| MD5密码实验 | 您所在的位置:网站首页 › hash算法含python实现 › MD5密码实验 |
MD5密码实验
|
文章目录
更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理
实验结果实验心得实验代码MD5-Python.py
更新:
感谢评论区的两位大佬指出错误,特此感谢,现已改进代码 1.第一次修改 之前的错误在于没有考虑最高位是0的情况 造成某些字符串的MD5加密结果与实际不符 所以对代码作出如下部分修改 原先代码 现在代码 代码中的group_processing方法只处理了第一个分组,而没有进行迭代处理。 MD5算法是迭代型杂凑函数,每个分组的处理结果会影响下一个分组的计算。在代码中,init_A、init_B、init_C、init_D是初始的寄存器值,应该在处理每个分组之前更新为上一个分组处理后的结果。但是在代码中,这些初始值没有被更新,导致处理后续分组时出错。 要修复这个问题,可以在group_processing方法中添加适当的代码来更新init_A、init_B、init_C、init_D,以便迭代处理每个分组。 具体做法是,在每次迭代结束后将当前的A、B、C、D值赋给init_A、init_B、init_C、init_D,以便下一个分组使用。 原先的代码 def group_processing(self): M = [] for i in range(0, 512, 32): num = "" # 获取每一段的标准十六进制形式 for j in range(0, len(self.ciphertext[i:i+32]), 4): temp = self.ciphertext[i:i+32][j:j + 4] temp = hex(int(temp, 2)) num += temp[2] # 对十六进制进行小端排序 num_tmp = "" for j in range(8, 0, -2): temp = num[j-2:j] num_tmp += temp num = "" for i in range(len(num_tmp)): num += int2bin(int(num_tmp[i], 16), 4) M.append(num)修改之后 def group_processing(self): M = [] for i in range(0, len(self.ciphertext), 512): # 获取当前分组 current_group = self.ciphertext[i:i+512] # 处理当前分组... # ... # 更新 init_A、init_B、init_C、init_D self.init_A = self.A self.init_B = self.B self.init_C = self.C self.init_D = self.D for j in range(0, 512, 32): num = "" # 获取每一段的标准十六进制形式 for k in range(0, len(current_group[j:j+32]), 4): temp = current_group[j:j+32][k:k+4] temp = hex(int(temp, 2)) num += temp[2] # 对十六进制进行小端排序 num_tmp = "" for k in range(8, 0, -2): temp = num[k-2:k] num_tmp += temp num = "" for k in range(len(num_tmp)): num += int2bin(int(num_tmp[k], 16), 4) M.append(num) 前言实验目的 1)初步了解哈希算法 2)掌握哈希算法MD5的实现 提示:以下是本篇文章正文内容,下面案例可供参考 实验环境计算机语言:Python 开发环境:Pycharm 实验内容编程实现MD5算法。 实验操作步骤编写MD5类
1.明文:12345678 密文:25d55ad23a80aa4f464c76d713c07ad 2.明文:hello world 密文:5eb63bbbe01eeed093cb22bb8f5acdc3 本次实验是MD5算法的编写,通过本次python代码编写实现了加密功能,编写的思路从MD5算法原理出发,通过初始化缓冲区、附加填充位、分组进行加密等步骤,构造类来实现功能,相较于RSA,MD5是不可逆算法,应该会更加安全一些,但我查阅资料后发现并非如此,在线的MD5库可以解密数量巨大的MD5密文,只有在“加盐”过后才会使得破解难度大大增加。 实验代码 MD5-Python.py # -*- codeding = uft-8 -*- def int2bin(n, count=24): return "".join([str((n >> y) & 1) for y in range(count-1, -1, -1)]) class MD5(object): # 初始化密文 def __init__(self, message): self.message = message self.ciphertext = "" self.A = 0x67452301 self.B = 0xEFCDAB89 self.C = 0x98BADCFE self.D = 0x10325476 self.init_A = 0x67452301 self.init_B = 0xEFCDAB89 self.init_C = 0x98BADCFE self.init_D = 0x10325476 ''' self.A = 0x01234567 self.B = 0x89ABCDEF self.C = 0xFEDCBA98 self.D = 0x76543210 ''' #设置常数表T self.T = [0xD76AA478,0xE8C7B756,0x242070DB,0xC1BDCEEE,0xF57C0FAF,0x4787C62A,0xA8304613,0xFD469501, 0x698098D8,0x8B44F7AF,0xFFFF5BB1,0x895CD7BE,0x6B901122,0xFD987193,0xA679438E,0x49B40821, 0xF61E2562,0xC040B340,0x265E5A51,0xE9B6C7AA,0xD62F105D,0x02441453,0xD8A1E681,0xE7D3FBC8, 0x21E1CDE6,0xC33707D6,0xF4D50D87,0x455A14ED,0xA9E3E905,0xFCEFA3F8,0x676F02D9,0x8D2A4C8A, 0xFFFA3942,0x8771F681,0x6D9D6122,0xFDE5380C,0xA4BEEA44,0x4BDECFA9,0xF6BB4B60,0xBEBFBC70, 0x289B7EC6,0xEAA127FA,0xD4EF3085,0x04881D05,0xD9D4D039,0xE6DB99E5,0x1FA27CF8,0xC4AC5665, 0xF4292244,0x432AFF97,0xAB9423A7,0xFC93A039,0x655B59C3,0x8F0CCC92,0xFFEFF47D,0x85845DD1, 0x6FA87E4F,0xFE2CE6E0,0xA3014314,0x4E0811A1,0xF7537E82,0xBD3AF235,0x2AD7D2BB,0xEB86D391] #循环左移位数 self.s = [7,12,17,22,7,12,17,22,7,12,17,22,7,12,17,22, 5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20, 4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23, 6,10,15,21,6,10,15,21,6,10,15,21,6,10,15,21] self.m = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, 1,6,11,0,5,10,15,4,9,14,3,8,13,2,7,12, 5,8,11,14,1,4,7,10,13,0,3,6,9,12,15,2, 0,7,14,5,12,3,10,1,8,15,6,13,4,11,2,9] # 附加填充位 def fill_text(self): for i in range(len(self.message)): c = int2bin(ord(self.message[i]), 8) self.ciphertext += c if (len(self.ciphertext)%512 != 448): if ((len(self.ciphertext)+1)%512 != 448): self.ciphertext += '1' while (len(self.ciphertext)%512 != 448): self.ciphertext += '0' length = len(self.message)*8 if (length |



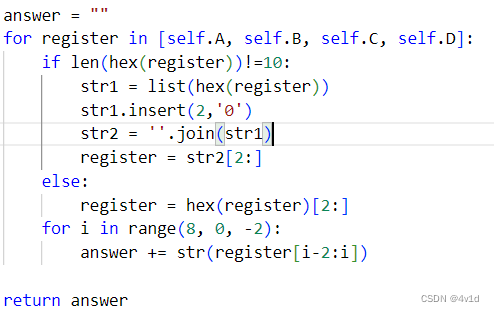 2.第二次修改
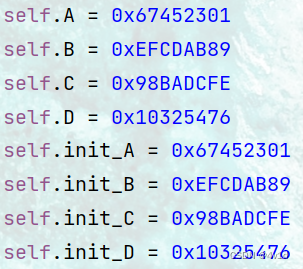
2.第二次修改 初始化配置各参数
初始化配置各参数






 分为四个分组,FF,GG,HH,II 每组对消息message的不同单位进行加密
分为四个分组,FF,GG,HH,II 每组对消息message的不同单位进行加密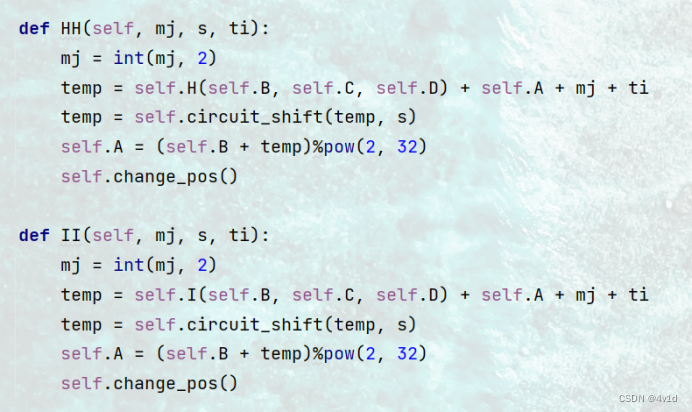
 分组处理,每次循环移动四位
分组处理,每次循环移动四位 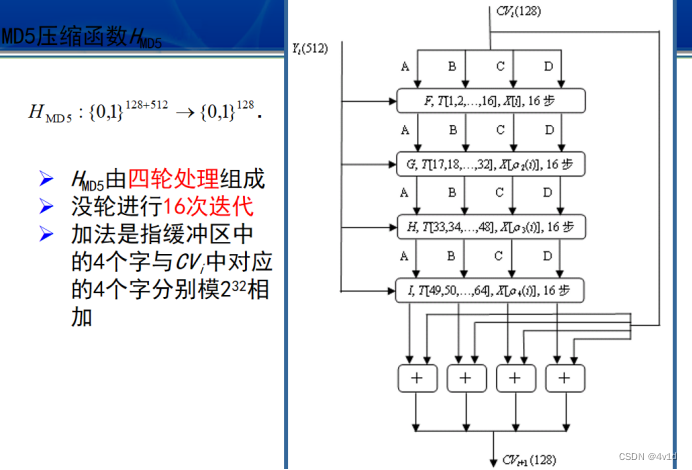





 与在线加密结果一致
与在线加密结果一致 
 与在线加密结果一致
与在线加密结果一致 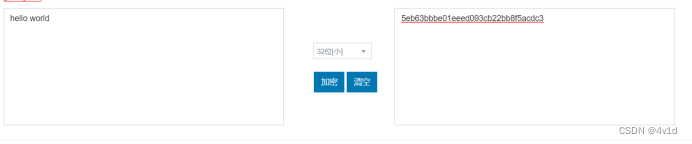
【本文地址】