| 最详细的Catboost参数详解与实例应用 | 您所在的位置:网站首页 › h3cminis1216pwr参数 › 最详细的Catboost参数详解与实例应用 |
最详细的Catboost参数详解与实例应用
|
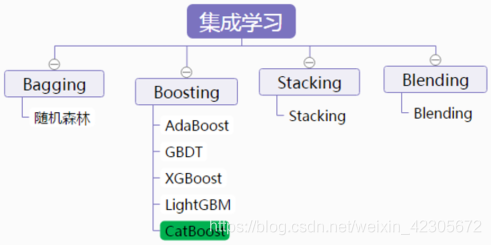
集成学习的两大准则:基学习器的准确性和多样性。 算法:串行的Boosting和并行的Bagging,前者通过错判训练样本重新赋权来重复训练,来提高基学习器的准确性,降低偏差!后者通过采样方法,训练出多样性的基学习器,降低方差。 文章目录 1.CatBoost简介1.1CatBoost介绍1.2CatBoost优缺点1.3CatBoost安装 2.参数详解2.1通用参数:2.2默认参数2.3性能参数2.4参数调优 3.CatBoost实战应用3.1回归案例3.2使用Pool加载数据集并进行预测3.3多分类案例 4.总结 1.CatBoost简介 1.1CatBoost介绍CatBoost这个名字来自两个词“Category”和“Boosting”。如前所述,该库可以很好地处理各种类别型数据,是一种能够很好地处理类别型特征的梯度提升算法库。 CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。XGBoost被广泛的应用于工业界,LightGBM有效的提升了GBDT的计算效率,而Yandex的CatBoost号称是比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。 CatBoost的主要算法原理可以参照以下两篇论文: Anna Veronika Dorogush, Andrey Gulin, Gleb Gusev, Nikita Kazeev, Liudmila Ostroumova Prokhorenkova, Aleksandr Vorobev “Fighting biases with dynamic boosting”. arXiv:1706.09516, 2017Anna Veronika Dorogush, Vasily Ershov, Andrey Gulin “CatBoost: gradient boosting with categorical features support”. Workshop on ML Systems at NIPS 2017 1.2CatBoost优缺点 性能卓越:在性能方面可以匹敌任何先进的机器学习算法鲁棒性/强健性:它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性易于使用:提供与scikit集成的Python接口,以及R和命令行界面实用:可以处理类别型、数值型特征可扩展:支持自定义损失函数支持类别型变量,无需对非数值型特征进行预处理快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行快速预测,即便应对延时非常苛刻的任务也能够快速高效部署模型CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,这一点从它的名字中可以看出来,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。 与XGBoost、LightGBM相比,CatBoost的创新点有: 嵌入了自动将类别型特征处理为数值型特征的创新算法。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。Catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。采用排序提升的方法对抗训练集中的噪声点,从而避免梯度估计的偏差,进而解决预测偏移的问题。采用了完全对称树作为基模型。 1.3CatBoost安装用pip pip install catboost 或者用conda conda install -c conda-forge catboost 速度极慢,直到下载失败 安装jupyter notebook中的交互组件,用于交互绘图 pip install ipywidgets jupyter nbextension enable --py widgetsnbextension 可以使用清华镜像安装: pip install catboost -i https://pypi.tuna.tsinghua.edu.cn/simple 下载速度嗖嗖的,完成了。 2.参数详解参考官网:https://catboost.ai/ 2.1通用参数: loss_function 损失函数,支持的有RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE,Poisson。默认RMSE。custom_metric 训练过程中输出的度量值。这些功能未经优化,仅出于信息目的显示。默认None。eval_metric 用于过拟合检验(设置True)和最佳模型选择(设置True)的loss function,用于优化。iterations 最大树数。默认1000。learning_rate 学习率。默认0.03。random_seed 训练时候的随机种子l2_leaf_reg L2正则参数。默认3bootstrap_type 定义权重计算逻辑,可选参数:Poisson (supported for GPU only)/Bayesian/Bernoulli/No,默认为Bayesianbagging_temperature 贝叶斯套袋控制强度,区间[0, 1]。默认1。subsample 设置样本率,当bootstrap_type为Poisson或Bernoulli时使用,默认66sampling_frequency设置创建树时的采样频率,可选值PerTree/PerTreeLevel,默认为PerTreeLevelrandom_strength 分数标准差乘数。默认1。use_best_model 设置此参数时,需要提供测试数据,树的个数通过训练参数和优化loss function获得。默认False。best_model_min_trees 最佳模型应该具有的树的最小数目。depth 树深,最大16,建议在1到10之间。默认6。ignored_features 忽略数据集中的某些特征。默认None。one_hot_max_size 如果feature包含的不同值的数目超过了指定值,将feature转化为float。默认Falsehas_time 在将categorical features转化为numerical features和选择树结构时,顺序选择输入数据。默认False(随机)rsm 随机子空间(Random subspace method)。默认1。nan_mode处理输入数据中缺失值的方法,包括Forbidden(禁止存在缺失),Min(用最小值补),Max(用最大值补)。默认Min。fold_permutation_block_size数据集中的对象在随机排列之前按块分组。此参数定义块的大小。值越小,训练越慢。较大的值可能导致质量下降。leaf_estimation_method 计算叶子值的方法,Newton/ Gradient。默认Gradient。leaf_estimation_iterations 计算叶子值时梯度步数。leaf_estimation_backtracking 在梯度下降期间要使用的回溯类型。fold_len_multiplier folds长度系数。设置大于1的参数,在参数较小时获得最佳结果。默认2。approx_on_full_history 计算近似值,False:使用1/fold_len_multiplier计算;True:使用fold中前面所有行计算。默认False。class_weights 类别的权重。默认None。scale_pos_weight 二进制分类中class 1的权重。该值用作class 1中对象权重的乘数。boosting_type 增压方案allow_const_label 使用它为所有对象训练具有相同标签值的数据集的模型。默认为False 2.2默认参数CatBoost默认参数: ‘iterations’: 1000, ‘learning_rate’:0.03, ‘l2_leaf_reg’:3, ‘bagging_temperature’:1, ‘subsample’:0.66, ‘random_strength’:1, ‘depth’:6, ‘rsm’:1, ‘one_hot_max_size’:2 ‘leaf_estimation_method’:’Gradient’, ‘fold_len_multiplier’:2, ‘border_count’:128, 2.3性能参数 thread_count=-1:训练时所用的cpu/gpu核数used_ram_limit=None:CTR问题,计算时的内存限制gpu_ram_part=None:GPU内存限制 2.4参数调优采用GridSearchCV的方法进行自动搜索最优参数 示例: from catboost import CatBoostRegressor from sklearn.model_selection import GridSearchCV #指定category类型的列,可以是索引,也可以是列名 cat_features = [0,1,2,3,4,5,6,7,8,9,10,11,12,13] X = df_ios_droped.iloc[:,:-1] y = df_ios_droped.iloc[:,-1] cv_params = {'iterations': [500,600,700,800]} other_params = { 'iterations': 1000, 'learning_rate':0.03, 'l2_leaf_reg':3, 'bagging_temperature':1, 'random_strength':1, 'depth':6, 'rsm':1, 'one_hot_max_size':2, 'leaf_estimation_method':'Gradient', 'fold_len_multiplier':2, 'border_count':128, } model_cb = CatBoostRegressor(**other_params) optimized_cb = GridSearchCV(estimator=model_cb, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=2) optimized_cb.fit(X,y,cat_features =category_features) print('参数的最佳取值:{0}'.format(optimized_cb.best_params_)) print('最佳模型得分:{0}'.format(optimized_cb.best_score_)) print(optimized_cb.cv_results_['mean_test_score']) print(optimized_cb.cv_results_['params']) 3.CatBoost实战应用CatBoost可以用于分类和回归两种类型的应用,详细使用方法大家可以参考官方网站给出的案例 使用Gpu训练 from catboost import CatBoostClassifier train_data = [[0, 3], [4, 1], [8, 1], [9, 1]] train_labels = [0, 0, 1, 1] model = CatBoostClassifier(iterations=1000, task_type="GPU", devices='0:1') model.fit(train_data, train_labels, verbose=False) 3.2使用Pool加载数据集并进行预测Pool是catboost中的用于组织数据的一种形式,也可以用numpy array和dataframe。但更推荐Pool,其内存和速度都更优。 from catboost import CatBoostClassifier, Pool train_data = Pool(data=[[1, 4, 5, 6], [4, 5, 6, 7], [30, 40, 50, 60]], label=[1, 1, -1], weight=[0.1, 0.2, 0.3]) model = CatBoostClassifier(iterations=10) model.fit(train_data) preds_class = model.predict(train_data) 3.3多分类案例 from catboost import Pool, CatBoostClassifier train_data = [["summer", 1924, 44], ["summer", 1932, 37], ["winter", 1980, 37], ["summer", 2012, 204]] eval_data = [["winter", 1996, 197], ["winter", 1968, 37], ["summer", 2002, 77], ["summer", 1948, 59]] cat_features = [0] train_label = ["France", "USA", "USA", "UK"] eval_label = ["USA", "France", "USA", "UK"] train_dataset = Pool(data=train_data, label=train_label, cat_features=cat_features) eval_dataset = Pool(data=eval_data, label=eval_label, cat_features=cat_features) # Initialize CatBoostClassifier model = CatBoostClassifier(iterations=10, learning_rate=1, depth=2, loss_function='MultiClass') # Fit model model.fit(train_dataset) # Get predicted classes preds_class = model.predict(eval_dataset) # Get predicted probabilities for each class preds_proba = model.predict_proba(eval_dataset) # Get predicted RawFormulaVal preds_raw = model.predict(eval_dataset, prediction_type='RawFormulaVal') 4.总结后序还会更新关于lgb的相关内容,还是建议大家去看一下这几个方法的理论知识,也便于自己更好的使用模型。(共同学习进步!) 记录时间:2020年12月16日 |
【本文地址】