| 机器学习笔记四之kNN算法、超参数、数据归一化 | 您所在的位置:网站首页 › knn算法的基本思想 › 机器学习笔记四之kNN算法、超参数、数据归一化 |
机器学习笔记四之kNN算法、超参数、数据归一化
|
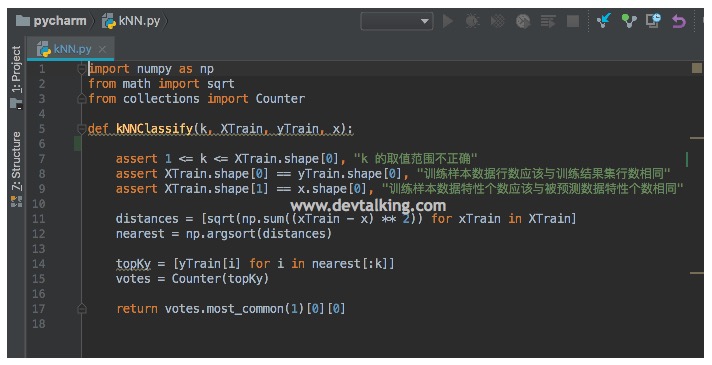
上一篇笔记主要介绍了NumPy,Matplotlib和Scikit Learn中Datasets三个库的用法,以及基于欧拉定理的kNN算法的基本实现。这一篇笔记的主要内容是通过PyCharm封装kNN算法并且在Jupyter Notebook中调用,以及计算器算法的封装规范,kNN的k值如何计算,如何使用Scikit Learn中的kNN算法,还有机器学习算法中的一些主要概念,比如训练数据集、测试数据集,分类准确度,超参数,数据归一化。另外会具体用代码实现第一篇笔记中介绍过的线性回归算法。 封装kNN算法上一篇笔记中我们对kNN算法在Jupyter Notebook中进行了实现,但是想要复用这个算法就很不方便,所以我们来看看如何在PyCharm中封装算法,并且在Jupyter Notebook中进行调用。 PyCharm的配置这里我就不再累赘,如图所示,我们创建了一个Python文件kNN.py,然后定义了kNNClassify方法,该方法有4个参数,分别是kNN算法的k值,训练样本特征数据集XTrain,训练样本类别数据集yTrain,预测特征数据集x。该方法中的实现和在Jupyter Notebook中实现的一模一样,只不过加了三个断言,让方法的健壮性更好一点。我们给出N维欧拉定理: $$ \sqrt {\sum_{i=1}^n(x_i^{(a)}-x_i^{(b)})^2} $$
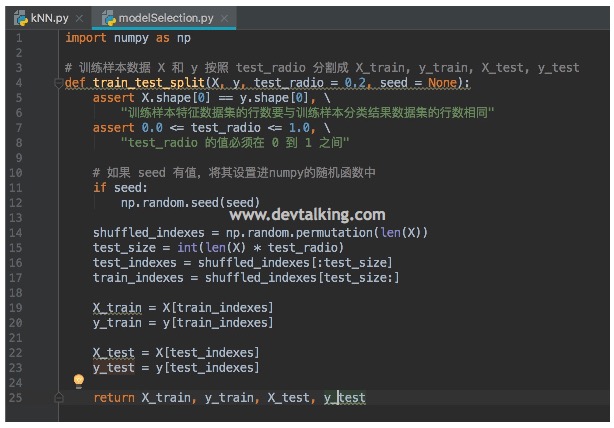
上面的代码清晰的定义了fit和predict方法,至于_predict这个私有方法可以随意,可以将逻辑直接写在predict方法里,也可以拆分出来。然后我们在Jupyter Notebook中再来使用一下我们封装的kNN算法: %run ../pycharm/kNN/kNN.pymyKNNClassifier = KNNClassifier(6)myKNNClassifier.fit(XTrain, yTrain)# 结果kNN(k=6)xTrain = x.reshape(1, -1)myKNNClassifier.predict(xTrain)# 结果array([1]) 判断机器学习算法的性能现在大家应该知道机器算法的目的主要是训练出模型,然后输入样本,通过模型来预测结果,可见这个模型是非常关键的,模型的好坏直接影响预测结果的准确性,继而对实际运用会产生巨大的影响。模型的训练除了机器学习算法以外,对它影响比较大的还有训练样本数据,我们在实现kNN算法时,是将所有的样本数据用于训练模型,那么模型训练出来后就已经没有数据供我们验证模型的好坏了,只能直接投入真实环境使用,这样的风险是很大的。 所以为了避免上述这种情况,最简单的做法是将所有训练样本数据进行切分,将大部分数据用于训练模型,而另外一小部分数据用来测试训练出的模型,这样如果我们用测试数据发现这个模型不够好,那么我们就有机会在将模型投入真实环境使用之前改进算法,训练出更好的模型。 我们来看看如何封装拆分训练数据的方法: 从上面代码运行的结果来看,最优的p值为2,也就是欧拉距离,考虑了距离权重后,最优k值为3。而且一些超参数是组合使用的,比如当使用超参数p时,距离权重的超参数weights的取值就必须是distance。并且k和p这两个超参数双重嵌套循环,就组成了一个类似网格的搜索方式,所幸Scikit Learn提供了封装好的网格搜索的方法供我们使用。 网格搜索超参数在使用网格搜索前,我们需要先将各种超参数的组合定义出来: param_grid = [ { 'weights': ['uniform'], 'n_neighbors': [i for i in range(1, 11)] }, { 'weights': ['distance'], 'n_neighbors': [i for i in range(1, 11)], 'p': [i for i in range(1, 6)] }]我们定义了一个param_grid数组,元素为字典,每个字典描述了一种超参数的组合,下面我们使用Scikit Learn提供的GridSearchCV来使用我们定义好的超参数组合: from sklearn.model_selection import GridSearchCVknn_clf = KNeighborsClassifier()grid_search = GridSearchCV(knn_clf, param_grid)grid_search.fit(X_train, y_train)new_knn_clf = grid_search.best_estimator_new_knn_clf# 结果KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=3, p=3, weights='distance')上面的示例代码不难理解,我们使用构建出的kNN分类器knn_clf和超参数组合param_grid构造出了网格搜索对象grid_search,通过它进行fit操作,这个过程就是根据我们提供的超参数组合进行搜寻,找到最优的超参数组合。通过best_estimator_返回新的,已经设置了最优超参数组合的kNN分类器对象。从输出结果其实已经可以看到首先是选择了考虑距离权重的超参数组合,然后求出了k值,也就是n_neighbors为3,p值为3。 GridSearchCV也提供了几个属性,可以让我们方便的查看超参数和模型评分: grid_search.best_params_# 结果{'n_neighbors': 3, 'p': 3, 'weights': 'distance'}grid_search.best_score_# 结果0.98538622129436326 GridSearchCV的其他参数在构造GridSearchCV对象时除了kNN分类器和超参数组合外,还有几个比较有用的参数: n_jobs:该参数决定了在进行网格搜索时使用当前计算机的CPU核数,1就是使用1个核,2就是使用2个核,如果设置为-1,那么代表使用所有的核进行搜索。 verbose:该参数决定了在网格搜索时的日志输出级别。 数据归一化
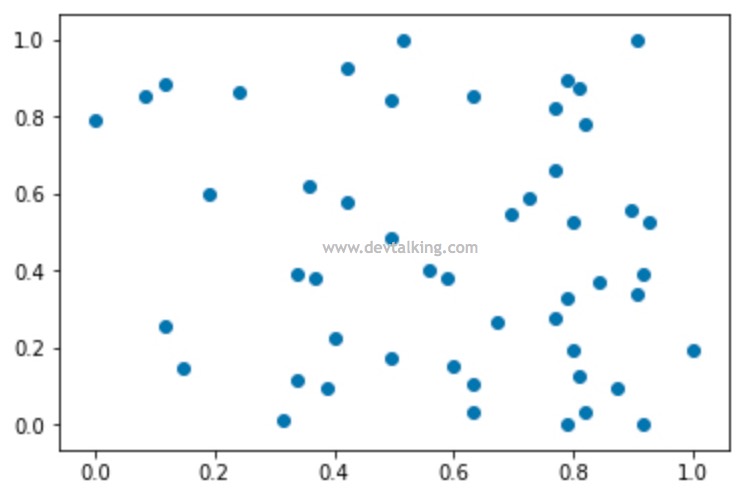
大家先看看上面表格中的样本数据,两个样本的肿瘤大小相差有5倍,从医学角度来讲这个差距已经是非常大了,但从实际数值差距来讲并不是很大。再看看发现时间,两个样本之间相差100天,在数值上的差距远远大于肿瘤大小的差距。所以如果使用kNN算法,用欧拉距离计算的话,两个样本发现时间之差远远大于肿瘤大小之差,所以就会主导样本间的距离,这个显然是有问题的,对预测的结果是有偏差的。 所以我们就需要对样本数据进行数据归一化,将所有的数据映射到同一尺度。比较简便的方式就是最值归一化,既用下面的公式把所有数据映射到0-1之间: $$ x_{scale} = \frac {x - x_{min}} {x_{max} - x_{min}} $$ 最值归一化虽然简便,但是是有一定适用范围的,那就是适用于样本数据有明显分布边界的情况,比如学生的考试分数,从0到100分,或者像素值,从0到255等。假如像人的月收入这种没有边界的样本数据集,就不能使用最值归一化了,此时就需要用到另外一个数据归一化的方法均值方差归一化,该方法就是把所有数据归一到均值为0方差为1的分布中,公式如下: $$ x_{scale} = \frac {x - x_{mean}} S $$ 就是将每个值减去均值,然后除以方差,通过均值方差归一化后的数据不一定在0-1之间,但是他们的均值为0,方差为1。 下面我们来分别实现一下这两个数据归一化方法。先来看看最值归一化的实现: import numpy as npimport matplotlib.pyplot as plt# 生成从0到100,一共100个元素的数组x = np.random.randint(0, 100, size = 100)# 变更数组元素的类型x = np.array(x, dtype = float)x_scale = (x - np.min(x)) / (np.max(x) - np.min(x))# 生成50行,2列的矩阵,元素在0到100之间X = np.random.randint(0, 100, (50, 2))# 对每一列数据进行最值归一化X[:, 0] = (X[:, 0] - np.min(X[:, 0])) / (np.max(X[:, 0]) - np.min(X[:, 0]))X[:, 1] = (X[:, 1] - np.min(X[:, 1])) / (np.max(X[:, 1]) - np.min(X[:, 1]))# 用matplotlib将X展示出来plt.scatter(X[:, 0], X[:, 1])plt.show()
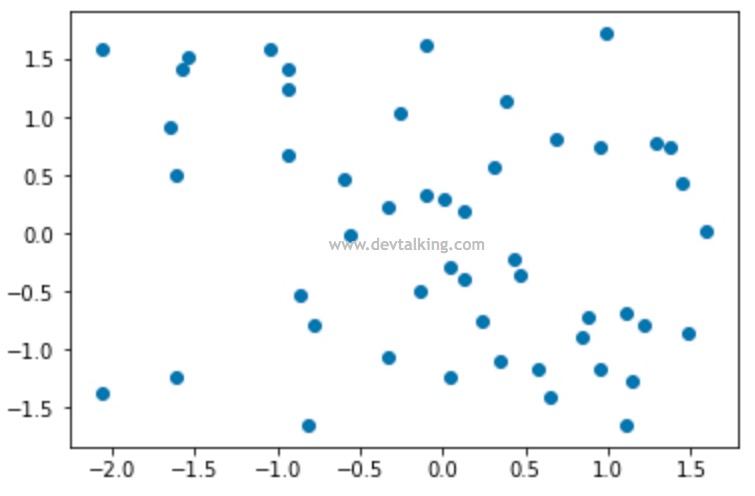
可以看到最值归一化后数据都在0到1之间。我们再来看看均值方差归一化的实现: X2 = np.random.randint(0, 100, (50, 2))X2 = np.array(X2, dtype = float)X2[:, 0] = (X2[:, 0] - np.mean(X2[:, 0])) / np.std(X2[:, 0])X2[:, 1] = (X2[:, 1] - np.mean(X2[:, 1])) / np.std(X2[:, 1])# 均值接近0np.mean(X2[:, 0])# 结果6.2172489379008772e-17# 方差接近1np.std(X2[:, 0])# 结果0.99999999999999989plt.scatter(X2[:, 0], X2[:, 1])plt.show()
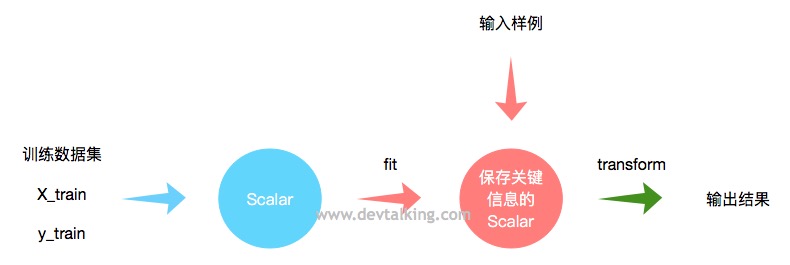
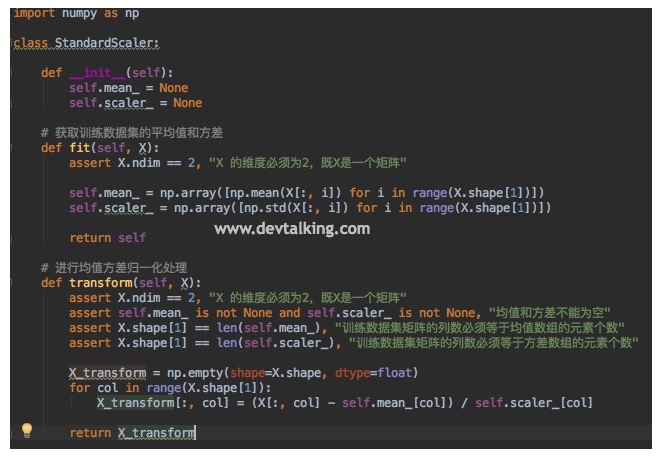
之前我们说过会对样本数据进行拆分,拆分为训练数据和测试数据,对于训练数据我们可以直接使用最值归一化或均值方法归一化,但是对测试数据我们就不能直接使用归一化的方法了,因为测试数据其实充当了真实环境中需要预测的数据,很多时候需要预测的数据只有一组,这时候我们是没办法对一组数据进行归一化的,因为无法得到均值和方差,所以我们需要结合归一化后训练数据归一化测试数据:(x_test - mean_train) / std_train。那么我们就需要保存训练数据归一化后的数据,此时我们就可以用到Scikit Learn提供的数据归一化的对象Scalar。
Scalar的使用流程和机器学习算法的使用流程很像,输入训练数据集,进行fit操作,这里的fit操作就不是训练模型了,而是进行数据归一化处理,然后是transform,既对需要预测的数据进行归一化。我们来看看如何使用: # 使用鸢尾花数据集import numpy as npfrom sklearn import datasetsiris = datasets.load_iris()X = iris.datay = iris.target# 分割出训练数据集和测试数据集from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)# 导入StandardScaler,也就是均值方差归一化的对象from sklearn.preprocessing import StandardScalerstandardScaler = StandardScaler()standardScaler.fit(X_train)# 将特征训练数据集和特征测试数据集进行归一化处理X_train_standard = standardScaler.transform(X_train)X_test_standard = standardScaler.transform(X_test)# 使用kNNfrom sklearn.neighbors import KNeighborsClassifierknn_clf = KNeighborsClassifier(n_neighbors = 3)knn_clf.fit(X_train_standard, y_train)knn_clf.score(X_test_standard, y_test) 封装自己的数据归一化方法
这样我们就封装好了自己的均值方差归一化的方法,另外,Scikit Learn也提供了最值归一化的对象MinMaxScaler,使用流程都是一样的,大家也可是试试看。 总结这一篇笔记主要介绍了kNN算法实现逻辑以外的概念,但也是机器学习中非常重要的一些概念,以后也会经常看到它们的身影。通过两篇笔记的介绍,我们知道kNN算法是一个解决多分类问题的算法,而且算法实现相对比较简单,但效果很强大。下一篇我们来实现第一篇笔记中介绍过的线性回归法。 申明:本文为慕课网liuyubobobo老师《Python3入门机器学习 经典算法与应用》课程的学习笔记,未经允许不得转载。 |

【本文地址】