| 【数据分析实例】1 亿条淘宝用户行为Hive数据分析 | 您所在的位置:网站首页 › hive数仓项目代码实例 › 【数据分析实例】1 亿条淘宝用户行为Hive数据分析 |
【数据分析实例】1 亿条淘宝用户行为Hive数据分析
|
文章目录
1. 数据集说明2. 数据处理2.1 数据导入2.2 数据清洗
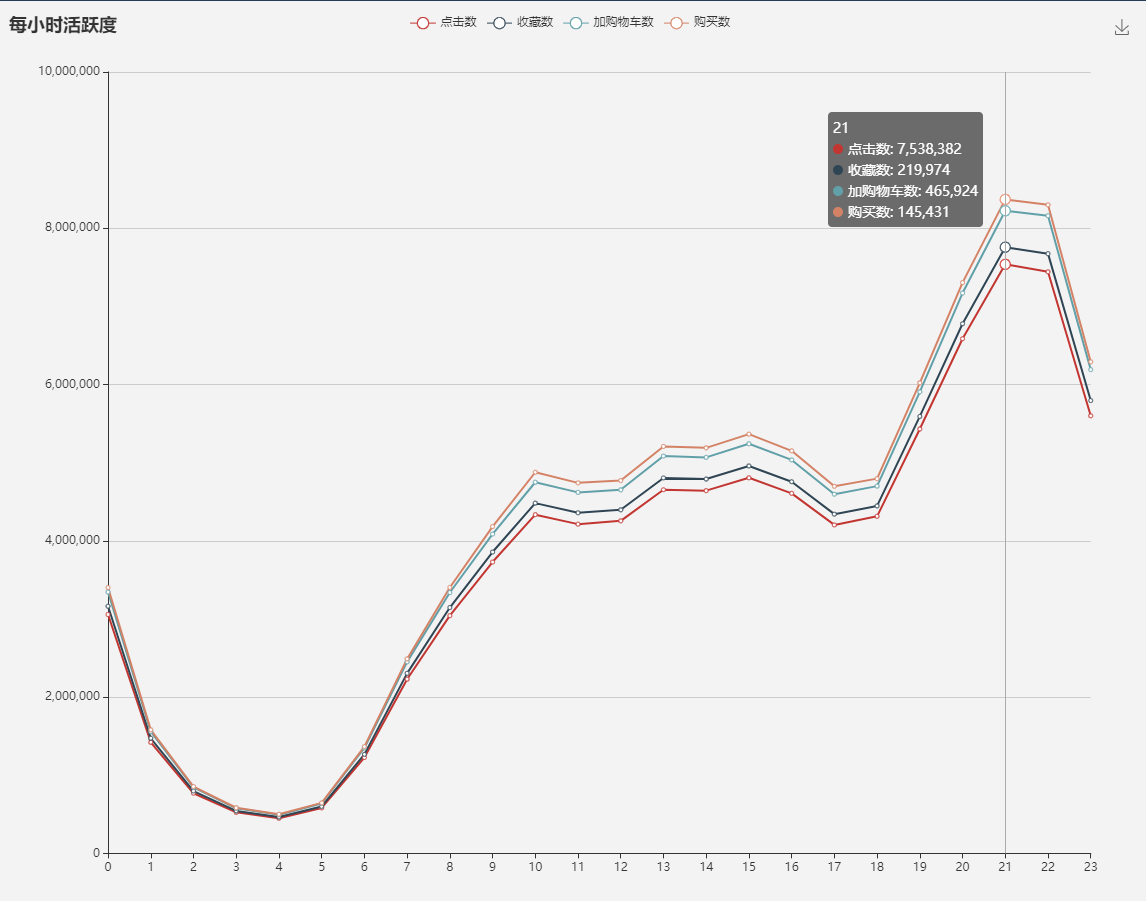
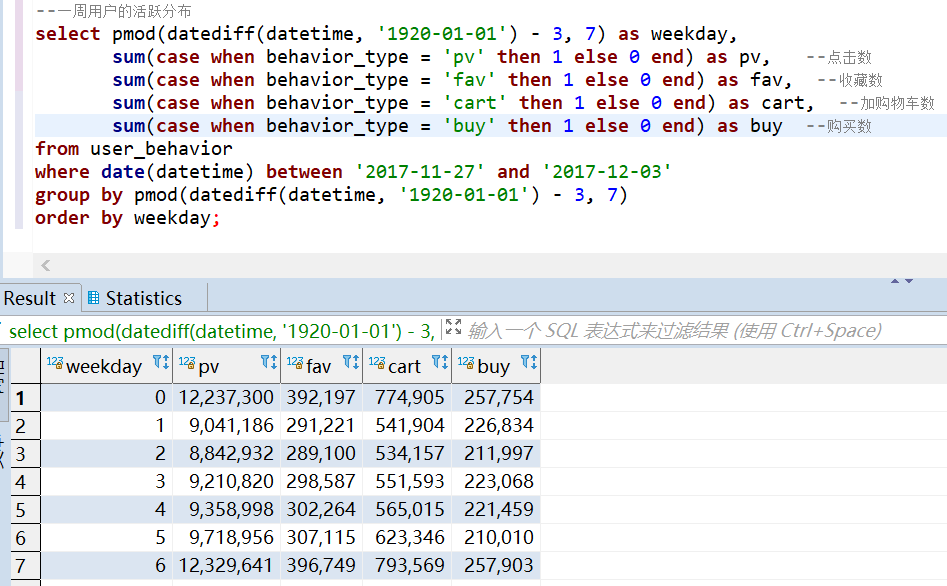
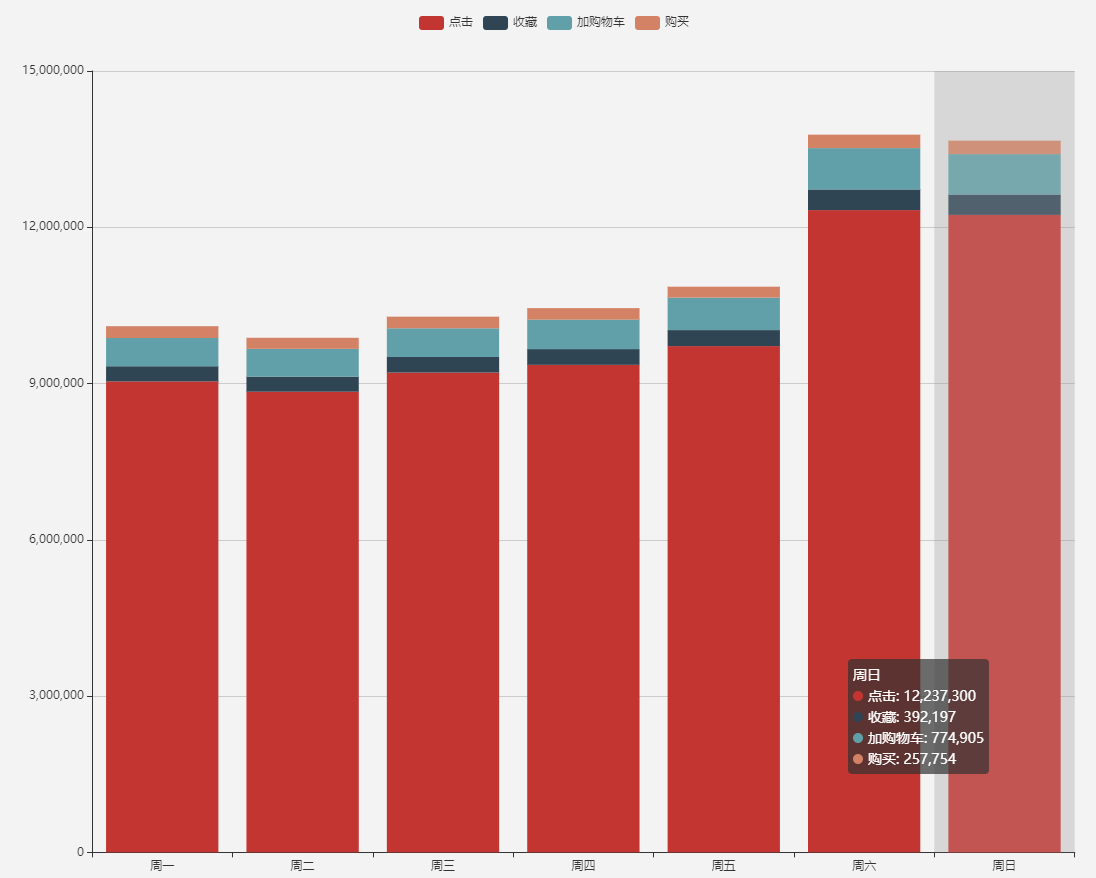
3.数据分析可视化3.1 用户流量及购物情况3.2 用户行为转换率3.3 用户行为习惯3.4 基于 RFM 模型找出有价值的用户3.5 商品维度的分析
4、数据下载
1. 数据集说明
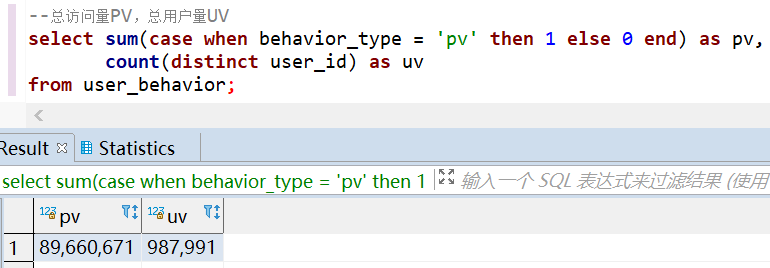
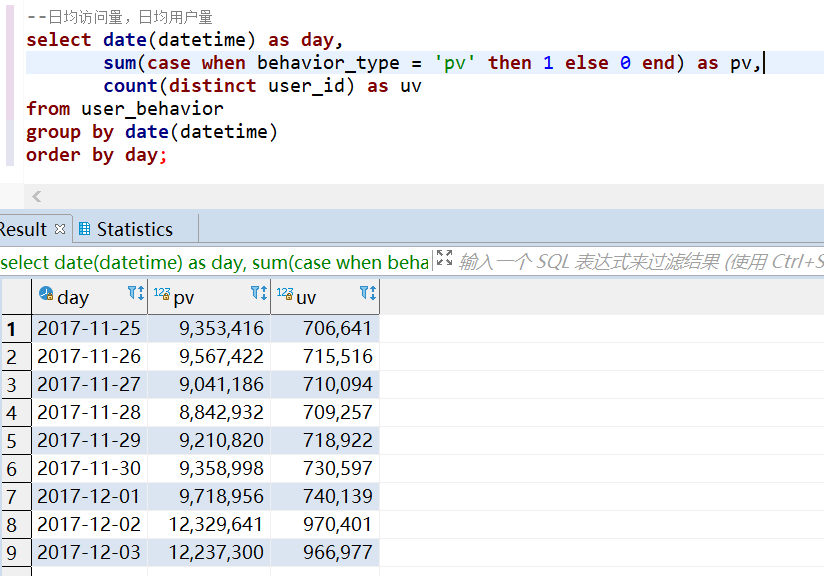
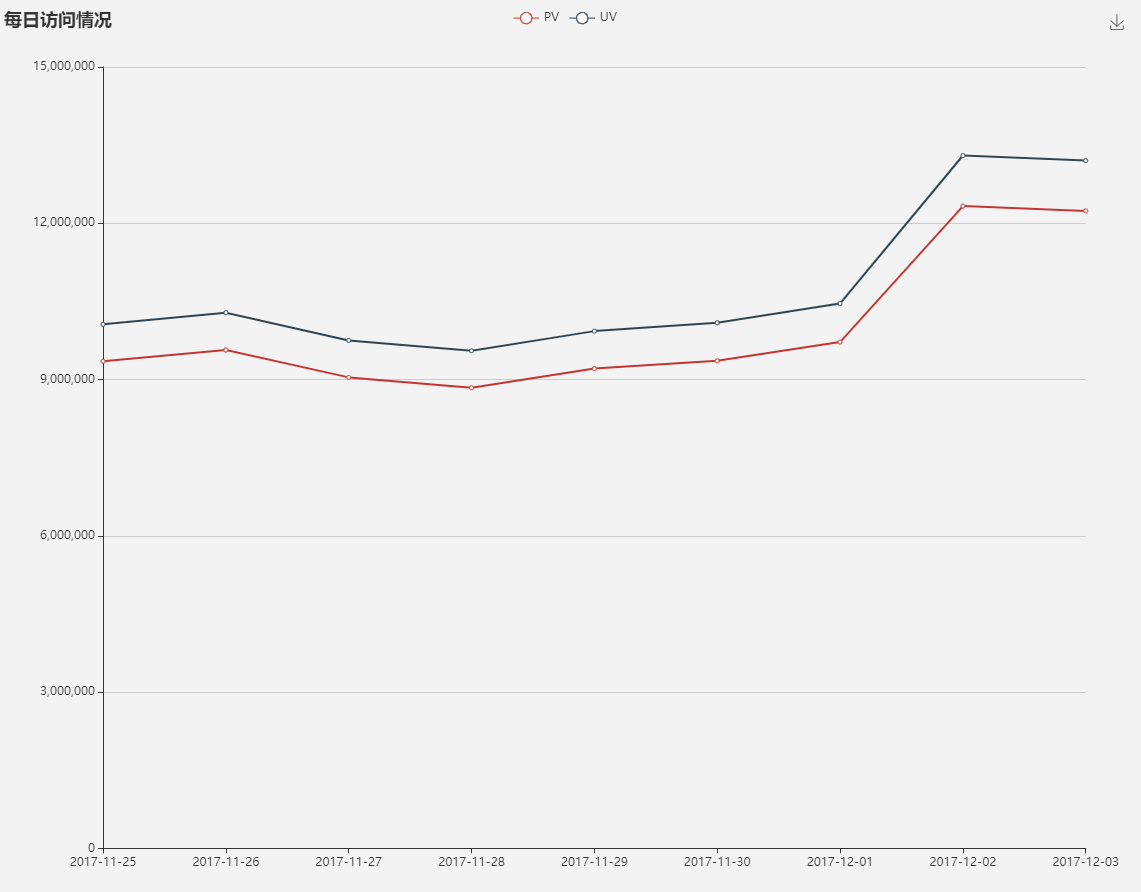
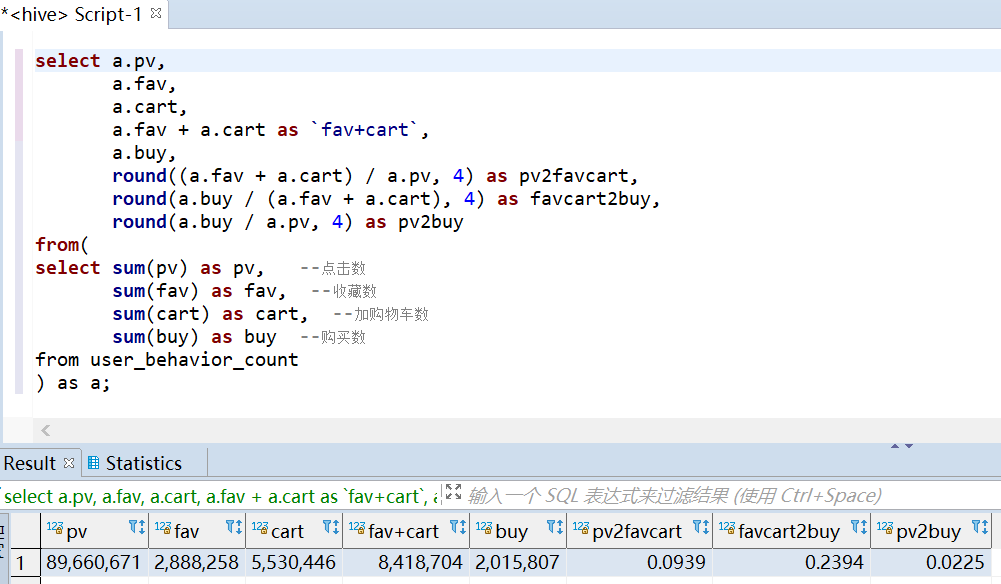
这是一份来自淘宝的用户行为数据,时间区间为 2017-11-25 到 2017-12-03,总计 100,150,807 条记录,大小为 3.5 G,包含 5 个字段。 知识点:清洗 hive + 分析 hive + 可视化 echarts 2. 数据处理 2.1 数据导入将数据加载到 hive, 然后通过 hive 对数据进行数据处理。 -- 建表 drop table if exists user_behavior; create table user_behavior ( `user_id` string comment '用户ID', `item_id` string comment '商品ID', `category_id` string comment '商品类目ID', `behavior_type` string comment '行为类型,枚举类型,包括(pv, buy, cart, fav)', `timestamp` int comment '行为时间戳', `datetime` string comment '行为时间') row format delimited fields terminated by ',' lines terminated by '\n'; -- 加载数据 LOAD DATA LOCAL INPATH '/home/getway/UserBehavior.csv' OVERWRITE INTO TABLE user_behavior ; 2.2 数据清洗数据处理主要包括:删除重复值,时间戳格式化,删除异常值。 --数据清洗,去掉完全重复的数据 insert overwrite table user_behavior select user_id, item_id, category_id, behavior_type, timestamp, datetime from user_behavior group by user_id, item_id, category_id, behavior_type, timestamp, datetime; --数据清洗,时间戳格式化成 datetime insert overwrite table user_behavior select user_id, item_id, category_id, behavior_type, timestamp, from_unixtime(timestamp, 'yyyy-MM-dd HH:mm:ss') from user_behavior; --查看时间是否有异常值 select date(datetime) as day from user_behavior group by date(datetime) order by day; --数据清洗,去掉时间异常的数据 insert overwrite table user_behavior select user_id, item_id, category_id, behavior_type, timestamp, datetime from user_behavior where cast(datetime as date) between '2017-11-25' and '2017-12-03'; --查看 behavior_type 是否有异常值 select behavior_type from user_behavior group by behavior_type; 3.数据分析可视化 3.1 用户流量及购物情况 --总访问量PV,总用户量UV select sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, count(distinct user_id) as uv from user_behavior;
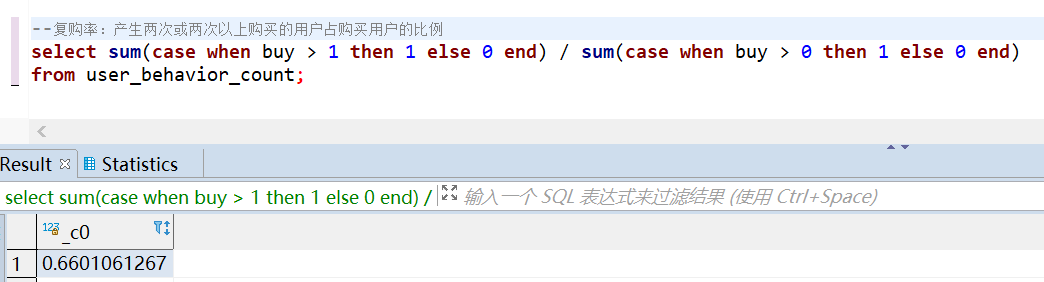
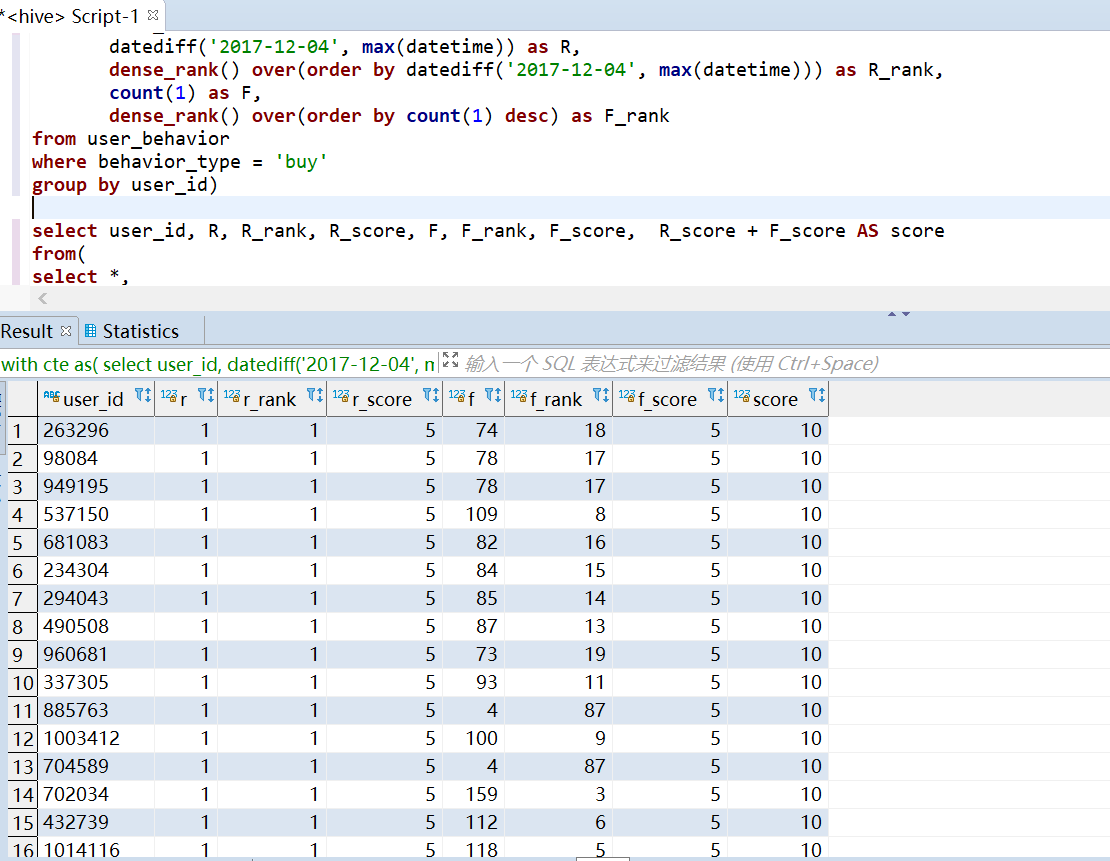
RFM 模型是衡量客户价值和客户创利能力的重要工具和手段,其中由3个要素构成了数据分析最好的指标,分别是: R-Recency(最近一次购买时间)F-Frequency(消费频率)M-Money(消费金额) --R-Recency(最近一次购买时间), R值越高,一般说明用户比较活跃 select user_id, datediff('2017-12-04', max(datetime)) as R, dense_rank() over(order by datediff('2017-12-04', max(datetime))) as R_rank from user_behavior where behavior_type = 'buy' group by user_id limit 10; --F-Frequency(消费频率), F值越高,说明用户越忠诚 select user_id, count(1) as F, dense_rank() over(order by count(1) desc) as F_rank from user_behavior where behavior_type = 'buy' group by user_id limit 10; --M-Money(消费金额),数据集无金额,所以就不分析这一项对有购买行为的用户按照排名进行分组,共划分为5组, 前 - 1/5 的用户打5分 前 1/5 - 2/5 的用户打4分 前 2/5 - 3/5 的用户打3分 前 3/5 - 4/5 的用户打2分 前 4/5 - 的用户打1分 按照这个规则分别对用户时间间隔排名打分和购买频率排名打分,最后把两个分数合并在一起作为该名用户的最终评分 with cte as( select user_id, datediff('2017-12-04', max(datetime)) as R, dense_rank() over(order by datediff('2017-12-04', max(datetime))) as R_rank, count(1) as F, dense_rank() over(order by count(1) desc) as F_rank from user_behavior where behavior_type = 'buy' group by user_id) select user_id, R, R_rank, R_score, F, F_rank, F_score, R_score + F_score AS score from( select *, case ntile(5) over(order by R_rank) when 1 then 5 when 2 then 4 when 3 then 3 when 4 then 2 when 5 then 1 end as R_score, case ntile(5) over(order by F_rank) when 1 then 5 when 2 then 4 when 3 then 3 when 4 then 2 when 5 then 1 end as F_score from cte ) as a order by score desc limit 20;
https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1 代码只使用HSQ部分 |

【本文地址】
公司简介
联系我们