| 数据特征分析方法总结 | 您所在的位置:网站首页 › ip的含义及特征分析论文 › 数据特征分析方法总结 |
数据特征分析方法总结
|
数据特征分析方法总结
21世纪是大数据的时代,因为这些大数据中蕴含着时代发展的信息。如何科学地分析数据特征是数据分析师必须掌握的基础技能之一。因此,我今天主要希望通过理论推导并实现一些常用的数据特征分析方法来加强对数据特征处理的能力。 分布分析分布分析:研究数据的分布特征和分布类型,分为定量数据和定性数据,并通过这两种类型来区分基本统计量。 常用指标为:极差、频率分布情况、分组组距及组数 # 读取数据 data = pd.read_csv('data/深圳罗湖二手房信息.csv', engine='python', encoding='gbk') plt.scatter(data['经度'], data['纬度'], s=data['房屋单价'] / 500, c=data['参考总价'], cmap='Reds', alpha=0.4) plt.grid() plt.show() data.head()通过散点图大致看一下数据分布情况,如图1所示:
对比分析就是用两组或两组以上的数据进行比较,是最通用的方法。我们知道孤立的数据、图像没有意义,有对比才有差异。比如在时间维度上的同比和环比、增长率、定基比,与竞争对手的对比、类别之间的对比、特征和属性对比等。对比法可以发现数据变化规律,使用频繁,经常和其他方法搭配使用。该方法一般会结合其他方法在后文呈现,这里不加赘述。 统计分析1、集中趋势度量:指一组数据向某一中心靠拢的倾向,核心在于寻找数据的代表值或者中心值————统计平均数 常用指标为: 算数平均数(均值)、位置平均数(中位数)、 众数 2、离中趋势量:指一组数据中各数据以不同程度的距离偏离中心的趋势。 常用指标为:极差、标准差 # 算数平均数 data = pd.DataFrame({'value': np.random.randint(100, 120, 100), 'f': np.random.rand(100)}) data['f'] = data['f'] / data['f'].sum() # f为权重,这里将f列设置成总和为1的权重占比 mean = (data['value']*data['f'].sum()/data) 帕累托分析帕累托分析(贡献度分析)即为我们常说的帕累托法则:20/80定律。“原因和结果、投入和产出、努力和报酬之间本来存在着无法解释的不平衡。一般来说,投入和努力可以分为两种不同的类型: 1、多数,它们只能造成少许的影响; 2、少数,它们造成主要的、重大的影响。” 比如说,一个公司80%利润来自于20%的畅销产品,而其他80%的产品只产生了20%的利润,通过二八原则,寻找关键的20%决定性因素! # 获取数据 data = pd.Series(np.random.randn(10) * 1200 + 3000, index=list('ABCDEFGHIJ')) # 排序 data.sort_values(ascending=False, inplace=True) # 画图 plt.figure(figsize=(10, 4)) fig = data.plot(kind='bar', color='g', alpha=0.8, width=0.6) p = data.cumsum() / data.sum() key = p[p > 0.8].index[0] key_num = data.index.tolist().index(key) # 找到累计占比超过80%时的index # 找到key所对应的索引位置 # 输出决定性因素产品 print('超过80%累计占比的节点值索引为: ', key) print('超过80%累计占比的节点值索引位置为: ', key_num) ## 图像表示 p.plot(style='--ko', secondary_y=True) plt.axvline(key_num, color='r', linestyle='--') plt.text(key_num + 0.2, p[key], '累计占比为:%.3f%%' % (p[key] * 100), color='r') plt.ylabel('营收比例') # 绘制营收累计占比曲线 key_product = data.loc[:key] print('核心产品为: ') print(key_product) plt.show()
正态性检验: 利用观测数据判断总体是否服从正态分布的检验称为正态性检验,它是统计判决中重要的一种特殊的拟合优度假设检验。 常用方法:直方图初判/QQ图判断/K-S检验 ## 方法1:直方图 data = pd.DataFrame(np.random.randn(1000)+10, columns=['value']) fig = plt.figure(figsize=(10, 6)) ax1 = fig.add_subplot(2, 1, 1) ax1.scatter(data.index, data.values) ax2 = fig.add_subplot(2, 1, 2) data.hist(bins=20, ax=ax2) data.plot(kind='kde', secondary_y=True, ax=ax2) plt.show()
|
 图1 颜色越深代表房价越高,经纬度可以确定深圳罗湖不同二手房的位置,从而表现出在不同位置二手房的房价。
图1 颜色越深代表房价越高,经纬度可以确定深圳罗湖不同二手房的位置,从而表现出在不同位置二手房的房价。 图2 计算结果如图所示。
图2 计算结果如图所示。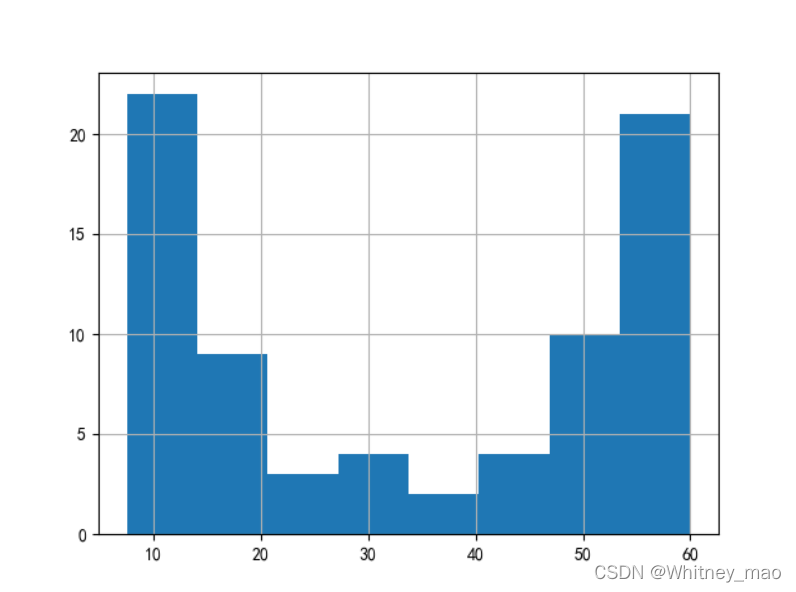 图3 通过直方图,我们可以看出不同区间二手房首付价格的大致分布情况。
图3 通过直方图,我们可以看出不同区间二手房首付价格的大致分布情况。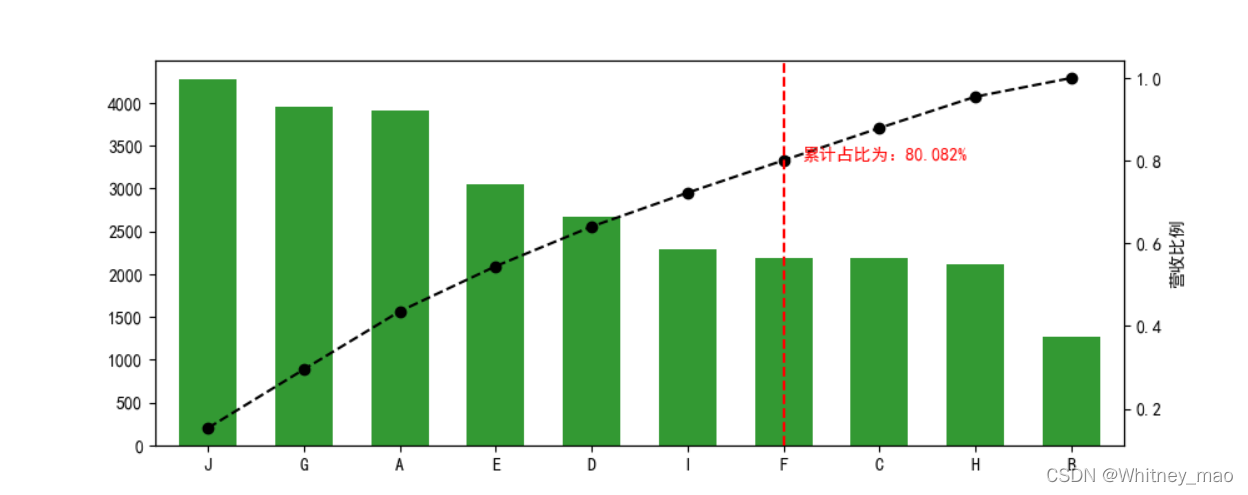 图4 即为帕累托可视化图像。J~F占所有种类的70%,贡献了80.082%的利润,企业应增加J-F的投入,减少C~B的投入以获得更高的盈利额。
图4 即为帕累托可视化图像。J~F占所有种类的70%,贡献了80.082%的利润,企业应增加J-F的投入,减少C~B的投入以获得更高的盈利额。 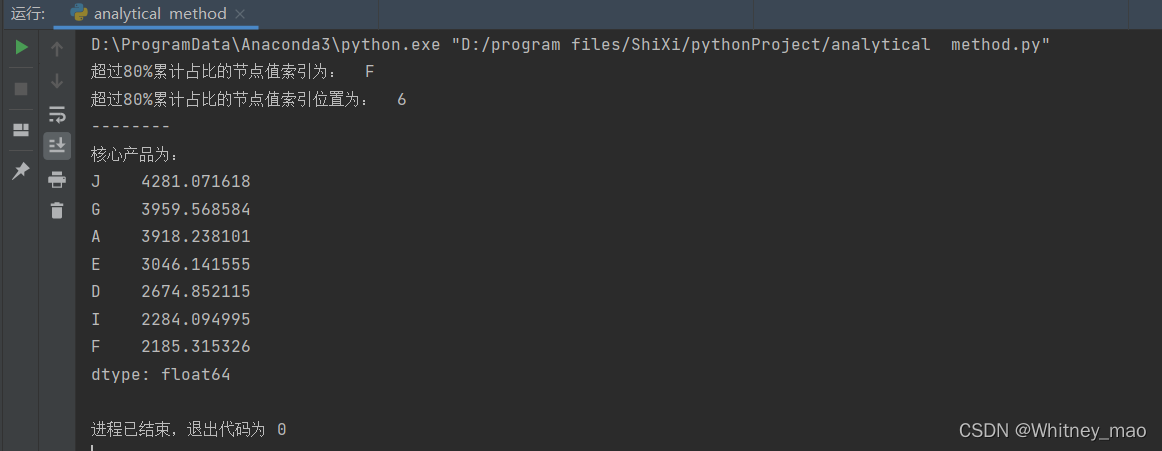 图5 运行结果,通过结合图像可以很快地找到超过80%累计占比的节点以及对应的节点值。
图5 运行结果,通过结合图像可以很快地找到超过80%累计占比的节点以及对应的节点值。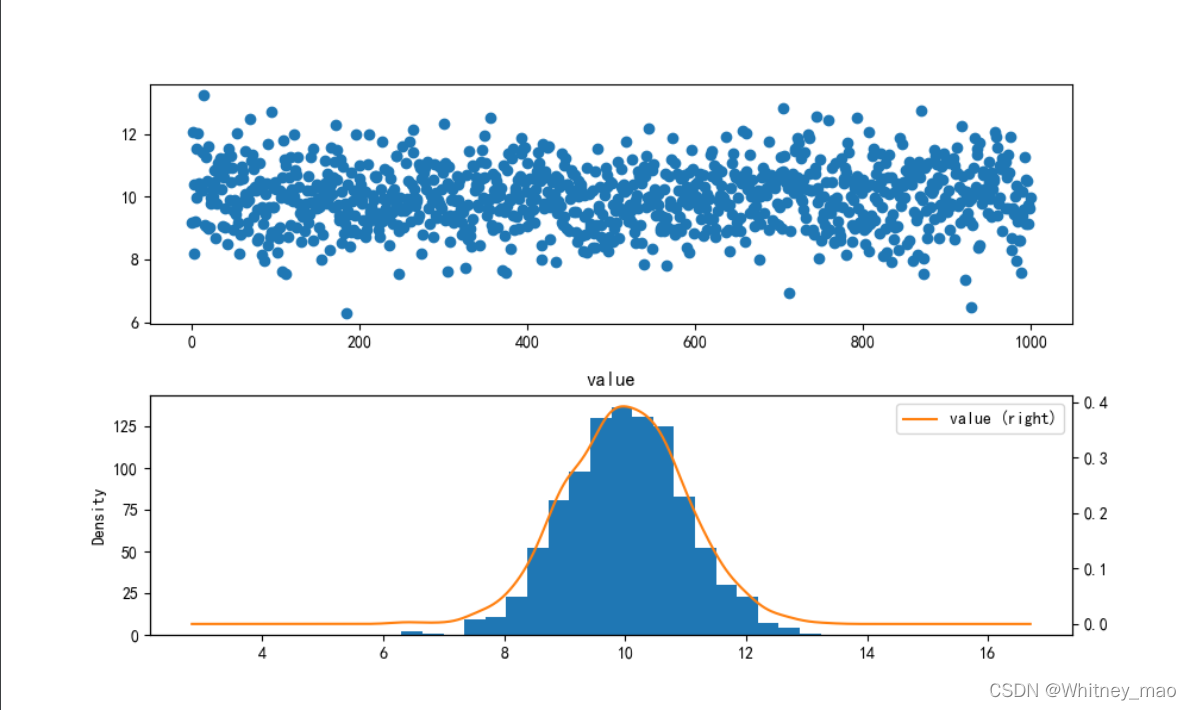 图6 第2个子图即为直方图。利用散点图和直方图,我们可以清晰地看出该组数据满足正态分布。
图6 第2个子图即为直方图。利用散点图和直方图,我们可以清晰地看出该组数据满足正态分布。【本文地址】