| JUC#线程池加锁逻辑梳理 | 您所在的位置:网站首页 › java监视和管理控制台的区别 › JUC#线程池加锁逻辑梳理 |
JUC#线程池加锁逻辑梳理
|
带着问题看源码
为什么要用线程池?Java是实现和管理线程池有哪些方式? 请简单举例如何使用。为什么很多公司不允许使用Executors去创建线程池? 那么推荐怎么使用呢?ThreadPoolExecutor有哪些核心的配置参数? 请简要说明ThreadPoolExecutor可以创建的是哪三种线程池呢?当队列满了并且worker的数量达到maxSize的时候,会怎么样?执行拒绝策略说说ThreadPoolExecutor有哪些RejectedExecutionHandler策略? 默认是什么策略?简要说下线程池的任务执行机制? execute –> addWorker –>runworker (getTask)线程池中任务是如何提交的?submit方法线程池中任务是如何关闭的?shutdown方法在配置线程池的时候需要考虑哪些配置因素?如何监控线程池的状态?
为什么要用线程池?
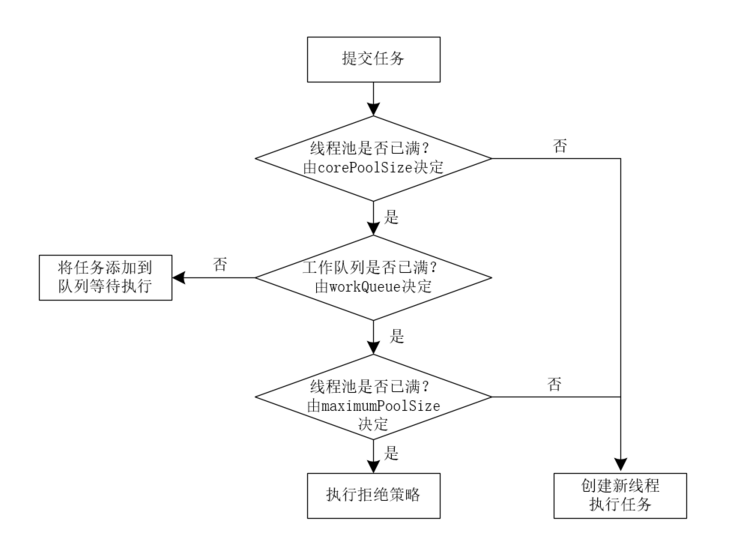
线程池可以对线程进行统一管理和监控: 降低资源消耗(由线程池负责管理线程的生命周期,无任务执行时候会关闭线程)提高响应速度(线程池可以创建多个线程并发执行任务)提高线程的可管理性 java是如何实现管理线程池的?java管理线程池是体现在管理线程池的生命周期,java创建线程池的方式主要通过new一个线程池对象的方式创建线程池。比如通过Executors或者ThreadPoolExcutor等。关闭线程池一般是在发生异常或者任务结束以后执行的,通过线程池提供的方法完成,比如shutdown、shutwownNow。 ExecutorService executorService = Executors.newFixedThreadPool(4); ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 30, 60, TimeUnit.SECONDS, new LinkedBlockingQueue()); executor.shutdown(); executor.shutdownNow(); 为什么很多公司不允许使用Executors去创建线程池? 那么推荐怎么使用呢?三点不推荐使用的原因: Executors创建的线程池不合理,在Executors中FixedThreadPool和SingleThreadPool使用了无界队列不合理,宕线程池的线程数量达到上限后,任务会放入到无界队列中进行等待,会导致任务堆积,耗尽系统资源,导致系统崩溃。CachedThreadPool使用了一个无限大的线程池,当提交的任务过多时,会创建大量的线程,导致系统崩溃。在实际业务场景中线程池是需要根据实际的系统资源自定义的创建的,线程池的大小设置不当会导致系统性能下降。Executors创建的线程池无法进行监控和管理,可能会导致线程池中的人物无法正常执行,导致崩溃。推荐通过new一个线程池的方式创建一个自定义的线程池,比如new ThreadPoolExecutor()。 ThreadPoolExecutor有哪些核心的配置参数? 请简要说明ThreadPoolExecutor的核心配置参数主要有7个: 核心线程数; 最大线程数; 非核心线程在不执行任务的情况下的存活时间; 存活时间单位; 等待队列; 拒绝策略; 线程工厂; 在配置线程池的时候需要考虑哪些配置因素? 线程池的大小:根据系统的负载情况、系统的处理性能、处理请求的频率和资源利用率等因素来决定线程池的大小。线程池的最大值和最小值:线程池的最大值和最小值可以设置为固定值,或者根据系统的负载情况动态调整。线程池的任务队列:根据任务类型设置任务队列类型是有界队列还是无界队列。线程池的线程超时时间:为了合理的利用资源,也需要合理的设置线程的回收时间。线程池的拒绝策略:线程池的拒绝策略是指当任务数量超过线程池的最大值时,如何处理新的任务。常见的拒绝策略包括丢弃任务、抛出异常、阻塞等待和调用者运行等。 cpu密集型和IO密集型的任务在设置线程池有什么区别?区别主要有三点: 线程池的大小设置 对于cpu密集型的任务,cpu计算任务时间长,为了充分利用cpu资源,避免过多占用内存、也为了避免存在很多饥饿线程占用系统资源影响系统性能,往往设置成cpu核心数的两倍左右。对IO密集型的任务,耗费时间最长的是在IO操作的时间,在io操作期间会让出cpu执行其他的任务,所以对于IO密集型任务的线程池大小可以设置的更大一点但是也不能过大。在一般情况下都是设置成cpu核心数的2倍就可以了。 线程池等待队列的选择 对于CPU密集型任务,由于线程执行任务时占用CPU资源,因此需要使用有界队列,避免无限制地添加任务,导致内存溢出。而对于IO密集型任务,则需要使用无界队列,以避免任务因为线程池满而被拒绝,从而影响系统的性能。 线程超时时间 对于CPU密集型任务,由于线程一直在占用CPU资源,因此不需要设置线程超时时间。而对于IO密集型任务,如果某个线程等待IO操作的时间过长,可以通过设置线程超时时间来回收该线程,以便让其他线程处理任务。 如何监控线程池的状态?线程池提供了一系列状态方法可供开发人员监控线程池的状态,比如isShutdown()方法监控线程池是否关闭,getCompletedTaskCount用于监控线程池已经完成任务的数量,isRunning用于判断线程池是否该在运行。 ThreadPoolExecutor可以创建的是哪三种线程池呢?单例线程池、混合线程池和缓存线程池 public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue()); } public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()); } public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue())); } ThreadPoolExecutor源码解析 线程池执行任务实例 public class ThreadPoolTest { private static int i; private static ReentrantLock lock = new ReentrantLock(); public static void main(String[] args) throws InterruptedException, ExecutionException { ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 30, 60, TimeUnit.SECONDS, new LinkedBlockingQueue()); for (int i = 0; i < 10; i++) { Task task = new Task(); executor.submit(task); } Thread.sleep(2000); System.out.println(i); } static class Task implements Runnable{ @Override public void run() { lock.lock(); try{ for (int j = 0; j < 100000; j++) { i++; } System.out.println(Thread.currentThread().getName() +"\t" +i); }catch (Exception e){ e.printStackTrace(); }finally { lock.unlock(); } } } }运行结果: pool-1-thread-1 100000 pool-1-thread-2 200000 pool-1-thread-1 300000 pool-1-thread-2 400000 pool-1-thread-1 500000 pool-1-thread-2 600000 pool-1-thread-1 700000 pool-1-thread-2 800000 pool-1-thread-1 900000 pool-1-thread-2 1000000 1000000 ThreadPoolExecutor任务执行逻辑线程池的执行逻辑主要分为四步处理,具体如下
在调用submit方法后主要做了两件事: 1. 将任务封装成一个FutureTask(); 2.调用子类的execute()方法用于执行任务。 public Future submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture ftask = newTaskFor(task, null); execute(ftask); return ftask; }在execute()方法中根据线程池的状态选择核心线程执行任务、存放在等待队列、非核心线程执行任务、拒绝。 public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); //线程池中线程数量判断用核心线程执行任务 if (workerCountOf(c) < corePoolSize) { //执行任务 if (addWorker(command, true)) return; c = ctl.get(); } // 将任务添加到等待队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 线程池关闭或者没有添加队列成功执行拒绝策略 if (! isRunning(recheck) && remove(command)) reject(command); // 创建非核心线程的工作线程执行任务 else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 拒绝策略拒绝执行任务。 else if (!addWorker(command, false)) reject(command); }无论是核心线程执行任务还是非核心线程执行任务都是通过addWorker()方法完成的。 private boolean addWorker(Runnable firstTask, boolean core) { retry: for (int c = ctl.get();;) { // Check if queue empty only if necessary. //检查线程池的状态是否在运行状态; if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || firstTask != null || workQueue.isEmpty())) return false; //检查线程池中的线程数量和核心线程数以及最大线程数配置 for (;;) { if (workerCountOf(c) >= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateAtLeast(c, SHUTDOWN)) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { //创建一个工作线程用于执行任务; w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { //创建一个可重入锁实现对线程池中共享资源(工作线程队列workers)的管理 // 注意这是线程池中最重要的一把锁!!!! final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int c = ctl.get(); if (isRunning(c) || (runStateLessThan(c, STOP) && firstTask == null)) { if (t.getState() != Thread.State.NEW) throw new IllegalThreadStateException(); workers.add(w); workerAdded = true; int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; } } finally { mainLock.unlock(); } if (workerAdded) { //线程开始执行任务(worker) t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }创建工作线程的源码如下,在创建一个工作线程时候做了三件事: 设置worker的初始状态-1;在工作线程中记录任务通过线程工厂创建一个线程并把worker对象传入到创建的线程中。 private final class Worker extends AbstractQueuedSynchronizer implements Runnable { ... Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); }这里注意在调用start方法时候是worker中的线程执行的start,且是通过调用worker中的run方法运行的任务。 /** Delegates main run loop to outer runWorker. */ public void run() { runWorker(this); }在worker的run方法中又调用了runWorker方法执行任务。 runWorker方法中的主要做了四件事: 监控线程池的状态;获取任务;对worker对象进行加锁。(这里注意这是线程池中第二个加锁的地方)很巧妙的东西也体现在这里。执行任务完成后对工作线程队列的管理。 final void runWorker(Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null; w.unlock(); // allow interrupts boolean completedAbruptly = true; try { while (task != null || (task = getTask()) != null) { w.lock(); // If pool is stopping, ensure thread is interrupted; // if not, ensure thread is not interrupted. This // requires a recheck in second case to deal with // shutdownNow race while clearing interrupt if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); try { task.run(); afterExecute(task, null); } catch (Throwable ex) { afterExecute(task, ex); throw ex; } } finally { task = null; w.completedTasks++; w.unlock(); } } completedAbruptly = false; } finally { processWorkerExit(w, completedAbruptly); } } 线程池中的锁线程池中的锁共有两个:主锁(mainLock)和worker锁(w.lock) 在线程池中主锁是一个reentrantLock用于管理线程池中的共享变量的数据安全,包括工作线程队列、完成的任务数量、等待条件、线程池中的线程数量。保证在同一时刻只有一个线程可以对这些变量进行修改。 工作线程worker的锁是为了保证正在执行任务的工作线程不被中断。在线程池中在中断空闲线程时,先尝试获取锁再中断的原因是为了避免中断一个正在执行任务的线程。 private void interruptIdleWorkers(boolean onlyOne) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { for (Worker w : workers) { Thread t = w.thread; if (!t.isInterrupted() && w.tryLock()) { try { t.interrupt(); } catch (SecurityException ignore) { } finally { w.unlock(); } } if (onlyOne) break; } } finally { mainLock.unlock(); } final void runWorker(Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null; w.unlock(); // allow interrupts boolean completedAbruptly = true; try { while (task != null || (task = getTask()) != null) { w.lock(); // If pool is stopping, ensure thread is interrupted; // if not, ensure thread is not interrupted. This // requires a recheck in second case to deal with // shutdownNow race while clearing interrupt if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); try { task.run(); afterExecute(task, null); } catch (Throwable ex) { afterExecute(task, ex); throw ex; } } finally { task = null; w.completedTasks++; w.unlock(); } } completedAbruptly = false; } finally { processWorkerExit(w, completedAbruptly); } }在线程池中,每个工作线程通常都在执行任务或者等待新任务的到来,如果在线程还在执行任务时被中断,那么中断操作可能会中断正在执行的任务,导致任务执行不完整或者出现异常。因此,在中断空闲线程时,需要先尝试获取锁,以确保线程处于空闲状态并可以安全地中断。 因此,中断空闲线程时,先尝试获取锁再中断是为了确保线程处于空闲状态并可以安全地中断,避免中断正在执行任务的线程,从而保证线程池的稳定性和可靠性。 |
【本文地址】