| yolov | 您所在的位置:网站首页 › groundtruth数据 › yolov |
yolov
|
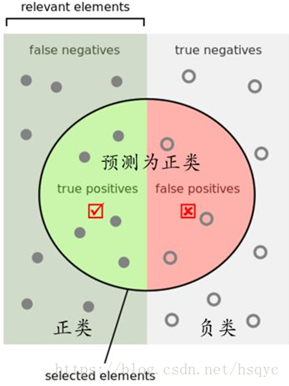
Yolov-1-TX2上用YOLOv3训练自己数据集的流程(VOC2007-TX2-GPU) Yolov--2--一文全面了解深度学习性能优化加速引擎---TensorRT Yolov--3--TensorRT中yolov3性能优化加速(基于caffe) yolov-5-目标检测:YOLOv2算法原理详解 yolov--8--Tensorflow实现YOLO v3 yolov--9--YOLO v3的剪枝优化 yolov--10--目标检测模型的参数评估指标详解、概念解析 yolov--11--YOLO v3的原版训练记录、mAP、AP、recall、precision、time等评价指标计算 yolov--12--YOLOv3的原理深度剖析和关键点讲解 1、目标检测中的mAP是什么含义? 关于Ground Truth:ground truth包括图像中物体的类别以及该图像中每个物体的真实边界框。mAP含义及计算:如何量化呢? 采用IoU(Intersection over Union),IoU是预测框与ground truth的交集和并集的比值。这个量也被称为Jaccard指数,并于20世纪初由Paul Jaccard首次提出。为了计算precision和recall,与所有机器学习问题一样,我们必须鉴别出True Positives(真正例)、False Positives(假正例)、True Negatives(真负例)和 False Negatives(假负例)。 TP TN FP FN是什么意思?T或者N代表的是该样本是否被分类分对,P或者N代表的是该样本被分为什么 TP(True Positives)意思我们倒着来翻译就是“被分为正样本,并且分对了”,TN(True Negatives)意思是“被分为负样本,而且分对了”,FP(False Positives)意思是“被分为正样本,但是分错了”,FN(False Negatives)意思是“被分为负样本,但是分错了”。 按下图来解释,左半矩形是正样本,右半矩形是负样本。一个2分类器,在图上画了个圆,分类器认为圆内是正样本,圆外是负样本。那么左半圆分类器认为是正样本,同时它确实是正样本,那么就是“被分为正样本,并且分对了”即TP,左半矩形扣除左半圆的部分就是分类器认为它是负样本,但是它本身却是正样本,就是“被分为负样本,但是分错了”即FN。右半圆分类器认为它是正样本,但是本身却是负样本,那么就是“被分为正样本,但是分错了”即FP。右半矩形扣除右半圆的部分就是分类器认为它是负样本,同时它本身确实是负样本,那么就是“被分为负样本,而且分对了”即TN
有了上面TP TN FP FN的概念,这个Precision和Recall的概念一张图就能说明。
原文:https://blog.csdn.net/hsqyc/article/details/81702437 mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值AP: PR曲线下面积,后文会详细讲解PR曲线: Precision-Recall曲线Precision: TP / (TP + FP)Recall: TP / (TP + FN)TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)FP: IoU= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例假设,对于Aeroplane类别,我们网络有以下输出(BB表示BoundingBox序号,IoU>0.5时GT=1): BB | confidence | GT ---------------------- BB1 | 0.9 | 1 ---------------------- BB2 | 0.9 | 1 ---------------------- BB1 | 0.8 | 1 ---------------------- BB3 | 0.7 | 0 ---------------------- BB4 | 0.7 | 0 ---------------------- BB5 | 0.7 | 1 ---------------------- BB6 | 0.7 | 0 ---------------------- BB7 | 0.7 | 0 ---------------------- BB8 | 0.7 | 1 ---------------------- BB9 | 0.7 | 1 ----------------------因此,我们有 TP=5 (BB1, BB2, BB5, BB8, BB9), FP=5 (重复检测到的BB1也算FP)。除了表里检测到的5个GT以外,我们还有2个GT没被检测到,因此: FN = 2. 这时我们就可以按照Confidence的顺序给出各处的PR值,如下: rank=1 precision=1.00 and recall=0.14 ---------- rank=2 precision=1.00 and recall=0.29 ---------- rank=3 precision=0.66 and recall=0.29 ---------- rank=4 precision=0.50 and recall=0.29 ---------- rank=5 precision=0.40 and recall=0.29 ---------- rank=6 precision=0.50 and recall=0.43 ---------- rank=7 precision=0.43 and recall=0.43 ---------- rank=8 precision=0.38 and recall=0.43 ---------- rank=9 precision=0.44 and recall=0.57 ---------- rank=10 precision=0.50 and recall=0.71 ----------对于上述PR值,如果我们采用: VOC2010之前的方法,我们选取Recall >= 0, 0.1, ..., 1的11处Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0, 0。此时Aeroplane类别的 AP = 5.5 / 11 = 0.5VOC2010及以后的方法,对于Recall >= 0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,我们选取此时Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0。此时Aeroplane类别的 AP = (0.14-0)*1 + (0.29-0.14)*1 + (0.43-0.29)*0.5 + (0.57-0.43)*0.5 + (0.71-0.57)*0.5 + (1-0.71)*0 = 0.5mAP就是对每一个类别都计算出AP然后再计算AP平均值就好了 更多信息建议参考GluonCV库里面的voc_detection.py实现了两种mAP计算方式,思路清晰: https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/voc_detection.pygithub.com https://www.zhihu.com/search?type=content&q=%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E4%B8%AD%E7%9A%84mAP%E6%98%AF%E4%BB%80%E4%B9%88 precision、Recall如何计算?为了获得True Positives and False Positives,我们需要使用IoU。计算IoU,我们从而确定一个检测结果(Positive)是正确的(True)还是错误的(False)。 最常用的阈值是0.5,即如果IoU> 0.5,则认为它是True Positive,否则认为是False Positive。而COCO数据集的评估指标建议对不同的IoU阈值进行计算,但为简单起见,我们这里仅讨论一个阈值0.5,这是PASCAL VOC数据集所用的指标。为了计算Recall,我们需要Negatives的数量。由于图片中我们没有预测到物体的每个部分都被视为Negative,因此计算True Negatives比较难办。但是我们可以只计算False Negatives,即我们模型所漏检的物体。另外一个需要考虑的因素是模型所给出的各个检测结果的置信度。通过改变置信度阈值,我们可以改变一个预测框是Positive还是 Negative,即改变预测值的正负性(不是box的真实正负性,是预测正负性)。基本上,阈值以上的所有预测(Box + Class)都被认为是Positives,并且低于该值的都是Negatives。对于每一个图片,ground truth数据会给出该图片中各个类别的实际物体数量。我们可以计算每个Positive预测框与ground truth的IoU值,并取最大的IoU值,认为该预测框检测到了那个IoU最大的ground truth。然后根据IoU阈值,我们可以计算出一张图片中各个类别的正确检测值(True Positives, TP)数量以及错误检测值数量(False Positives, FP)。据此,可以计算出各个类别的precision: 既然我们已经得到了正确的预测值数量(True Positives),也很容易计算出漏检的物体数(False Negatives, FN)。据此可以计算出Recall(其实分母可以用ground truth总数): 在目标检测中,mAP的定义首先出现在PASCAL Visual Objects Classes(VOC)竞赛中,这个大赛包含许多图像处理任务,详情可以参考这个paper(里面包含各个比赛的介绍以及评估等)。 前面我们已经讲述了如何计算Precision和Recall,但是,正如前面所述,至少有两个变量会影响Precision和Recall,即IoU和置信度阈值。IoU是一个简单的几何度量,可以很容易标准化,比如在PASCAL VOC竞赛中采用的IoU阈值为0.5,而COCO竞赛中在计算mAP较复杂,其计算了一系列IoU阈值(0.05至0.95)下的mAP。但是置信度却在不同模型会差异较大,可能在我的模型中置信度采用0.5却等价于在其它模型中采用0.8置信度,这会导致precision-recall曲线变化。为此,PASCAL VOC组织者想到了一种方法来解决这个问题,即要采用一种可以用于任何模型的评估指标。在paper中,他们推荐使用如下方式计算Average Precision(AP): For a given task and class, the precision/recall curve is computed from a method’s ranked output. Recall is defined as the proportion of all positive examples ranked above a given rank. Precision is the proportion of all examples above that rank which are from the positive class. The AP summarises the shape of the precision/recall curve, and is defined as the mean precision at a set of eleven equally spaced recall levels [0,0.1,...,1]:可以看到,为了得到precision-recall曲线,首先要对模型预测结果进行排序(ranked output,按照各个预测值置信度降序排列)。那么给定一个rank,Recall和Precision仅在高于该rank值的预测结果中计算,改变rank值会改变recall值。这里共选择11个不同的recall([0, 0.1, ..., 0.9, 1.0]),可以认为是选择了11个rank,由于按照置信度排序,所以实际上等于选择了11个不同的置信度阈值。那么,AP就定义为在这11个recall下precision的平均值,其可以表征整个precision-recall曲线(曲线下面积)。
另外,在计算precision时采用一种插值方法(interpolate): 及对于某个recall值r,precision值取所有recall>=r中的最大值(这样保证了p-r曲线是单调递减的,避免曲线出现摇摆):
不过这里VOC数据集在2007年提出的mAP计算方法,而在2010之后却使用了所有数据点,而不是仅使用11个recall值来计算AP(详细参考这篇paper): Up until 2009 interpolated average precision (Salton and Mcgill 1986) was used to evaluate both classification and detection. However, from 2010 onwards the method of computing AP changed to use all data points rather than TREC-style sampling (which only sampled the monotonically decreasing curve at a fixed set of uniformly-spaced recall values 0, 0.1, 0.2,..., 1). The intention in interpolating the precision–recall curve was to reduce the impact of the ‘wiggles’ in the precision–recall curve, caused by small variations in the ranking of examples. However, the downside of this interpolation was that the evaluation was too crude to discriminate between the methods at low AP.对于各个类别,分别按照上述方式计算AP,取所有类别的AP平均值就是mAP。这就是在目标检测问题中mAP的计算方法。可能有时会发生些许变化,如COCO数据集采用的计算方式更严格,其计算了不同IoU阈值和物体大小下的AP(详情参考COCO Detection Evaluation)。 当比较mAP值,记住以下要点: mAP通常是在一个数据集上计算得到的。虽然解释模型输出的绝对量化并不容易,但mAP作为一个相对较好的度量指标可以帮助我们。 当我们在流行的公共数据集上计算这个度量时,该度量可以很容易地用来比较目标检测问题的新旧方法。根据训练数据中各个类的分布情况,mAP值可能在某些类(具有良好的训练数据)非常高,而其他类(具有较少/不良数据)却比较低。所以你的mAP可能是中等的,但是你的模型可能对某些类非常好,对某些类非常不好。因此,建议在分析模型结果时查看各个类的AP值。这些值也许暗示你需要添加更多的训练样本。 代码实现Facebook开源的Detectron包含VOC数据集的mAP计算,这里贴出其核心实现,以对mAP的计算有更深入的理解。首先是precision和recall的计算: # 按照置信度降序排序 sorted_ind = np.argsort(-confidence) BB = BB[sorted_ind, :] # 预测框坐标 image_ids = [image_ids[x] for x in sorted_ind] # 各个预测框的对应图片id # 便利预测框,并统计TPs和FPs nd = len(image_ids) tp = np.zeros(nd) fp = np.zeros(nd) for d in range(nd): R = class_recs[image_ids[d]] bb = BB[d, :].astype(float) ovmax = -np.inf BBGT = R['bbox'].astype(float) # ground truth if BBGT.size > 0: # 计算IoU # intersection ixmin = np.maximum(BBGT[:, 0], bb[0]) iymin = np.maximum(BBGT[:, 1], bb[1]) ixmax = np.minimum(BBGT[:, 2], bb[2]) iymax = np.minimum(BBGT[:, 3], bb[3]) iw = np.maximum(ixmax - ixmin + 1., 0.) ih = np.maximum(iymax - iymin + 1., 0.) inters = iw * ih # union uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) + (BBGT[:, 2] - BBGT[:, 0] + 1.) * (BBGT[:, 3] - BBGT[:, 1] + 1.) - inters) overlaps = inters / uni ovmax = np.max(overlaps) jmax = np.argmax(overlaps) # 取最大的IoU if ovmax > ovthresh: # 是否大于阈值 if not R['difficult'][jmax]: # 非difficult物体 if not R['det'][jmax]: # 未被检测 tp[d] = 1. R['det'][jmax] = 1 # 标记已被检测 else: fp[d] = 1. else: fp[d] = 1. # 计算precision recall fp = np.cumsum(fp) tp = np.cumsum(tp) rec = tp / float(npos) # avoid divide by zero in case the first detection matches a difficult # ground truth prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)这里最终得到一系列的precision和recall值,并且这些值是按照置信度降低排列统计的,可以认为是取不同的置信度阈值(或者rank值)得到的。然后据此可以计算AP: def voc_ap(rec, prec, use_07_metric=False): """Compute VOC AP given precision and recall. If use_07_metric is true, uses the VOC 07 11-point method (default:False). """ if use_07_metric: # 使用07年方法 # 11 个点 ap = 0. for t in np.arange(0., 1.1, 0.1): if np.sum(rec >= t) == 0: p = 0 else: p = np.max(prec[rec >= t]) # 插值 ap = ap + p / 11. else: # 新方式,计算所有点 # correct AP calculation # first append sentinel values at the end mrec = np.concatenate(([0.], rec, [1.])) mpre = np.concatenate(([0.], prec, [0.])) # compute the precision 曲线值(也用了插值) for i in range(mpre.size - 1, 0, -1): mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) # to calculate area under PR curve, look for points # where X axis (recall) changes value i = np.where(mrec[1:] != mrec[:-1])[0] # and sum (\Delta recall) * prec ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) return ap计算各个类别的AP值后,取平均值就可以得到最终的mAP值了。但是对于COCO数据集相对比较复杂,不过其提供了计算的API,感兴趣可以看一下cocodataset/cocoapi。 注:译文相比原文略有删改。 https://zhuanlan.zhihu.com/p/37910324 https://www.zhihu.com/search?type=content&q=%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E4%B8%AD%E7%9A%84mAP%E6%98%AF%E4%BB%80%E4%B9%88 举例计算mAP有3张图如下,要求算法找出face。蓝色框代表标签label,绿色框代表算法给出的结果pre,旁边的红色小字代表置信度。设定第一张图的检出框叫pre1,第一张的标签框叫label1。第二张、第三张同理。 1.根据IOU计算TP,FP 首先我们计算每张图的pre和label的IOU,根据IOU是否大于0.5来判断该pre是属于TP还是属于FP。显而易见,pre1是TP,pre2是FP,pre3是TP。 2.根据置信度阈值排序 根据每个pre的置信度阈值进行从高到低排序,这里pre1、pre2、pre3置信度刚好就是从高到低。 3.在不同置信度阈值下获得Precision和Recall 首先,设置阈值为0.9,无视所有小于0.9的pre。那么检测器检出的所有框pre即TP+FP=1,并且pre1是TP,那么Precision=1/1。因为所有的label=3,所以Recall=1/3。这样就得到一组P、R值。 然后,设置阈值为0.8,无视所有小于0.8的pre。那么检测器检出的所有框pre即TP+FP=2,因为pre1是TP,pre2是FP,那么Precision=1/2=0.5。因为所有的label=3,所以Recall=1/3=0.33。这样就又得到一组P、R值。 再然后,设置阈值为0.7,无视所有小于0.7的pre。那么检测器检出的所有框pre即TP+FP=3,因为pre1是TP,pre2是FP,pre3是TP,那么Precision=2/3=0.67。因为所有的label=3,所以Recall=2/3=0.67。这样就又得到一组P、R值。 4.绘制PR曲线并计算AP值 根据上面3组PR值绘制PR曲线如下。然后每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是AP值。 在这里 5.计算mAP AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。比如有两类,类A的AP值是0.5,类B的AP值是0.2,那么mAP=(0.5+0.2)/2=0.35 Github 在这里提供一个计算mAP的github地址,上面那张AP图就是它生成的。我觉得还蛮好用的。 https://github.com/Cartucho/mAP 若加微信请备注下姓名_公司/学校,相遇即缘分,感谢您的支持,愿真诚交流,共同进步,谢谢~ 原文:https://blog.csdn.net/hsqyc/article/details/81702437 https://pan.baidu.com/s/1b19ewu |


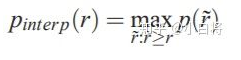





【本文地址】