| Kaggle踩坑指南 | 您所在的位置:网站首页 › kaggle比赛数据集需要下载吗 › Kaggle踩坑指南 |
Kaggle踩坑指南
|
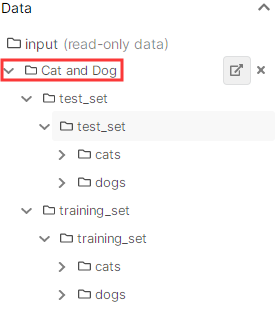
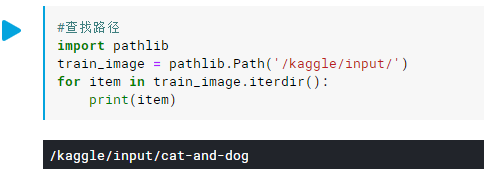
新建的kaggle如下图所示,点击上方的 add data, 即可搜索并添加想使用的数据集,新添加的数据集会放入input文件夹下。 需要特别注意的是,添加到input后显示的文件路径可能和实际的文件路径不一致,比如这个猫狗数据集的input中显示如下,是/input/Cat and Dog/,但实际上的路径是/input/cat-and-dog/, 如果输错路径会导致数据无法读取 输出如下: 输出如下: 若想要读取train_set或test_set数据集下的所有图片的路径,可以采用glob。但是有可能出现路径前方有PosixPath(据说是系统的缘故),因此还需要对路径进行转换处理。此外,对于深度学习网络而言,最好对图像进行乱序处理。以train_set为例,整体代码如下: import random import pathlib import glob train_images = pathlib.Path('/kaggle/input/cat-and-dog/training_set/training_set/') train_images=list(train_images.glob('*/*.jpg')) train_images= [str(path) for path in train_images] #去掉PosixPath random.shuffle(train_images) #乱序 2. 根据图像路径制作labels分类一般可分为:二分类或者多分类。 1> 二分类分析路径 以猫狗数据集为例,分析二分类问题。猫狗数据集的路径为: ‘/kaggle/input/cat-and-dog/training_set/training_set/cats/cat.4942.jpg’, 其中, 标签cat在图片名称中,可通过split进行提取。 train_labels = list(map(lambda x: float(x.split('/')[7].split('.')[0] == 'cat'), train_images))lambda的详情可参考:关于Python中的lambda,这篇阅读量10万+的文章可能是你见过的最完整的讲解 此处lambda与map合用相当于:lambda函数用于指定对列表train_images中每一个元素的共同操作 若==成立,表示当前标签为cat,label=1; 若当前标签为dog,则label=0。 2> 多分类对于多分类的数据集,需要先构建标签类别名称,在对标签类别名称进行编码,最后通过已有的编码字典,制作所有图像的labels。 data_root='/kaggle/input/cat-and-dog/training_set/training_set/' label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir()) #sorted根据首字母排序, is_dir()检测是否为一个目录 label_to_index = dict((name, index) for index,name in enumerate(label_names)) #编码 all_image_labels = [label_to_index[pathlib.Path(path).parent.name] for path in all_image_paths] #列表推导式最后,可将获得的图像路径和labels转成tensorflow中的格式,并合在一个数据集中。 train_dataset = tf.data.Dataset.from_tensor_slices((train_images,train_labels)) 二、图像预处理 def _pre_read(img_filename, label): image = tf.io.read_file(img_filename) image = tf.image.decode_jpeg(image,channels=3) image = tf.image.rgb_to_grayscale(image) image = tf.image.resize(image,[200,200]) image = tf.reshape(image,[200,200,1]) image = tf.image.per_image_standardization(image) #或者:image = image/255 label = tf.reshape(label,[1]) return image, label BATCH_SIZE = 32 train_dataset = train_dataset.map(_pre_read) train_dataset = train_dataset.shuffle(300) train_dataset = train_dataset.repeat() train_dataset = train_dataset.batch(BATCH_SIZE)其中,shuffle的作用是使训练数据乱序,且这里repeat是重复乱序,即每次训练都会乱序抽取图像。 举个栗子: 设10000个训练样本, BATCH_SIZE = 32, 则steps_per_epoch = train_count//BATCH_SIZE= 10000/32= 310, 将前300个小组输入到buffer里, 当调用dataset时, 从buffer中随机选择一个小组; 然后从原数据集剩余的小组(10个)中随机选择一个小组, 填补到buffer中目前空缺的那个位置 配图食用,效果更佳:tf.data.Dataset.shuffle(buffer_size)中buffer_size的理解 |
 在kaggle训练的数据集都是在线添加,如果想要训练自己的数据集,需要上传数据集,但是这需要翻(你懂的。。。)。此处以猫狗数据集为例。
在kaggle训练的数据集都是在线添加,如果想要训练自己的数据集,需要上传数据集,但是这需要翻(你懂的。。。)。此处以猫狗数据集为例。 
 这里介绍两种方法:
这里介绍两种方法:
【本文地址】