| 基于CentOS虚拟机的Hadoop安装教程(自用备忘) | 您所在的位置:网站首页 › hadoop部署在物理机还是虚拟机里面 › 基于CentOS虚拟机的Hadoop安装教程(自用备忘) |
基于CentOS虚拟机的Hadoop安装教程(自用备忘)
|
该博文是用于记录Hadoop的安装过程,且记录其中出现的一些问题,防止日后遗忘 实验环境: 虚拟机:CentOS7 Hadoop:3.3.2 java:java 8u331下载连接: CentOS:centos-7-x86_64-dvd-2009.iso 如果不能下载请到这里找可以下载的镜像网站:镜像 JDK:jdk-8u331-linux-x64.rpm Hadoop:Hadoop-3.3.2 CentOS安装使用VMware构造虚拟机 新建虚拟机 选择 经典(推荐) 至此虚拟机已经安装完毕 JDK配置因为该虚拟机在构造的时候预先给我们配置好了java环境,但我们首先需要把他全部卸载掉,然后再安装我们的JDK 1.删除已有的jdk安装包 检测虚拟机上jdk安装包:rpm -qa | grep java 2.安装jdk 这里使用的是 jdk-8u331-linux-x64.rpm进行安装,可根据自己需求自行选择压缩包或其他方式安装 把rpm文件拖入虚拟机,使用 rpm -ivh jdk-8u331-linux-x64.rpm 命令进行安装 把下载好的hadoop压缩包拖进虚拟机 使用 tar -zxvf hadoop-3.3.2.tar.gz解压缩 然后移动到 /opt 目录下 mv ./hadoop-3.3.2 /opt/ 也可以在解压缩的时候指定目录 tar -zxvf hadoop-3.3.2.tar.gz -C /opt 移动到hadoop的配置目录 cd /opt/hadoop-3.3.2/etc/hadoop/ 修改配置文件hadoop-env.sh JAVA_HOME=/usr/java/jdk1.8.0_331-amd64 路径为jdk路径core-site.xml 在中添加 hadoop.tmp.dir/opt/hadoop-3.3.2/hadoopdata fs.defaultFShdfs://cMaster:8020hdfs-site.xml dfs.namenode.name.dir /opt/hadoop-3.3.2/hadoopdata/name dfs.datanode.data.dir /opt/hadoop-3.3.2/hadoopdata/data dfs.replication 1 dfs.secondary.http.address cSlave0:50090 dfs.http.address0.0.0.0:50070yarn-site.xml yarn.resourcemanager.hostnamecMaster yarn.nodemanager.aux-servicesmapreduce_shuffle yarn.application.classpath/opt/hadoop-3.3.2/etc/hadoop:/opt/hadoop-3.3.2/share/hadoop/common/lib/*:/opt/hadoop-3.3.2/share/hadoop/common/*:/opt/hadoop-3.3.2/share/hadoop/hdfs:/opt/hadoop-3.3.2/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.2/share/hadoop/hdfs/*:/opt/hadoop-3.3.2/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.3.2/share/hadoop/mapreduce/*:/opt/hadoop-3.3.2/share/hadoop/yarn:/opt/hadoop-3.3.2/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.2/share/hadoop/yarn/* yarn.nodemanager.vmem-check-enabledfalsemapred-site.xml mapreduce.framwork.nameyarnworkers 添加三个结点的主机名 cMaster cSlave0 cSlave1 设置环境变量 vim /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_331-amd64 export HADOOP_HOME=/opt/hadoop-3.3.2 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH PATH=$PATH:$HOME/bin export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root source /etc/profile重启后使用hadoop看一下是否成功设置 出现这条信息代表初始化成功 启动hadoop start-dfs.sh但直接启动会报错,因为没有设置三台主机的免密登录 ssh配置文件设置 //ssh配置 vim /etc/ssh/sshd_config //添加 PermitRootLogin yes UsePAM no PasswordAuthentication no RSAAuthentication yes //修改 PubkeyAuthentication yes在root用户下生成公钥和私钥 ssh-keygen
然后再次启动就可以了 访问localhost:50070,如果出现active代表启动成功 访问主节点的8088端口,如果出现该页面代表配置成功 一些踩过的坑: 1.在初始化的时候,无法访问主类 Could not find or load main class org.apache.hadoop… 这是因为在一开始使用了原本系统有的jdk,但具体路径不知道,所以出现错误,后来自己下载jdk解决 2.访问被拒绝 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password). 在启动的时候会弹出这个错误,因为没有设置免密登录,所以无法访问其他两个结点 如果有其他问题可以参考一下这几篇博文: https://blog.csdn.net/newbrid007/article/details/114398905 https://blog.csdn.net/qq_45981158/article/details/117434353 |
 填写全名,用户名和密码
填写全名,用户名和密码  注:用户名只能全小写,且root用户和该用户密码一致 下一步,下一步 在自定义硬件这里,需要小修改一下 处理器该栏取消勾选
注:用户名只能全小写,且root用户和该用户密码一致 下一步,下一步 在自定义硬件这里,需要小修改一下 处理器该栏取消勾选  然后耐心等待虚拟机构建好
然后耐心等待虚拟机构建好 
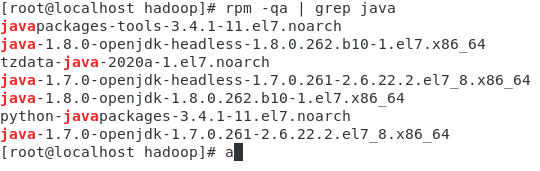 使用:rpm -e --nodeps 包名 删除jdk安装包直到所有jdk安装包都不存在为止 最后再次使用 rpm -qa | grep java 命令查看是否为空
使用:rpm -e --nodeps 包名 删除jdk安装包直到所有jdk安装包都不存在为止 最后再次使用 rpm -qa | grep java 命令查看是否为空 安装完毕,java路径为 /usr/java/jdk1.8.0_331-amd64 PS:如果遇到这种安装失败情况,请重新下载一次rpm文件试试看,我这边在拖进虚拟机一次之后就不能再拖进一个新的虚拟机里面,新下的拖进去会弹窗报错,按一下retry就好
安装完毕,java路径为 /usr/java/jdk1.8.0_331-amd64 PS:如果遇到这种安装失败情况,请重新下载一次rpm文件试试看,我这边在拖进虚拟机一次之后就不能再拖进一个新的虚拟机里面,新下的拖进去会弹窗报错,按一下retry就好 
 能够看到使用帮助的话为设定成功 初始化
能够看到使用帮助的话为设定成功 初始化

 可以看到有三个文件
可以看到有三个文件  公钥:id_rsa.pub 私钥:id_rsa 生成保存其他主机公钥的文件touch ~/.ssh/authorized_keys 把三个主机的公钥信息都保存到authorized_keys文件中 使用cat ~/.ssh/id_rsa.pub 获取公钥信息,当然用vim也可以
公钥:id_rsa.pub 私钥:id_rsa 生成保存其他主机公钥的文件touch ~/.ssh/authorized_keys 把三个主机的公钥信息都保存到authorized_keys文件中 使用cat ~/.ssh/id_rsa.pub 获取公钥信息,当然用vim也可以 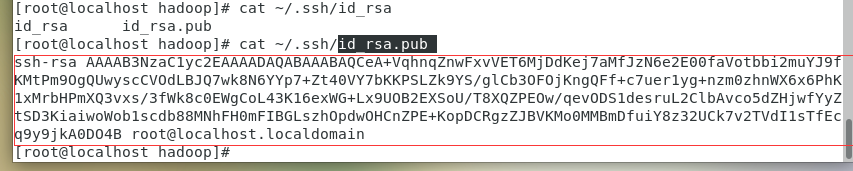 把三台主机都配置好 配置好了之后可以直接使用ssh cSlave0访问,如果不需要密码就能ssh登录的话代表成功 注:这里把三台主机的公钥都添加进去,因为前面xml设置的时候把自己主机的结点也添加进去了,所以会访问自己,不然也会无法访问 注注:如果有自己想法可以按自己需求来,这里只是其中一个解决思路 参考:https://blog.csdn.net/qq_36657997/article/details/107691144
把三台主机都配置好 配置好了之后可以直接使用ssh cSlave0访问,如果不需要密码就能ssh登录的话代表成功 注:这里把三台主机的公钥都添加进去,因为前面xml设置的时候把自己主机的结点也添加进去了,所以会访问自己,不然也会无法访问 注注:如果有自己想法可以按自己需求来,这里只是其中一个解决思路 参考:https://blog.csdn.net/qq_36657997/article/details/107691144 启动存储服务
启动存储服务
【本文地址】