| 标准化和归一化 超全详解 | 您所在的位置:网站首页 › knn算法需要做归一化吗 › 标准化和归一化 超全详解 |
标准化和归一化 超全详解
|
原理说明
一、标准化 / 归一化定义
归一化和标准化经常被搞混,程度还比较严重,非常干扰大家的理解。为了方便后续的讨论,必须先明确二者的定义。 首先定义常见的结构化数据表格,第一行的表头是表示各种特征,而后每一列表示某种特征的所有数值。 无论标准化还是归一化都是针对某个特征(某一列)进行操作的。 1. 归一化 就是将训练集中某一列数值特征(假设是第 i i i 列)的值缩放到0和1之间。方法如下所示: x i − min ( x i ) max ( x i ) − min ( x i ) \frac{x_{i}-\min \left(x_{i}\right)}{\max \left(x_{i}\right)-\min \left(x_{i}\right)} max(xi)−min(xi)xi−min(xi) 2. 标准化 就是将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。如下所示: x i − x ˉ σ ( x ) \frac{x_{i}-\bar{x}}{\sigma(x)} σ(x)xi−xˉ 3. 进一步明确二者含义 归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row)进行缩放。对特征向量进行缩放是毫无意义的(暗坑1) 比如三列特征:身高、体重、血压。每一条样本(row)就是三个这样的值,对这个row无论是进行标准化还是归一化都是好笑的,因为你不能将身高、体重和血压混到一起去! 在线性代数中,将一个向量除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量,它和我们这里的标准化不是一回事儿,不能搞混(暗坑2)。 二、标准化/归一化的好处 2.1 提升模型精度在机器学习算法的目标函数(例如 SVM 的 RBF 内核或线性模型的 L1 和 L2 正则化),许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。 举一个简单的例子,在KNN中,我们需要计算待分类点与所有实例点的距离。假设每个实例点(instance)由n个features构成。如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。 经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。 2.2 提升收敛速度对于线性model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
比如两个变量的量纲不同,可能一个的数值远大于另一个那么他们同时作为变量的时候 可能会造成数值计算的问题,比如说求矩阵的逆可能很不精确 Machine-Learning-Note(机器学习笔记) 三、标准化/归一化的对比分析首先明确,在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。原因有两点: 标准化更好保持了样本间距。 当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。标准化更符合统计学假设 对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。所以,下面的讨论我们先集中分析标准化在机器学习中运用的情况,在文章末尾,简单探讨一下归一化的使用场景。这样更能凸显重点,又能保持内容的完整性,暂时忘记归一化,让我们focus到标准化上吧。 四、逻辑回归必须要进行标准化吗?面试时,无论你回答必须或者不必须,你都是错的! 4.1 是否正则化真正的答案是,这取决于我们的逻辑回归是不是用正则。 如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。(暗坑3)为什么呢? 因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是: 身 高 = w ∗ 体 重 身高 = w * 体重 身高=w∗体重 w w w 就是我们训练出来的参数。 当我们的体重用吨来衡量时, w w w 的值就会扩大为原来的 1000 1000 1000 倍。 在上面两种情况下,都用 L1 正则的话,显然对模型的训练影响是不同的。 假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在 L1 正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致 L1 最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。 4.2 标准化对 LR 的好处如果你回答到这里,面试官应该基本满意了,但是他可能会进一步考察你,如果不用正则,那么标准化对逻辑回归有什么好处吗? 答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。 4.3 标准化的注意事项答到这里,有些厉害的面试官可能会继续问,做标准化有什么注意事项吗? 最大的注意事项就是先拆分出 test 集,只在训练集上标准化, 即均值和标准差是从训练集中计算出来的,不要在整个数据集上做标准化,因为那样会将 test 集的信息引入到训练集中,这是一个非常容易犯的错误! 五、哪些模型需要标准化,哪些不需要? 5.1 需要标准化的模型 线性回归,LR,Kmeans,KNN, SVM 等一些涉及到距离有关的算法,聚类算法 PCA等GBDT、adaboost 因为GBDT的树是在上一颗树的基础上通过梯度下降求解最优解,归一化能收敛的更快,GBDT通过减少bias来提高性能1、一般算法如果本身受量纲影响较大,或者相关优化函数受量纲影响大,则需要进行特征归一化。 2、树模型特征归一化可能会降低模型的准确率,但是能够使模型更加平稳 5.2 不需要标准化的模型当然,也不是所有的模型都需要做归一的,比如模型算法里面没有关于对距离的衡量,没有关于对变量间标准差的衡量。比如 decision tree 决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的。 概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、随机森林(RF)。 对于树形结构为什么不需要归一化? 因为数值缩放不影响分裂点位置,对树模型的结构不造成影响。 按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。 而且,树模型是不能进行梯度下降的,因为构建树模型(回归树)寻找最优点时是通过寻找最优分裂点完成的,因此树模型是阶跃的,阶跃点是不可导的,并且求导没意义,也就不需要归一化。所以树模型(回归树)寻找最优点是通过寻找最优分裂点完成的 5.3 特殊说明要强调:能不归一化最好不归一化,之所以进行数据归一化是因为各维度的量纲不相同。而且需要看情况进行归一化。 有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。 有些模型伸缩有与原来等价,如:LR则不用归一化,但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最坏进行数据归一化。 补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。 代码实现 使用 sklearn 的 StandardScaler() 函数可以;或者自己按照公式写函数 normalize() 亦可结果一致 import numpy as np from sklearn.preprocessing import StandardScaler def normalize(data): _mean = np.mean(data, axis=0) _std = np.std(data, axis=0) new_data = (data - _mean) / _std return new_data if __name__ == "__main__": test_data = np.array([[1,11,120,1000], [2,25,300,2000], [3,34,390,3000], [4,40,460,4000], [5,50,500,5200]]) print("test_data:\n", test_data) res_1 = normalize(test_data) print("res1:\n", res_1) scaler = StandardScaler() res_2 = scaler.fit_transform(test_data) print("res2:\n", res_2)输出: test_data: [[ 1 11 120 1000] [ 2 25 300 2000] [ 3 34 390 3000] [ 4 40 460 4000] [ 5 50 500 5200]] res1: [[-1.41421356 -1.58113883 -1.72958876 -1.38599238] [-0.70710678 -0.52704628 -0.39913587 -0.70658435] [ 0. 0.15058465 0.26609058 -0.02717632] [ 0.70710678 0.6023386 0.78348892 0.65223171] [ 1.41421356 1.35526185 1.07914512 1.46752135]] res2: [[-1.41421356 -1.58113883 -1.72958876 -1.38599238] [-0.70710678 -0.52704628 -0.39913587 -0.70658435] [ 0. 0.15058465 0.26609058 -0.02717632] [ 0.70710678 0.6023386 0.78348892 0.65223171] [ 1.41421356 1.35526185 1.07914512 1.46752135]] 参考: [机器学习] 数据特征 标准化和归一化你了解多少?树形结构为什么不需要归一化,树模型为什么是不能进行梯度下降面试笔试整理3:深度学习机器学习面试问题准备(必会) |
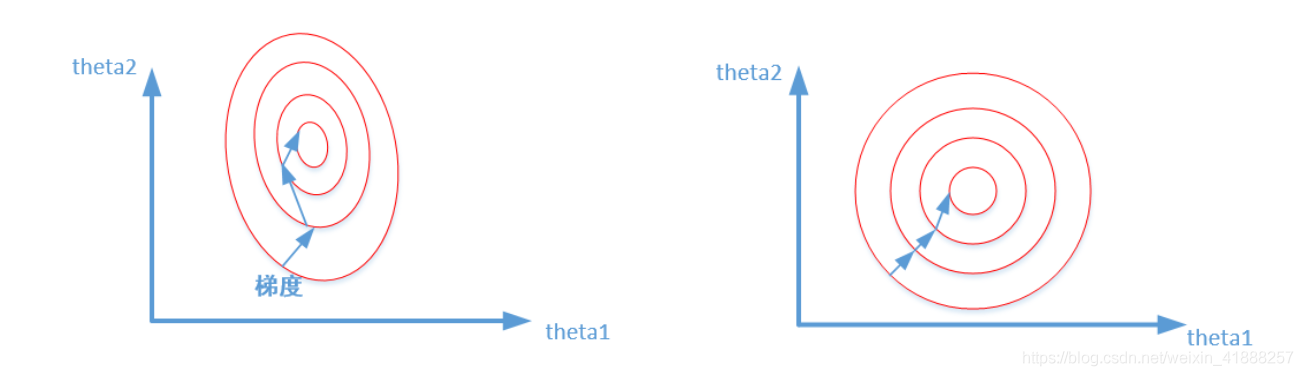 比较这两个图,前者是没有经过归一化的,在梯度下降的过程中,走的路径更加的曲折,而第二个图明显路径更加平缓,收敛速度更快。 对于神经网络模型,避免饱和是一个需要考虑的因素,通常参数的选择决定于 input 数据的大小范围。
比较这两个图,前者是没有经过归一化的,在梯度下降的过程中,走的路径更加的曲折,而第二个图明显路径更加平缓,收敛速度更快。 对于神经网络模型,避免饱和是一个需要考虑的因素,通常参数的选择决定于 input 数据的大小范围。【本文地址】