hi, 0.0% siMem: 191272k total, 173656k used, 17616k free, 22052k buffersSwap: 192772k total, 0k used, 192772k free, 123988k cachedPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1379 root 16 0 7976 2456 1980 S 0.7 1.3 0:11.03 sshd14704 root 16 0 2128 980 796 R 0.7 0.5 0:02.72 top1 root 16 0 1992 632 544 S 0.0 0.3 0:00.90 init2 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0 3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0统计信息区前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下: 01:06:48 当前时间up 1:22 系统运行时间,格式为时:分1 user 当前登录用户数load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下: total 进程总数running 正在运行的进程数sleeping 睡眠的进程数stopped 停止的进程数zombie 僵尸进程数Cpu(s): 0.3% us 用户空间占用CPU百分比1.0% sy 内核空间占用CPU百分比0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比98.7% id 空闲CPU百分比0.0% wa 等待输入输出的CPU时间百分比0.0%hi:硬件CPU中断占用百分比0.0%si:软中断占用百分比 0.0%st:虚拟机占用百分比 平均负载和cpu使用率很容易混淆,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。 简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU使用率没有直接的关系。所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时两者是一致的I/O 密集型进程,等待 I/O 也会导致平均负载升高,但CPU使用率不一定高大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。 ldconfig参考:http://man.linuxde.net/ldconfighttps://blog.csdn.net/chenzixun0/article/details/56278632 主要是在默认搜寻目录/lib和/usr/lib以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如lib*.so*),进而创建出动态装入程序(ld.so)所需的连接和缓存文件,缓存文件默认为/etc/ld.so.cache,此文件保存已排好序的动态链接库名字列表。linux下的共享库机制采用了类似高速缓存机制,将库信息保存在/etc/ld.so.cache,程序连接的时候首先从这个文件里查找,然后再到ld.so.conf的路径中查找。为了让动态链接库为系统所共享,需运行动态链接库的管理命令ldconfig,此执行程序存放在/sbin目录下。 ldconfig命令参数: -v或–verbose:ldconfig将显示正在扫描的目录及搜索到的动态链接库,还有它所创建的连接的名字-f CONF:此选项指定动态链接库的配置文件为CONF,系统默认为/etc/ld.so.conf-p或–print-cache:此选项指示ldconfig打印出当前缓存文件所保存的所有共享库的名字。-V:此选项打印出ldconfig的版本信息,而后退出。从以上可知: 在/lib和/usr/lib里面添加库文件,是无需将路径添加到/etc/ld.so.conf中去的,但是需要使用命令sudo ldconfig,否则无法找到库文件。在上述两个目录之外的路径添加库文件,需要先将将库文件的路径追加入/etc/ld.so.conf,假设库文件在/usr/local/mysql/lib中,可以使用命令: echo "/usr/local/mysql/lib" >> /etc/ld.so.conf sudo ldconfig -v | grep mysql # 查看mysql库文件是否被找到。 1若在/lib和/usr/lib之外的目录中添加库文件,而又不在/etc/ld.so.conf中写入路径,此时可以用添加环境变量LD_LIBRARY_PATH的做法让系统识别到库文件。 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/mysql/lib 可以在/etc/ld.so.conf.d/目录下创建.conf文件来添加库路径。在默认的/etc/ld.so.conf文件中,可以看到有如下内容: include /etc/ld.so.conf.d/*.conf说明/etc/ld.so.conf.d/目录下所有的.conf文件都被包含,文件中所有的路径都会被搜索到。 例如: touch opencv.conf echo "/user/local/lib" > opencv.conf sudo ldconfig ps常用参数 根据用户过滤进程在需要查看特定用户进程的情况下,我们可以使用 -u 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令: $ ps -u pungki 通过cpu和内存使用来过滤进程也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 aux 参数,来显示全面的信息: $ ps -aux | less 显示全面信息 当结果很长时,我们可以使用管道和less命令来筛选。 默认的结果集是未排好序的。可以通过 --sort命令来排序。 根据 CPU 使用来升序排序 $ ps -aux --sort -pcpu | less 根据cpu使用排序 根据 内存使用 来升序排序 $ ps -aux --sort -pmem | less 也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 aux 参数,来显示全面的信息: $ ps -aux | less显示全面信息 当结果很长时,我们可以使用管道和less命令来筛选。 默认的结果集是未排好序的。可以通过 --sort命令来排序。 根据 CPU 使用来升序排序 $ ps -aux --sort -pcpu | less根据cpu使用排序 根据 内存使用 来升序排序 $ ps -aux --sort -pmem | less stat 显示指定文件的详细信息,比ls更详细 who 显示在线登陆用户 whoami 显示当前操作用户 hostname 显示主机名 uname 显示系统信息 top 动态显示当前耗费资源最多进程信息 ps 显示瞬间进程状态 ps -aux 查看具体某个进程的状态 Ps aux | grep java 查看java程序的进程状态 du 查看目录大小 du -h /home带有单位显示目录信息 du 文件 -sh 查看文件大小并计算总和。 du 1.txt -h 显示1.txt 文件的大小 df 查看磁盘大小 df -h 带有单位显示磁盘信息 ifconfig 查看网络情况 ping 测试网络连通 netstat 显示网络状态信息 man 命令不会用了,找男人 如:man ls clear 清屏 alias 对命令重命名 如:alias showmeit="ps -aux" ,另外解除使用unaliax showmeit nohup和&后台运行,进程查看及终止用途:不挂断地运行命令。 语法:nohup Command [ Arg … ] [ & ] 无论是否将 nohup 命令的输出重定向到终端,输出都将附加到当前目录的 nohup.out 文件中。 如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。 如果没有文件能创建或打开以用于追加,那么 Command 参数指定的命令不可调用。 退出状态:该命令返回下列出口值: 126 可以查找但不能调用 Command 参数指定的命令。 127 nohup 命令发生错误或不能查找由 Command 参数指定的命令。 否则,nohup 命令的退出状态是 Command 参数指定命令的退出状态。 &用途:在后台运行 一般两个一起用 nohup command & eg: 1 nohup /usr/local/node/bin/node /www/im/chat.js >> /usr/local/node/output.log 2>&1 & &2 2>&1 的区别0 是一个文件描述符,表示标准输入(stdin)1 是一个文件描述符,表示标准输出(stdout) 2 是一个文件描述符,表示标准错误(stderr) 一般来说, "1>" 通常可以省略成 ">". & 是一个描述符,如果1或2前不加&,会被当成一个普通文件。 1>&2 意思是把标准输出重定向到标准错误. 2>&1 意思是把标准错误输出重定向到标准输出。 &>filename 意思是把标准输出和标准错误输出都重定向到文件filename中 例子 ls nodir 1> filename.txt 2>&1 cat filename.txt ls: nodir: No such file or directory&> 与 >的区别上面例子把 标准输出 重定向到文件 filename.txt,然后把 标准错误 重定向到 标准输出,所以最后的错误信息也通过标准输出写入到了文件中 linux &> 与 >的区别(也可以说成是linux stdout(标准输出) stderr(标准错误)的区别) &>可以将stderr错误信息重定向输出 >可以将stdout标准输出信息重定向输出 下面是实际在linux命令行的测试结果: [root@Dev_yang shellScript]# lll -bash: lll: command not found //由于Linux没有lll这个命令所以会显示错误信息,这个就是stderr输出的错误信息 [root@Dev_yang shellScript]# lll>test -bash: lll: command not found //由于这个是错误信息 所以不能使用标准输出>将信息重定向到test文件中,所以错误信息直接在控制台打印出来了 [root@Dev_yang shellScript]# lll&>test //使用&>重定向 错误信息没有输出到控制台了,表示错误信息正确重定向到了test文件 [root@Dev_yang shellScript]# cat test -bash: lll: command not found //通过cat命令确实看到了 保存的错误信息 总结:>只能将正常信息重定向 &>可以将错误信息或者普通信息都重定向输出 查看运行的后台进程 (1)jobs -l jobs命令只看当前终端生效的,关闭终端后,在另一个终端jobs已经无法看到后台跑得程序了,此时利用ps(进程查看命令) ps作用:查看系统中的进程信息 语法:ps [-auxle] 常用选项 a:显示所有用户的进程 u:显示用户名和启动时间 x:显示没有控制终端的进程 e:显示所有进程,包括没有控制终端的进程 l:长格式显示 查看系统中所有进程 # ps aux #查看系统中所有进程,使用BSD操作系统格式,unix # ps -le #查看系统中所有进程,使用Linux标准命令格式 ps应用实例 # ps -u or ps -l 查看隶属于自己进程详细信息 # ps aux | grep sam 查看用户sam执行的进程 # ps -ef | grep init 查看指定进程信息 pstree作用:查看当前进程树 语法:pstree [选项] -p 显示进程PID -u 显示进程的所属用户 top 作用:查看系统健康状态 显示当前系统中耗费资源最多的进程,以及系统的一些负载情况。 语法:top [选项] -d 秒数,指定几秒刷新一次,默认3秒(动态显示) kill作用:关闭进程 语法:kill [-选项] pId kill -9 进程号(强行关闭) 常用 kill -1 进程号(重启进程) 权限管理不同用户(不同的用户的组)对不同的文件具有不同的操作权利叫做权限 一般安装软件尽量在user/local这个共享目录下 ,因为放在root目录下 别的用户是没有权限操作的。 三种基本权限 r 读权限(read) 可读 w 写权限(write) 可写 x 执行权限 (execute) 可执行 权限说明 快速 设置权限把 文件的权限列 列好 有权写的标1 无标0 然后就可以转化成 十进制 ,777表示所有权限都有 7**表示对这个文件有所有权限。 普通方法设置权限权限更改-chmod 英文:change mode (change the permissions mode of a file) 作用:改变文件或目录权限 语法: chmod [{ugoa}{+-=}{rwx}] [文件名或目录] -取消权限 + 增加权限 加减号后面可以一次操作多个权限 也可以 chmod [mode=421] [ 文件或目录] 参数:-R 下面的文件和子目录做相同权限操作(Recursive递归的) 思考:一个文件的权限谁可以更改? root 所有者 root 文件所有者 例如:chmod u+x a.txt chmod u+x,o-x a.txt 用数字来表示权限(r=4,w=2,x=1,-=0) 例如:chmod 750 b.txt rwx和数字表示方式能随意切换 注意:root用户是超级用户,不管有没有权限,root都能进行更改。用普通用户测试权限。 不能用一个普通用户去修改另一个普通用户的权限。 更改所有者-chown 英文:change file ownership 作用:更改文件或者目录的所有者 语法 : chown user[:group] file... -R : 递归修改 参数格式 : user : 新的档案拥有者的使用者 ID group : 新的档案拥有者的使用者群体(group) eg:#chown lee file1 把file1文件的所有者改为用户lee eg:#chown lee:test file1 把file1文件的所有者改为用户lee,所属组改为test eg:#chown –R lee:test dir 修改dir及其子目录的所有者和所属组 改变所属组chgrp 英文:change file group ownership 作用:改变文件或目录的所属组 语法 : chgrp [group] file... eg:chgrp root test.log 把test.log的所属组修改为root 文件: r-cat,more,head,tail,less w-echo,vi x-命令,脚本 目录: r-ls w -touch,mkdir,rm,rmdir x-cd 能删除文件的权限是对该文件所在的目录有wx权限。 所有者 所属组 其他人 第1位:文件类型(d 目录,- 普通文件,l 链接文件) (文件的类型) 第2-4位:所属用户(所有者)权限,用u(user)表示(用户的权限) 第5-7位:所属组权限,用g(group)表示(用户所在组的权限) 第8-10位:其他用户(其他人)权限,用o(other)表示(不在组中的其他人) 第2-10位:表示所有的权限,用a(all)表示 所有人 类型: f 二进制文件 l 软连接文件 d 目录 字符 权限 对文件的含义 对目录的含义 r 读权限 可以查看文件内容 可以列出目录的内容(ls) w 写权限 可以修改文件内容 可以在目录中创建删除文件( mkdir,rm ) x 执行权限 可以执行文件 可以进入目录(cd) 用户管理命令Exit 突出当前用户 回到root用户 useradd添加用户 语法:useradd [选项] 用户名 passwd修改密码命令 语法:passwd [选项] [用户名] Passwd reba 回车输入密码 518189 用户密码:生产环境中,用户密码长度8位以上,设置大小写加数字加特殊字符,要定期更换密码。 ys^h_L9t userdel(user delete)删除用户 -r 删除账号时同时删除宿主目录(remove) 一定要使用 —r这样能彻底删除 Linux 命令行快捷键涉及在linux命令行下进行快速移动光标、命令编辑、编辑后执行历史命令、Bang(!)命令、控制命令等。让basher更有效率。 常用指令ctrl+左右键:在单词之间跳转 ctrl+a:跳到本行的行首 ctrl+e:跳到页尾 Ctrl+u:删除当前光标前面的文字 (还有剪切功能) ctrl+k:删除当前光标后面的文字(还有剪切功能) Ctrl+L:进行清屏操作 Ctrl+y:粘贴Ctrl+u或ctrl+k剪切的内容 Ctrl+w:删除光标前面的单词的字符 Alt – d :由光标位置开始,往右删除单词。往行尾删 说明 Ctrl – k: 先按住 Ctrl 键,然后再按 k 键; Alt – k: 先按住 Alt 键,然后再按 k 键; M – k:先单击 Esc 键,然后再按 k 键。 移动光标在主界面的时候vi区分开 Ctrl – a :移到行首 Ctrl – e :移到行尾 end Ctrl – b :往回(左)移动一个字符 Ctrl – f :往后(右)移动一个字符 Alt – b :往回(左)移动一个单词 Alt – f :往后(右)移动一个单词 Ctrl – xx :在命令行尾和光标之间移动 M-b :往回(左)移动一个单词 M-f :往后(右)移动一个单词 编辑命令Ctrl – h :删除光标左方位置的字符 Ctrl – d :删除光标右方位置的字符(注意:当前命令行没有任何字符时,会注销系统或结束终端) Ctrl – w :由光标位置开始,往左删除单词。往行首删 Alt – d :由光标位置开始,往右删除单词。往行尾删 M – d :由光标位置开始,删除单词,直到该单词结束。 Ctrl – k :由光标所在位置开始,删除右方所有的字符,直到该行结束。 Ctrl – u :由光标所在位置开始,删除左方所有的字符,直到该行开始。 Ctrl – y :粘贴之前删除的内容到光标后。 ctrl – t :交换光标处和之前两个字符的位置。 Alt + . :使用上一条命令的最后一个参数。 Ctrl – _ :回复之前的状态。撤销操作。 Ctrl -a + Ctrl -k 或 Ctrl -e + Ctrl -u 或 Ctrl -k + Ctrl -u 组合可删除整行。 Bang(!)命令!! :执行上一条命令。 ^foo^bar :把上一条命令里的foo替换为bar,并执行。 !wget :执行最近的以wget开头的命令。 !wget:p :仅打印最近的以wget开头的命令,不执行。 !$ :上一条命令的最后一个参数, 与 Alt - . 和 $_ 相同。 !* :上一条命令的所有参数 !*:p :打印上一条命令是所有参数,也即 !*的内容。 ^abc :删除上一条命令中的abc。 ^foo^bar :将上一条命令中的 foo 替换为 bar ^foo^bar^ :将上一条命令中的 foo 替换为 bar !-n :执行前n条命令,执行上一条命令: !-1, 执行前5条命令的格式是: !-5 查找历史命令Ctrl – p :显示当前命令的上一条历史命令 Ctrl – n :显示当前命令的下一条历史命令 Ctrl – r :搜索历史命令,随着输入会显示历史命令中的一条匹配命令,Enter键执行匹配命令;ESC键在命令行显示而不执行匹配命令。 Ctrl – g :从历史搜索模式(Ctrl – r)退出。 控制命令 Ctrl – l :清除屏幕,然后,在最上面重新显示目前光标所在的这一行的内容。 Ctrl – o :执行当前命令,并选择上一条命令。 Ctrl – s :阻止屏幕输出 Ctrl – q :允许屏幕输出 Ctrl – c :终止命令 Ctrl – z :挂起命令 重复执行操作动作 M – 操作次数 操作动作 : 指定操作次数,重复执行指定的操作。 Bash基本使用 命令别名alias 别名="命令名" 临时生效 eg:alias copy =cp alias xrm=”rm -r” #alias 查看别名信息 unalias 别名 删除别名 eg: unalias copy 让别名永久生效 #vi /root/.bashrc 添加别名 命令执行时顺序 1,第一顺位执行用绝对路径或相对路径执行的命令。 2,第二顺位执行别名。 3,第三顺位执行bash的内部命令。 4,第四顺位执行按照$PATH环境变量定义的目录查找顺序找到的第一个命令。 输入输出重定向 同标准I/O一样,Shell对于每一个进程预先定义3个文件描述字(0,1,2)。 分别对应于:0:STDIN 标准输入 1:STDOUT 标准输出 2:STDERR 标准错误输出。 默认地,标准的输入为键盘,但是也可以来自文件或管道(pipe |)。设备文件名为/dev/stdin。 默认地,标准的输出为终端(terminal),但是也可以重定向到文件,管道或后引号(backquotes `)。设备文件名为/dev/stdout。 默认地,标准的错误输出到终端,但是也可以重定向到文件。设备文件名为/dev/stderr。 标准的输入,输出和错误输出分别表示为STDIN,STDOUT,STDERR,也可以用0,1,2来表示。 还有3~9也可以作为文件描述符。3~9你可以认为是执行某个地方的文件描述符,常被用来作为临时的中间描述符。 >或>> 输出重定向 >会替换;>>会累加,不会替换之前的内容 eg: #ls -l /tmp > /tmp.msg (替换) eg:#date >> /tmp.msg (追加) 可以这么创建文件: echo "hehe" >> /home/test1.txt < 输入重定向 eg:wall < /etc/issue.net 把issue.net里的内容广播出去 eg:tr "a-z" "A-Z" < /etc/passwd 将小写转为大写(输入重定向),在屏幕输出 自动创建文件 cat > log.txt ccc > ddd > EXI 按ctrl+d 结束输出 2> 错误输出重定向 eg:cp -R /usr /backup/usr.bak 2> /bak.error (0和1的输入输出重定向把数字省略了) 正确输出和错误输出同时保存 命令 > 文件 2>&1 覆盖方式,把正确输出和错误输出都保存到同一个文件当中。 命令 >> 文件 2>&1 追加方式,把正确输出和错误输出都保存到同一个文件当中。 命令 &> 文件 覆盖方式,把所有输出都保存到同一个文件当中。 命令 &>> 文件 追加方式,把所有 输出都保存到同一个文件当中。 命令 >> 文件1 2>>文件2 正确输出追加到文件1中,错误输出追加到文件2中。 & 把程序放到后台执行,但是当终端关闭时,程序可能关闭 nohup 能保证 终端关闭时,进程依然存在 分析 2>&1 以>/dev/null 2>&1 为例: 分解这个组合: 1:> 代表重定向到哪里,例如:echo '123' > /home/123.txt 2:/dev/null 代表空设备文件 3:2> 表示重定向stderr标准错误 4:& 表示等同于的意思,2>&1,表示2的输出重定向等同于1 5:1 表示stdout标准输出,系统默认值是1,所以'>/dev/null'等同于 '1>/dev/null' 因此,>/dev/null 2>&1也可以写成“1> /dev/null 2> &1” 那么>/dev/null 2>&1语句执行过程为: 1>/dev/null :首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,说白了就是不显示任何信息。 2>&1 :接着,标准错误输出重定向到标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。 在Linux下最常用的方式有两种: command > file 2>file 与command > file 2>&1 首先command > file 2>file 的意思是将命令所产生的标准输出信息,和错误的输出信息送到file 中。command > file 2>file 这样的写法,stdout和stderr都直接送到file中, file会被打开两次,这样stdout和stderr会互相覆盖,这样写相当使用了FD1和FD2两个同时去抢占file 的管道。 而command >file 2>&1 这条命令就将stdout直接送向file, stderr 继承了FD1管道后,再被送往file,此时,file 只被打开了一次,也只使用了一个管道FD1,它包括了stdout和stderr的内容。 从IO效率上,前一条命令的效率要比后面一条的命令效率要低,所以在编写shell脚本的时候,较多的时候我们会command > file 2>&1 这样的写法。 扩展一下 另外一个非常有用的重定向操作符是 '-',请看下面这个例子: $ (cd /source/directory && tar cf - . ) | (cd /dest/directory && tar xvfp -) 该命令表示把 /source/directory 目录下的所有文件通过压缩和解压,快速的全部移动到/dest/directory 目录下去,这个命令在/source/directory 和 /dest/directory 不处在同一个文件系统下时将显示出特别的优势。 下面还几种不常见的用法: n&- 表示将标准输出关闭 管道格式: 命令1 | 命令2 将命令1的正确输出作为命令2的操作对象。 管道命令可以多个管道命令一起使用 管道命令操作符是:”|”,它只能处理经由前面一个指令传出的正确输出信息,对错误信息信息没有直接处理能力。然后,传递给下一个命令,作为标准的输入. 管理命令的输出说明: 【指令1】正确输出,作为【指令2】的输入 然后【指令2】的输出作为【指令3】的输入 ,【指令3】输出就会直接显示在屏幕上面了。 通过管道之后【指令1】和【指令2】的正确输出不显示在屏幕上面 【提醒注意】: 1. 管道命令只处理前一个命令正确输出,不处理错误输出; 2. 管道命令右边命令,必须能够接收标准输入流命令才行 eg: ls -l /etc|more more下查看/etc 下的文件 eg:ls -l /etc|grep init 查看etc目录下与init相关的文件 eg:wc -l /etc/services 查看 /etc/services文件有多少行 命令连接符 ; 命令1;命令2 用分号;间隔的各命令按顺序依次执行,命令之间没有逻辑联系 eg:pwd;ls;date && 命令1&&命令2 逻辑与关系,命令1执行成功后,命令2才被执行,命令1失败,命令2不执行 || 命令1||命令2 逻辑或关系,命令1执行失败,命令2才被执行;命令1执行正确,命令2不执行 dd if=输入文件 of=输出文件 bs=字节数 count=个数 选项: if=输出文件 指定源文件或源设备 of=输出文件 指定目标文件或目标设备 bs=字节数 指定一次输入/输出多少字节,即把这些字节看做一个数据块 count=个数 指定输入/输出多少个数据块 eg:date;dd if=/dev/zero of=/root/testfile bs=1k count=100000 ;date 创建文件,并查看复制使用的时间 eg:mkdir test && echo "aaa" >test/a.txt && more a,txt 创建test目录 ,并且向test目录下文件a.txt写入aaa,然后查看a.txt的文件内容 eg:#命令 && echo yes || echo no 判断一条命令是否正确执行了 命令替换符 将一个命令的输出作为另外一个命令的参数。 格式为: 命令1 `命令2`(数字键1左边的符号) eg:ls -l `which touch` 把which touch 的输出作为 ls的参数,执行结果为:-rwxr-xr-x. 1 root root 52656 6月 22 2012 /bin/touch xargs1、作用: (1)将前一个命令的标准输出传递给下一个命令,作为它的参数,xargs的默认命令是echo,空格是默认定界符 (2)将多行输入转换为单行 2、使用模式:front command | xargs -option later command front command: 前一个命令 -option: xargs的选项 later command: 后一个命令 3、xargs常用选项 -n: 指定一次处理的参数个数 -d: 自定义参数界定符 -p: 询问是否运行 later command 参数 -t : 表示先打印命令,然后再执行 -i : 逐项处理 ...更多参数查看man xargs 4、使用实例 测试文本:xargs.txt [python] view plain copy a b c d e f g h i j k l m n o p q r s t u v w x y z (1)多行输入单行输出 [python] view plain copy cat xargs.txt | xargs ( 2)指定一次处理的参数个数:指定为5,多行输出 [python] view plain copy cat xargs.txt | xargs -n 5 (3)自定义参数界定符:指定界定符为'm' [python] view plain copy cat xargs.txt | xargs -d m (4)询问是否运行 later command 参数 [python] view plain copy cat xargs.txt | xargs -n 5 -p (5)将所有文件重命名,逐项处理每个参数 [python] view plain copy ls *.txt |xargs -t -i mv {} {}.bak 更多参数选项查看man xargs 5、xargs与管道|的区别| 用来将前一个命令的标准输出传递到下一个命令的标准输入,xargs 将前一个命令的标准输出传递给下一个命令,作为它的参数。 [python] view plain copy #使用管道将ls的结果显示出来,ls标准输出的结果作为cat的标准输出 ls | cat #使用xargs将ls的结果作为cat的参数,ls的结果为文件名,所以cat 文件名即查看文件内容 ls | xargs cat 6、xargs与exec的区别 (1)exec参数是一个一个传递的,传递一个参数执行一次命令;xargs一次将参数传给命令,可以使用-n控制参数个数 [python] view plain copy #xargs将参数一次传给echo,即执行:echo begin ./xargs.txt ./args.txt find . -name '*.txt' -type f | xargs echo begin #exec一次传递一个参数,即执行:echo begin ./xargs.txt;echo begin ./args.txt find . -name '*.txt' -type f -exec echo begin {} \; (2)exec文件名有空格等特殊字符也能处理;xargs不能处理特殊文件名,如果想处理特殊文件名需要特殊处理 [python] view plain copy #find后的文件名含有空格 find . -name '*.txt' -type f | xargs cat find . -name '*.txt' -type f -exec cat {} \; 原因:默认情况下, find 每输出一个文件名, 后面都会接着输出一个换行符 ('\n'),因此我们看到的 find 的输出都是一行一行的,xargs 默认是以空白字符 (空格, TAB, 换行符) 来分割记录的, 因此文件名 ./t t.txt 被解释成了两个记录 ./t 和 t.txt, cat找不到这两个文件,所以报错,为了解决此类问题, 让 find 在打印出一个文件名之后接着输出一个 NULL 字符 ('') 而不是换行符, 然后再告诉 xargs 也用 NULL 字符来作为记录的分隔符,即 find -print0 和 xargs -0 ,这样就能处理特殊文件名了。 [python] view plain copy #xargs处理特殊文件名 find . -name '*.txt' -type f -print0 | xargs -0 cat 时间管理查看时间Date 按照默认的时间格式显示时间 date + ”%Y-%m-%d %H:%M:%S” 按照自己设置的格式显示时间 date -d “1 day ago” +%Y-%m-%d ## 获取前一日的日期 date -d “+1 day” +%Y-%m-%d ## 获取后一日的日期 设置时间date -s "2017-12-25 09:38:40" ## 修改时间 网络时间同步ntpdate 0.asia.pool.ntp.org 注意:ntpdate在系统中默认没有安装,需要先安装: yum search ntpdate 搜索出软件包,再 yun install xxx... 安装 SSH 知识点第一步安装客户端 yum ssh linux02 (ip) exit 免密登录 比如A机器想要控制机器 1 A生成公钥和私钥 ssh-keygen 注意没有空格 2 将公钥发送给需要免密登录的机器 ssh-copy-id B 注意没有空格 反之 吧B想控制A一样的过程 ssh加强SSH是linux中,远程登录会话的一种安全协议 linux服务器上,一般都已经集成了ssh的服务端软件,并自启; 如果需要在linux上用ssh客户端去登录别的linux服务器,则需要安装ssh的客户端: yum install openssh-clients.x86_64 -y 在linux中远程登录另一台linuxssh cts02 ## 没有指定登录者身份,默认用当前会话的身份 用户名@主机名 注定用户名去远程登录主机 ssh baby@cts02 ## 指定以baby用户来登录远程的cts02 从一台linux上发送一个远程指令给另一台远程linux去执行格式 ssh 主机名 “命令” 用英文双引号引命令 ssh cts02 “command” 例: ssh cts02 “mkdir /root/xyz” java程序在linux如何启动java -cp x.jar:y.jar:z.jar top.ganhoo.App 没有包 直接写类名 可执行的jar包:使用 java -jar 同时在执行java程序时可以设置jvm的参数 java -Xms128M -Xmx256M -Xss1024K -XX:PermSize=128m -XX:MaxPermSize=256m -cp x.jar:y.jar:z.jar top.ganhoo.App 发送远程指令执行java程序示范:ssh cts02 "/root/apps/jdk1.8.0_60/bin/ java -cp /root/x.jar HelloWorld > /root/hello.log" 或者 ssh cts02 "source /etc/profile;java -cp /root/x.jar HelloWorld" 注意: java -cp使用空格的 java -cp /root/x.jar HelloWorld" java -cp 指令要和后面的有空格 不然默认是一个字符串了 也就是 所有指令 都要和执行的内容直接有空格 从一台linux远程拷贝文件到另一台linuxscp ## 远程拷贝,前提是,两台linux上都必须有这个scp程序 拷贝文件: scp ./a.txt root@cts02:/root/ 注意root@cts02 是全写 直接cts02也行 拷贝文件夹:需要递归: scp -r ./aaa/ cts02:/root/ SSH免密验证(密钥)配置 ssh会话一定会验证登陆者的身份! 验证的机制有两种: 用户名+密码验证密钥验证请求方需要事先创建一对密钥(公钥,私钥; 私钥自己持有,公钥交给目标机器) 定时任务crontab -e crontab -l crontab -r serivce crond restart crontab 命令允许用户提交、编辑或删除相应的作业。每一个用户都可以有一个crontab 文件来保存调度信息。可以使用它运行任意一个 s h e l l 脚本或某个命令。 crontab命令格式 作用:用于生成cron进程所需要的crontab文件 crontab的命令格式 crontab [-u user] {-l|-r|-e} -u 用户名 -l 显示当前的crontab -r 删除当前的crontab -e 使用编辑器编辑当前的crontab文件。 crontab文件格式 minute hour day-of-month month-of-year day-of-week commands 分< >时< >日< >月< >星期< >要运行的命令 < >表示空格 其中 Minute 一小时中的哪一分钟 [0~59] hour 一天中的哪个小时 [0~23] day-of-month 一月中的哪一天 [1~31] month-of-year 一年中的哪一月 [1~12] day-of-week 一周中的哪一天 [0~6] 0表示星期天 commands 执行的命令 书写注意事项 1,全都不能为空,必须填入,不知道的值使用通配符*表示任何时间 2,每个时间字段都可以指定多个值,不连续的值用,间隔,连续的值用-间隔。 3,命令应该给出绝对路径 4,用户必须具有运行所对应的命令或程序的权限 如何使用crontab 运行多个任务: 方法1:在crontab -e 里 写多个 输入命令 crontab –e 敲回车 开始编写任务: 方法2:把所有的任务,写入到一个可执行的文件 再在crontab -e里面配置执行任务 分钟 小时 天 月 星期 命令/脚本 eg:1到3月份,每周二周五,下午6点的计划任务 0 18 * 1-3 2,5 eg:周一到周五下午,5点半提醒学生15分钟后关机 linux 高级指令 trtr 替换字符 被替换的字符与替换的字符数必须是相等的 用法:tr 旧字符 新字符 cat a.txt | tr 20 89 将cat a.txt结果中的20替换成89 linux中sort命令功能说明:将文本文件内容加以排序,sort可针对文本文件的内容,以行为单位来排序。 参 数: -b 忽略每行前面开始出的空格字符。 -c 检查文件是否已经按照顺序排序。 -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。 -f 排序时,将小写字母视为大写字母。 -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。 -m 将几个排序好的文件进行合并。 -M 将前面3个字母依照月份的缩写进行排序。 -n 依照数值的大小排序。 -o 将排序后的结果存入指定的文件。 -r 以相反的顺序来排序。 -t 指定排序时所用的栏位分隔字符。 +- 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。 --help 显示帮助。 --version 显示版本信息 diff 文件差异的对比diff 文件1 文件2 vimdiff pas3 pas5 说明: 用:q退出 注:在vimdiff中可以按i键进入vim的编辑模式修改文件内容。按Esc键退出编辑模式,用:wq保存并退出vim编辑器。(用ctrl+w+w在窗口之间切换) linux命令 grep、sed、awk三剑客一、grep grep命令主要用于文本内容的查找。它支持正则表达式查找,命令格式为: grep [option] pattern filename 例如:在filename文本中查找包含”text”的行: grep "text" filename 这条命令默认只输出匹配的文本行 option为-o时,命令行只输出匹配的文本 option为-v时,命令行只输出没有匹配的文本行 option为-R -r时,匹配目录下的所有文件 二、sed sed命令主要用于文本内容的编辑。默认只处理模式空间,不处理原数据,而且sed是针对一行行数据来进行处理的。 sed的命令格式为: sed [option] 'command' filename option常用选项有以下: -n:使用安静(silent)模式。 在一般sed的用法中,所有来自stdin的数据一般都会被列出到终端上。 但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。 -e:直接在命令列模式上进行sed的动作编辑。 -i:直接修改读取的文件内容,而不是输出到终端。 command可以分为以下几种: a:追加,a的后面可以接字串,而这些字串会在新的一行出现(目前的下一行) i:插入,i的后面可以接字串,而这些字串会在新的一行出现(目前的上一行) d:以行为单位的删除 c:以行为单位的替换,c的后面可以接字串 s:在行中搜寻并替换 p:以行为单位的显示,通常p会与参数sed -n一起运行案例 1、在filename文本最后一行追加hello world: sed '$a hello world' filename 2、在filename文本第一行插入hello world: sed '1i hello world' filename 3、既要在最后一行追加hello world,又要在第一行插入hello world: sed -e '$a hello world' -e '1i hello world' filename [root@localhost ruby] # sed '1,2d' ab #删除第一行到第二行 [root@localhost ruby] # sed -n '1,2p' ab #显示第一行到第二行 [root@localhost ruby] # sed -n '/ruby/p' ab #查询包括关键字ruby所在所有行另外,sed比较常用的就是文本替换,它也支持正则表达式,功能强大。 例如: 1、表示将filename文本的每行中的oldstring替换为newstring: sed 's/oldstring/newstring/g' filename 2、删除空白行: sed '/^\s*$/d' filename PS:正则表达式中\s表示空白字符(包括,空格,制表符等) 三、awk (将一行分为多个字段做处理) awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F 用来指定域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 $0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 案例: #cat /etc/passwd |awk -F ':' '{print $1}' #-F 指定分隔符为 : root daemon bin sys #cat /etc/passwd |awk -F ':' '{print $1"\t"$7}' #显示第1、7个字段 root /bin/bash daemon /bin/sh bin /bin/sh sys /bin/sh
|
【本文地址】