| Java进程故障排查(CPU资源占用高,接口响应超时,功能接口停滞等) | 您所在的位置:网站首页 › java程序cpu过高 › Java进程故障排查(CPU资源占用高,接口响应超时,功能接口停滞等) |
Java进程故障排查(CPU资源占用高,接口响应超时,功能接口停滞等)
|
故障分析
# 导致系统不可用情况(频率较大): 1)代码中某个位置读取数据量较大,导致系统内存耗尽,进而出现Full GC次数过多,系统缓慢; 2)代码中有比较消耗CPU的操作,导致CPU过高,系统运行缓慢; # 导致某功能运行缓慢(不至于导致系统不可用): 3)代码某个位置有阻塞性的操作,导致调用整体比较耗时,但出现比较随机; 4)某线程由于某种原因进入WAITTING状态,此时该功能整体不可用,但无法复现; 5)由于锁使用不当,导致多个线程进入死锁状态,导致系统整体比较缓慢。
# 说明 对于后三种情况而言,是具有一定阻塞性操作,CPU和系统内存使用情况都不高,但功能却很慢,所以通过查看资源使用情况是无法查看出具体问题的! 应急处理### 对于线上系统突然产生的运行缓慢问题,如果导致线上系统不可用。首先要做的是导出jstack和内存信息,重启服务器,尽快保证系统的高可用。 ### 导出jstack信息 为避免重复赘述,此操作将在后面的"排查步骤"章节中体现!
### 导出内存堆栈信息 # 查看要导出的Java项目的pid # jps -l or # ps -ef |grep java # 导出内存堆栈信息 jmap -dump:live,format=b,file=heap8 # heap8是自定义的文件名 # 运行导出的堆栈文件 # ls heap8 # hostname -I 10.2.2.162 # jhat -port 9998 heap8
# 浏览器访问http://10.2.2.162:9998/
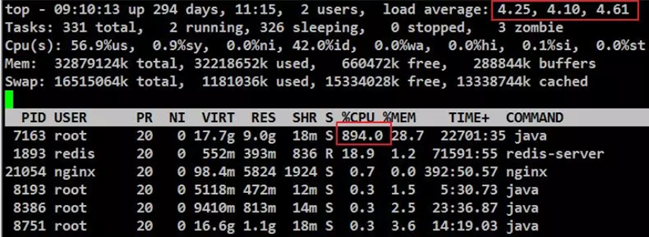
# 环境说明 因平台做了线上推广,导致管理平台门户网页进统计页面请求超时,随进服务器操作系统查看负载信息,load average超过了4,负载较大,PID为7163的进程cpu资源占用较高。
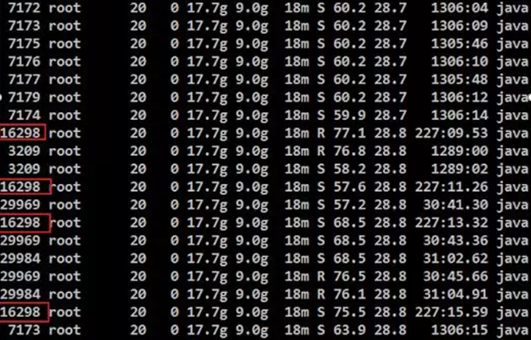
# 定位故障 # 处理思路: 找出CPU占用率高的线程,再通过线程栈信息找出该线程当时正在运行的问题代码段。 # 操作如下: # 查看高占用的"进程"中占用高的"线程" # top -Hbp 7163 | awk '/java/ && $9>50'
# 将16298的线程ID转换为16进制的线程ID # printf "%x\n" 16298 3faa # 通过jvm的jstack查看进程信息并保存以供研发后续分析 # jstack 7163 | grep "3faa" -C 20 > 7163.log
# 重点说明 通过排查步骤,可得排查问题需要掌握的信息如下: 1)资源占用高对应的进程a的PID; 2)进程a对应的资源占用高且最频繁的线程b的ID; 3)将线程b的ID转换为16进制的ID。 数据库问题引发的资源占用过高 ## 通过"排查步骤"章节可基本定位问题,后续请见下文! 确认问题及处理# jstack $pid | grep "3faa" -C 20 # 3faa指的是高占用进程中的高占用的线程对应的16进制id;
# 查看到是数据库的问题,排查思路:先打印所有在跑的数据库线程,检查后发现并跟进情况找到问题表; # 打印MySQL现有进程信息文件 # mysql -uroot -p -e "show full processlist" > mysql_full_process.log # 过滤出查询最多的表 grep Query mysql_full_process.log # 统计查询最多的表的数据量 > use databases_name; > select count(1) from table_name; # 结合MySQL日志信息,可判断问题是查询时间过长导致,排查后发现表未创建索引; > show create table table_name\G # 询问研发,确认数据不重要,检查字段由时间字段,根据时间确认只保留一个月的数据; > delete from table_name where xxxx_time < '2019-07-01 00:00:00' or xxxx_time is null; # 创建索引 > alter table table_name add index (device_uuid); # 确认索引是否创建 > show create table table_name; 总结 处理后进程的CPU占用降至正常水平,本次排查主要用到了jvm进程查看及dump进程详细信息的操作,确认是由数据库问题导致的原因,并对数据库进行了清理并创建了索引。 在处理问题后,又查询了一下数据库相关问题的优化,通常的优化方法还是添加索引。该方法添加参数具体如下: innodb_buffer_pool_size=4G Full GC次数过多## 通过"排查步骤"章节可基本定位问题,后续请见下文! 确认问题及处理# 特征说明 对于Full GC较多的情况,有以下特征: 1)进程的多个线程的CPU使用率都超过100%,通过jstack命令可看到大部分是垃圾回收线程; 2)通过jstat查看GC情况,可看到Full GC次数非常多,并数值在不断增加。
# 3faa指的是高占用进程中的高占用的线程对应的16进制id; # jstack $pid | grep "3faa" -C 20
说明:VM Thread指垃圾回收的线程。故基本可确定,当前系统缓慢的原因主要是垃圾回收过于频繁,导致GC停顿时间较长。 # 查看GC情况(1000指间隔1000ms,4指查询次数) # jstat -gcutil $pid 1000 4
说明:FGC指Full GC数量,其值一直在增加,图中显现高达6783,进一步证实是由于内存溢出导致的系统缓慢。
# 因笔者是运维,故确认了问题后,Dump内存日志后交由研发解决代码层面问题! 总结# 对于Full GC次数过大,主要有以下两种原因: 1)代码中一次性获取大量对象,导致内存溢出(可用Eclipse的Mat工具排查); 2)内存占用不高,但Full GC数值较大,可能是显示的System.gc()调用GC次数过多,可通过添加 -XX:+DisableExplicitGC 来禁用JVM 对显示 GC 的响应。 服务不定期出现接口响应缓慢 情况说明某个接口访问经常需要3~4s甚至更长时间才能返回。一般而言,其消耗的CPU和内存资源不多,通过上述方式排查问题无法行通。 由于接口耗时较长问题不定时出现,导致通过jstack命令得到线程访问的堆栈信息,根据其信息也不一定能定位到导致耗时操作的线程(概率事件)。 定位思路在排除网络因素后,通过压测工具对问题接口不断加大访问力度。当该接口中有某个位置是比较耗时的,由于访问的频率高,将导致大多数的线程都阻塞于该阻塞点。 通过分析多个线程日志,能得到相同的TIMED_WAITING堆栈日志,基本上就可定位到该接口中较耗时的代码的位置。
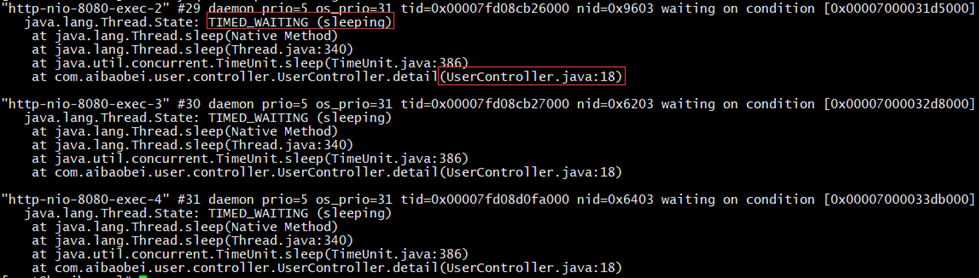
# 示例 # 代码中有比较耗时的阻塞操作,通过压测工具得到的线程堆栈日志,如下:
说明:由图可得,多个线程都阻塞在了UserController的第18行,说明此时一个阻塞点,也是导致该接口较缓慢的原因。 大总结# 总体性的分析思路 当Java应用出现问题时,处理步骤如下: 通过 top 命令定位异常进程pid,再 top -Hp 命令定位出CPU资源占用较高的线程的id,并将其线程id转换为十六进制的表现形式,再通过 jstack | grep 命令查看日志信息,定位具体问题。 # 此处根据日志信息分析,可分为两种情况,如下: # A情况 A.a)若用户线程正常,则通过该线程的堆栈信息查看比较消耗CPU的具体代码区域; A.b)若是VM Thread,则通过 jstat -gcutil 命令查看当前GC状态,然后通过 jmap -dump:live,format=b,file= 导出当前系统内存数据,用Eclipse的Mat工具进行分析,进而针对比较消耗内存的代码区进行相关优化。
# B情况 若通过top命令查看到CPU和内存使用率不高,则可考虑以下三种情况。 B.a)若是不定时出现接口耗时过长,则可通过压测方式增大阻塞点出现的概率,从而通过jstack命令查看堆栈信息,找到阻塞点; B.b)若是某功能访问时突然出现停滞(异常)状况,重启后又正常了,同时也无法复现。此时可通过多次导出jstack日志的方式,对比并定位出较长时间处于等待状态的用户线程,再从中筛选出问题线程; B.c)若通过jstack命令查看到死锁状态,则可检查产生死锁的线程的具体阻塞点,进而相应处理。 ======================================== 作者:罗穆瑞 出处:http://www.cnblogs.com/kazihuo/转载请保留此段声明,且在文章页面明显位置给出原文链接,谢谢! ============================================================================== ^_^ 如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,您的“推荐”将是我最大的写作动力 ^_^ ============================================================================== |




【本文地址】