| 机器学习之浅谈KNN算法(图文结合) | 您所在的位置:网站首页 › k线图的构造 › 机器学习之浅谈KNN算法(图文结合) |
机器学习之浅谈KNN算法(图文结合)
|
文章目录
一.KNN算法概述二.KNN算法介绍2.1距离计算2.2 K值选择
三.KNN特点KNN算法的优势和劣势KNN算法优点KNN算法缺点
四.代码:利用KNN实现鸢尾花数据集方法一(调库)方法二(底层源码)
运算结果
一.KNN算法概述
KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学习算法),但却是有本质区别的。那么什么是KNN算法呢,接下来我们就来介绍介绍吧。 二.KNN算法介绍KNN的全称是K Nearest Neighbors,意思是K个最近的邻居,从这个名字我们就能看出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。听起来有点绕,还是看看图吧。 明白了大概原理后,我们就来说一说细节的东西吧,主要有两个,K值的选取和点距离的计算。 2.1距离计算要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下: 通过上面那张图我们知道K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。 通过交叉验证计算方差后你大致会得到下面这样的图: 所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。具体如何得出K最佳值的代码,下一节的代码实例中会介绍。 三.KNN特点KNN是一种非参的,惰性的算法模型。什么是非参,什么是惰性呢? -== 非参的意思==并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。 惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快 KNN算法的优势和劣势了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在. KNN算法优点简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。 模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。 预测效果好。 对异常值不敏感 KNN算法缺点 对内存要求较高,因为该算法存储了所有训练数据预测阶段可能很慢对不相关的功能和数据规模敏感至于什么时候应该选择使用KNN算法,sklearn的这张图给了我们一个答案 ①使用读取文件的方式,使用open、以及csv中的相关方法载入数据 ②输入测试集和训练集的比率,对载入的数据使用shuffle()打乱后,计算训练集及测试集个数对特征值数据和对应的标签数据进行分割。 ③将分割后的数据,计算测试集数据与每一个训练集的距离,使用norm()函数直接求二范数,或者载入数据使用np.sqrt(sum((test - train) ** 2))求得距离,使用argsort()将距离进行排序,并返回索引值, ④取出值最小的k个,获得其标签值,存进一个字典,标签值为键,出现次数为值,对字典进行按值的大小递减排序,将字典第一个键的值存入预测结果的列表中,计算完所有测试集数据后,返回一个列表。 ⑤将预测结果与测试集本身的标签进行对比,得出分数 import csv import random import numpy as np import operator def openfile(filename): """ 打开数据集,进行数据处理 :param filename: 数据集的路径 :return: 返回数据集的数据,标签,以及标签名 """ with open(filename) as csv_file: data_file = csv.reader(csv_file) temp = next(data_file) # 数据集中数据的总数量 n_samples = int(temp[0]) # 数据集中特征值的种类个数 n_features = int(temp[1]) # 标签名 target_names = np.array(temp[2:]) # empty()函数构造一个未初始化的矩阵,行数为数据集数量,列数为特征值的种类个数 data = np.empty((n_samples, n_features)) # empty()函数构造一个未初始化的矩阵,行数为数据集数量,1列,数据格式为int target = np.empty((n_samples,), dtype=np.int) for i, j in enumerate(data_file): # 将数据集中的将数据转化为矩阵,数据格式为float # 将数据中从第一列到倒数第二列中的数据保存在data中 data[i] = np.asarray(j[:-1], dtype=np.float64) # 将数据集中的将数据转化为矩阵,数据格式为int # 将数据集中倒数第一列中的数据保存在target中 target[i] = np.asarray(j[-1], dtype=np.int) # 返回 数据,标签 和标签名 return data, target, target_names def random_number(data_size): """ 该函数使用shuffle()打乱一个包含从0到数据集大小的整数列表。因此每次运行程序划分不同,导致结果不同 改进: 可使用random设置随机种子,随机一个包含从0到数据集大小的整数列表,保证每次的划分结果相同。 :param data_size: 数据集大小 :return: 返回一个列表 """ number_set = [] for i in range(data_size): number_set.append(i) random.shuffle(number_set) return number_set def split_data_set(data_set, target_data, rate=0.25): """ 说明:分割数据集,默认数据集的25%是测试集 :param data_set: 数据集 :param target_data: 标签数据 :param rate: 测试集所占的比率 :return: 返回训练集数据、训练集标签、训练集数据、训练集标签 """ # 计算训练集的数据个数 train_size = int((1-rate) * len(data_set)) # 获得数据 data_index = random_number(len(data_set)) # 分割数据集(X表示数据,y表示标签),以返回的index为下标 x_train = data_set[data_index[:train_size]] x_test = data_set[data_index[train_size:]] y_train = target_data[data_index[:train_size]] y_test = target_data[data_index[train_size:]] return x_train, x_test, y_train, y_test def data_diatance(x_test, x_train): """ :param x_test: 测试集 :param x_train: 训练集 :return: 返回计算的距离 """ # sqrt_x = np.linalg.norm(test-train) # 使用norm求二范数(距离) distances = np.sqrt(sum((x_test - x_train) ** 2)) return distances def knn(x_test, x_train, y_train, k): """ :param x_test: 测试集数据 :param x_train: 训练集数据 :param y_train: 测试集标签 :param k: 邻居数 :return: 返回一个列表包含预测结果 """ # 预测结果列表,用于存储测试集预测出来的结果 predict_result_set=[] # 训练集的长度 train_set_size = len(x_train) # 创建一个全零的矩阵,长度为训练集的长度 distances = np.array(np.zeros(train_set_size)) # 计算每一个测试集与每一个训练集的距离 for i in x_test: for indx in range(train_set_size): # 计算数据之间的距离 distances[indx] = data_diatance(i, x_train[indx]) # 排序后的距离的下标 sorted_dist = np.argsort(distances) class_count = {} # 取出k个最短距离 for i in range(k): # 获得下标所对应的标签值 sort_label = y_train[sorted_dist[i]] # 将标签存入字典之中并存入个数 class_count[sort_label]=class_count.get(sort_label, 0) + 1 # 对标签进行排序 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) # 将出现频次最高的放入预测结果列表 predict_result_set.append(sorted_class_count[0][0]) # 返回预测结果列表 return predict_result_set def score(predict_result_set, y_test): """ :param predict_result_set: 预测结果列表 :param y_test: 测试集标签 :return: 返回测试集精度 """ count = 0 for i in range(0, len(predict_result_set)): if predict_result_set[i] == y_test[i]: count += 1 score = count / len(predict_result_set) return score if __name__ == "__main__": iris_dataset = openfile('iris.csv') # x_new = np.array([[5, 2.9, 1, 0.2]]) x_train, x_test, y_train, y_test = split_data_set(iris_dataset[0], iris_dataset[1]) result = knn(x_test,x_train, y_train, 6) print("原有标签:", y_test) # 为了方便对比查看,此处将预测结果转化为array,可直接打印结果 print("预测结果:", np.array(result)) score = score(result, y_test) print("测试集的精度:%.2f" % score) 运算结果
|
 图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。  但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。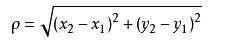 这个高中应该就有接触到的了,其实就是计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样
这个高中应该就有接触到的了,其实就是计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样 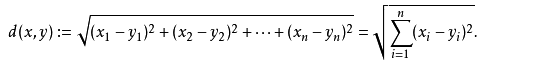 这样我们就明白了如何计算距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。但其实也可以通过一些数据结构来辅助,比如最大堆,这里就不多做介绍,有兴趣可以百度最大堆相关数据结构的知识。
这样我们就明白了如何计算距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。但其实也可以通过一些数据结构来辅助,比如最大堆,这里就不多做介绍,有兴趣可以百度最大堆相关数据结构的知识。 这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。 简单得说,当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了。
简单得说,当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了。 结果不同,因为每次划分的训练集和测试集不同。
结果不同,因为每次划分的训练集和测试集不同。【本文地址】