| Neo4j导入数据的5种方式详解配图 | 您所在的位置:网站首页 › json文件是什么格式的数据类型 › Neo4j导入数据的5种方式详解配图 |
Neo4j导入数据的5种方式详解配图
|
一、前言
Neo4j导入数据的方式有: 使用LOAD CSV导入数据使用APOC导入数据使用编程语言(Java,python,js,C#,Go)导入数据使用neo4j-admin工具导入数据使用应用导入数据使用ETL工具导入数据具体选择哪种导入方法取决于: 数据量大小使用者对导入方法的轻松度感受有多少时间来导入 各种导入方法的精力-效率图像如下图: 横坐标表示导入的效率,LOAD CSV导入比较慢,而neo4j-admin工具导入比较快。 纵坐标表示人耗费的精力,LOAD CSV比较易上手,而使用编程语言如Java/Python等导入数据比较耗费精力。
二、使用LOAD CSV来导入数据 横坐标表示导入的效率,LOAD CSV导入比较慢,而neo4j-admin工具导入比较快。 纵坐标表示人耗费的精力,LOAD CSV比较易上手,而使用编程语言如Java/Python等导入数据比较耗费精力。
二、使用LOAD CSV来导入数据
CSV格式的数据是文本数据,数据之间用英文逗号隔开。 支持的数据类型:仅CSV 好处:操作简单。 坏处:运行时间长 用Cypher加载数据的步骤: CSV文件组织结构规范化数据确保ID唯一确保CSV中的数据是干净的执行Cypher代码来检查数据确定数据是否需要转化确保有必要的数据约束确定加载数据量的大小执行Cypher代码来加载数据 10.为图数据添加索引(1)CSV文件结构
(6)确定是否需要转化 创建结点有MERGE和CREATE两种方式,MERGE比CREATE多了检查唯一性。 (8)确定加载数据量的大小 LOAD CSV这种方式只能加载100K的数据量。 若超出100K的csv文件,有两种方式解决: :auto USING PERIODIC COMMIT使用APOC,下一节 第一种方式相当于分批次插入数据,例如每次插入1000条。但是遇到eager类型的聚合函数方法时,第一种方式会失效,eager类型的聚合函数有:collect(), count(), order by, distinct,这时候只能使用第二种方式。 (9)执行Cypher代码来加载数据 a. 导入电影结点 :auto USING PERIODIC COMMIT 500 #每次循环插入500个结点 LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/v4.0-intro-neo4j/movies1.csv' as row MERGE (m:Movie {id:toInteger(row.movieId)}) ON CREATE SET m.title = row.title, m.avgVote = toFloat(row.avgVote), m.releaseYear = toInteger(row.releaseYear), m.genres = split(row.genres,":")b. 导入演员结点 :auto USING PERIODIC COMMIT 500 LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/v4.0-intro-neo4j/people.csv' as row MERGE (p:Person {id:toInteger(row.personId)}) ON CREATE SET p.name=row.name, p.birthYear=toInteger(row.birthYear), p.deathYear=toInteger(row.deathYear)c. 导入“导演”关系 LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/v4.0-intro-neo4j/directors.csv' AS row MATCH (movie:Movie {id:toInteger(row.movieId)}) MATCH (person:Person {id: toInteger(row.personId)}) MERGE (person)-[:DIRECTED]->(movie) ON CREATE SET person:Director(10)为图数据添加索引 CREATE INDEX MovieTitleIndex FOR (m:Movie) ON (m.title); CREATE INDEX PersonNameIndex FOR (p:Person) ON (p.name) 三、使用APOC数据支持数据格式:CSV,XML,GraphXML,JSON 使用APOC导入数据的要求: CSV,XML,或JSON文件已备好Neo4j Browser或Cypher-shell已打开,Neo4j DBMS在本地运行,或Aura,或Sandbox可选(不是必须):在Neo4j集群上对导入数据集大小没有限制 四、使用编程语言导入数据
-2- Python语言 pip install neo4j from neo4j import GraphDatabase class HelloWorldExample: def __init__(self, uri, user, password): self.driver = GraphDatabase.driver(uri, auth=(user, password)) def close(self): self.driver.close() def print_greeting(self, message): with self.driver.session() as session: greeting = session.write_transaction(self._create_and_return_greeting, message) print(greeting) @staticmethod def _create_and_return_greeting(tx, message): result = tx.run("CREATE (a:Greeting) " "SET a.message = $message " "RETURN a.message + ', from node ' + id(a)", message=message) return result.single()[0] if __name__ == "__main__": greeter = HelloWorldExample("bolt://localhost:7687", "neo4j", "password") greeter.print_greeting("hello, world") greeter.close() 五、使用neo4j-admin工具导入数据支持的数据格式:仅CSV,只能在Desktop端使用,Sandbox和Aura不支持使用该工具。 好处:导入时间少,效率高,支持导入数据很大(如超过10M),一次性导入多个CSV文件 缺点:neo4j数据库必须在导入完成后才能使用  (2)或将头信息与数据存储在不同csv文件上 id,结点类型,日期,描述 (2)或将头信息与数据存储在不同csv文件上 id,结点类型,日期,描述   -2- 导入关系 开始结点id,结束结点id,关系类型 -2- 导入关系 开始结点id,结束结点id,关系类型 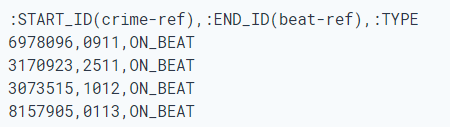 -3- 指定对应结点的首个Label 一个node可能有多个Label,如一个罪犯有多种罪名,选取一个主要罪名。 罪名列表Labels: -3- 指定对应结点的首个Label 一个node可能有多个Label,如一个罪犯有多种罪名,选取一个主要罪名。 罪名列表Labels:  罪犯首要罪名: 罪犯首要罪名:  -4- 导入语法
neo4j-admin import
database
nodes [,]
nodes==[,]
relationships [,]
relationships==[,]
trim-strings=true
> import.out
六、使用ETL工具导入数据 -4- 导入语法
neo4j-admin import
database
nodes [,]
nodes==[,]
relationships [,]
relationships==[,]
trim-strings=true
> import.out
六、使用ETL工具导入数据
能够实现DBMS和neo4j之间的实时连接来导入数据。 导入步骤: 确保dbms在运行,在desktop打开了ETL工具指定目标图数据库,因为一个neo4j dbms可以有多个图数据库指定和测试RDBMS的连接准备映射查看要执行的默认映射,也可以修改映射保存映射导入数据 七、总结
|
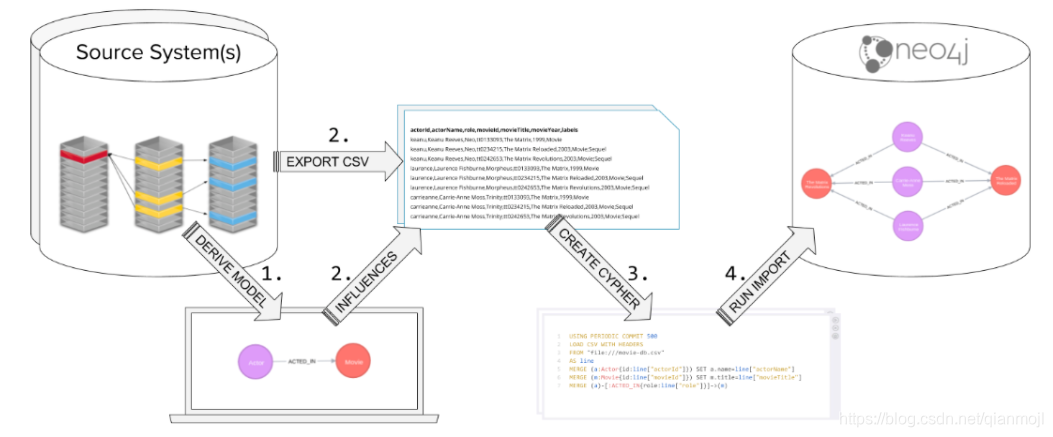 关键步骤就是:先生成CSV文件,然后用Cypher语句“LOAD CSV”将数据导入到Neo4j数据库中。 这种方式是最简单的导入数据到neo4j的方式,也是广泛使用来导入原始数据。 使用LOAD CSV导入数据的要求:
关键步骤就是:先生成CSV文件,然后用Cypher语句“LOAD CSV”将数据导入到Neo4j数据库中。 这种方式是最简单的导入数据到neo4j的方式,也是广泛使用来导入原始数据。 使用LOAD CSV导入数据的要求: CSV文件包括header和data两部分,当数据量较大且有多个files时,建议将header与data分离开。 (2)规范化数据
CSV文件包括header和data两部分,当数据量较大且有多个files时,建议将header与data分离开。 (2)规范化数据  people.csv表示演员表,movies1.csv表示电影表,roles.csv表示演员参演电影表,这时候可以将roles在图数据库中的关系规范化为*:ACTED_IN* (3)ID必须唯一 (4)数据干净吗?
people.csv表示演员表,movies1.csv表示电影表,roles.csv表示演员参演电影表,这时候可以将roles在图数据库中的关系规范化为*:ACTED_IN* (3)ID必须唯一 (4)数据干净吗?
 无论什么数据,导入到neo4j中都视为字符串,因此导入时可以预先进行转换。 (7)确定数据约束 一般主键id需要有唯一性约束。下面例子是为Movie和Person分别为id建立唯一性约束。
无论什么数据,导入到neo4j中都视为字符串,因此导入时可以预先进行转换。 (7)确定数据约束 一般主键id需要有唯一性约束。下面例子是为Movie和Person分别为id建立唯一性约束。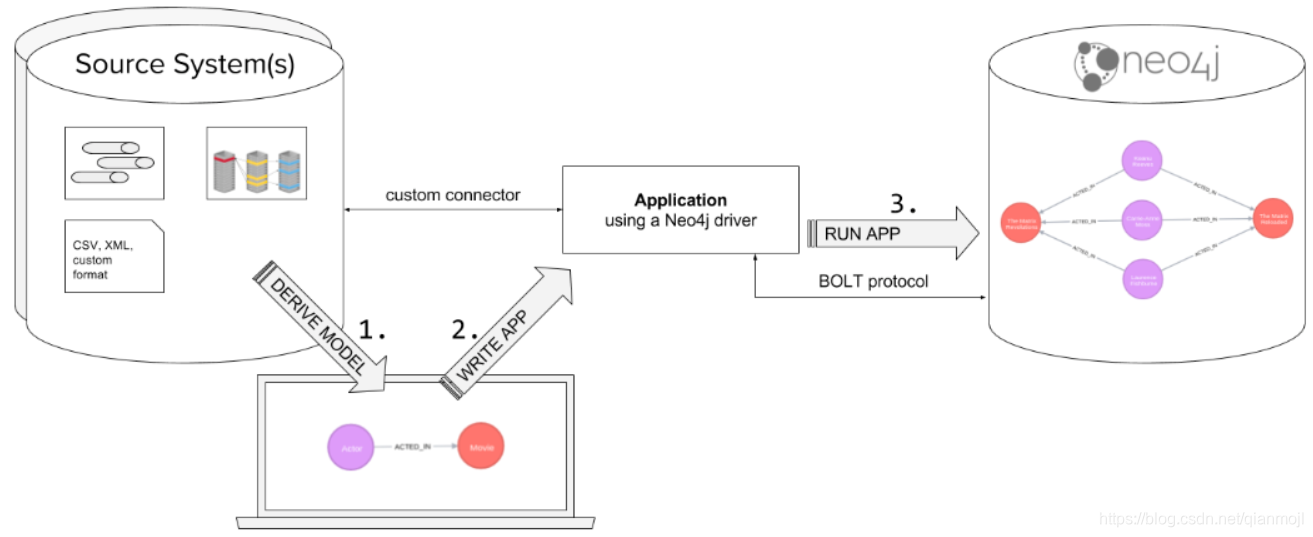 编程语言-驱动-Neo4j的方式来导入数据。 使用驱动导入数据的要求:
编程语言-驱动-Neo4j的方式来导入数据。 使用驱动导入数据的要求: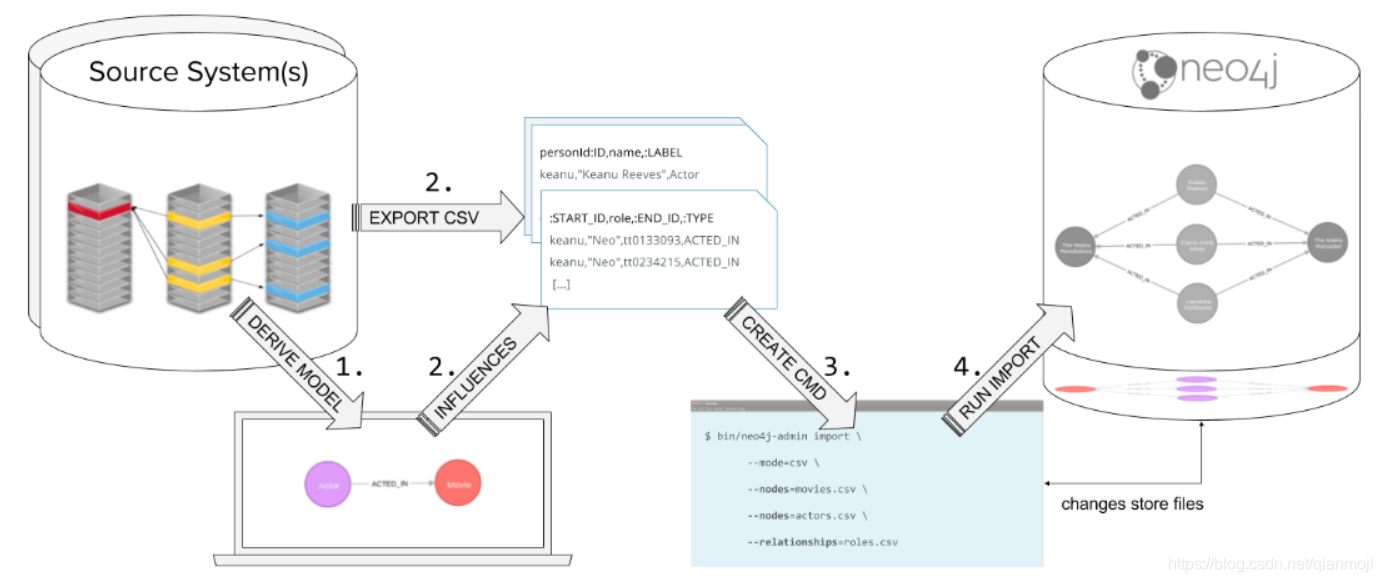 使用neo4j-admin工具导入数据的要求:
使用neo4j-admin工具导入数据的要求: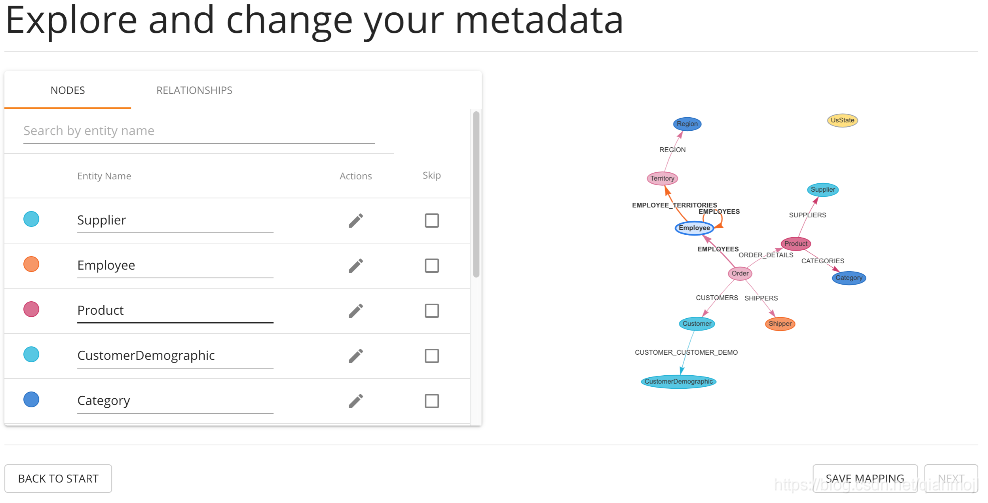 使用ETL工具导入数据的要求:
使用ETL工具导入数据的要求:
【本文地址】