| KNN算法详解 | 您所在的位置:网站首页 › k近邻算法改进 › KNN算法详解 |
KNN算法详解
|
KNN算法详解
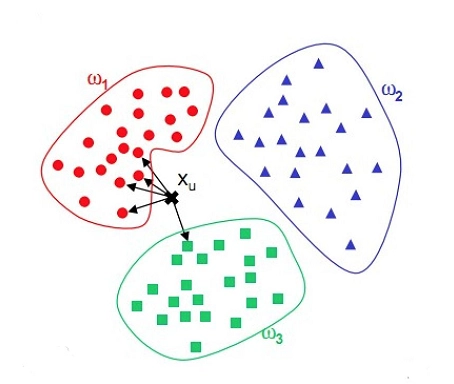
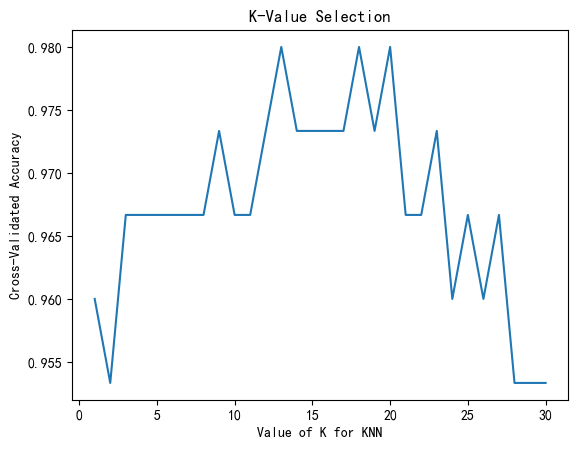
KNN(K-Nearest Neighbors)算法是一种简单且常用的机器学习算法,广泛应用于分类和回归问题。本文将详细介绍KNN算法的基本概念、工作原理、优缺点及其在Python中的实现,并通过具体示例展示其应用。 KNN算法是一种基于实例的学习方法,它假设相似的实例具有相似的标签。具体来说,对于一个待分类或待预测的样本,KNN算法将根据其在特征空间中最接近的K个邻居的标签来进行分类或回归。 KNN算法的工作原理KNN算法的工作原理可以分为以下几个步骤: 计算距离:对于待分类的样本,计算其与训练集中每个样本的距离。常用的距离度量包括欧氏距离、曼哈顿距离和闵可夫斯基距离等。选择K个最近邻居:根据计算的距离,选择距离最近的K个样本。投票或平均:对于分类任务,统计K个最近邻居中出现次数最多的标签作为预测标签;对于回归任务,计算K个最近邻居的平均值作为预测值。 距离度量 欧氏距离欧氏距离是最常用的距离度量,计算公式为: d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} d(x,y)=i=1∑n(xi−yi)2 曼哈顿距离曼哈顿距离计算公式为: d ( x , y ) = ∑ i = 1 n ∣ x i − y i ∣ d(x, y) = \sum_{i=1}^{n} |x_i - y_i| d(x,y)=i=1∑n∣xi−yi∣ 闵可夫斯基距离闵可夫斯基距离是欧氏距离和曼哈顿距离的广义形式,计算公式为: d ( x , y ) = ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 p d(x, y) = \left( \sum_{i=1}^{n} |x_i - y_i|^p \right)^{\frac{1}{p}} d(x,y)=(i=1∑n∣xi−yi∣p)p1 其中,当 ( p = 2 ) 时,为欧氏距离;当 ( p = 1 ) 时,为曼哈顿距离。 K值的选择K值的选择对于KNN算法的性能至关重要。K值过小可能导致过拟合,而K值过大可能导致欠拟合。通常通过交叉验证等方法来选择最佳的K值。 KNN算法的优缺点 优点 简单易懂:KNN算法直观、易于理解和实现。无需训练:KNN算法不需要显式的训练过程,直接对训练数据进行存储和查询。适用性广:KNN算法可以用于分类和回归任务,且对异常值不敏感。 缺点 计算复杂度高:对于大规模数据集,KNN算法的计算复杂度较高,需要计算所有样本的距离。内存消耗大:KNN算法需要存储所有训练数据,因此内存消耗较大。维度灾难:在高维空间中,样本之间的距离变得不再具有区分性,影响算法性能。 KNN算法的Python实现下面通过Python代码实现KNN算法,并以具体示例展示其应用。 导入库 import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report 加载数据集使用Iris数据集进行演示: # 加载数据集 iris = load_iris() X = iris.data y = iris.target # 数据集划分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 数据标准化 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) 训练KNN模型 # 训练KNN模型 knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) # 预测 y_pred = knn.predict(X_test) # 评估 accuracy = accuracy_score(y_test, y_pred) print(f'Accuracy: {accuracy:.2f}') # 混淆矩阵 conf_matrix = confusion_matrix(y_test, y_pred) print('Confusion Matrix:') print(conf_matrix) # 分类报告 class_report = classification_report(y_test, y_pred) print('Classification Report:') print(class_report) 选择最佳K值使用交叉验证选择最佳K值: from sklearn.model_selection import cross_val_score k_range = range(1, 31) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') k_scores.append(scores.mean()) plt.plot(k_range, k_scores) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated Accuracy') plt.title('K-Value Selection') plt.show()
KNN算法在图像识别中应用广泛,例如手写数字识别、面部识别等。通过计算图像特征之间的相似度,可以实现对图像的分类。 import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import fetch_openml from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report # 加载MNIST数据集 mnist = fetch_openml('mnist_784', version=1) X = mnist.data y = mnist.target.astype(int) # 数据集划分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 数据标准化 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # 训练KNN模型 knn = KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) # 预测 y_pred = knn.predict(X_test) # 评估 accuracy = accuracy_score(y_test, y_pred) print(f'Accuracy: {accuracy:.2f}') # 混淆矩阵 conf_matrix = confusion_matrix(y_test, y_pred) print('Confusion Matrix:') print(conf_matrix) # 分类报告 class_report = classification_report(y_test, y_pred) print('Classification Report:') print(class_report)使用交叉验证,选择K值 from sklearn.model_selection import cross_val_score k_range = range(1, 31) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X_train, y_train, cv=5, scoring='accuracy') k_scores.append(scores.mean()) plt.plot(k_range, k_scores) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated Accuracy') plt.title('K-Value Selection') plt.show() 文本分类在文本分类任务中,KNN算法可以根据文档的特征向量(如TF-IDF)计算相似度,从而实现文档分类。 import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report from sklearn.model_selection import cross_val_score # 加载20类新闻组数据集 newsgroups = fetch_20newsgroups(subset='all') X = newsgroups.data y = newsgroups.target # 文本向量化 vectorizer = TfidfVectorizer(stop_words='english') X_tfidf = vectorizer.fit_transform(X) # 数据集划分 X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42) # 训练KNN模型 knn = KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) # 预测 y_pred = knn.predict(X_test) # 评估 accuracy = accuracy_score(y_test, y_pred) print(f'Accuracy: {accuracy:.2f}') # 混淆矩阵 conf_matrix = confusion_matrix(y_test, y_pred) print('Confusion Matrix:') print(conf_matrix) # 分类报告 class_report = classification_report(y_test, y_pred) print('Classification Report:') print(class_report)使用交叉验证,选择K值 k_range = range(1, 15) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X_train, y_train, cv=5, scoring='accuracy') k_scores.append(scores.mean()) plt.plot(k_range, k_scores) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated Accuracy') plt.title('K-Value Selection') plt.show() 结语KNN算法作为一种简单直观的机器学习算法,具有广泛的应用前景。通过本文的介绍,你应该对KNN算法的基本概念、工作原理、优缺点及其在Python中的实现有了较为全面的了解。在实际应用中,可以根据具体问题选择合适的K值和距离度量,从而取得良好的预测效果。希望本文能帮助你更好地理解和应用KNN算法。 我的其他同系列博客支持向量机(SVM算法详解) GBDT算法详解 XGBOOST算法详解 CATBOOST算法详解 随机森林算法详解 lightGBM算法详解 对比分析:GBDT、XGBoost、CatBoost和LightGBM 机器学习参数寻优:方法、实例与分析 |
【本文地址】