| GPU | 您所在的位置:网站首页 › gpu专用内存怎么改 › GPU |
GPU
|
0.前言 如果单纯想使用CUDA进行编程,其实非常简单,安装Nv提供的SDK就可以了,但是如果想能够真正利用CUDA、GPU能够提供给我们的所有性能,需要和CPU编程一样,要写出符合硬件底层框架结构的代码,这样面向编译器编程,在CUDA中会灵活很多,在CUDA中我们可以控制Grid、Block、Thread的分配以及,本文提及的共享内存。 为什么要优化共享内存,无论是在CPU编程还是GPU编程的时候,我们不仅仅需要考虑我们运行算法的速度,在大数据量的情况下,访存速度是我们需要关注的一个重点,而CPU中处理访存,大多情况下我们都需要面向编译器编程,也就是自己的代码写法和编译器访存存在一一对应的关系,这样我们对寄存器、Cache、主存都是不可编程的。但是在CUDAGPU编程中,我们可以控制寄存器和L1 Cache也就是提供的共享内存,利用共享内存,我们可以在数据共享的情况下,尽可能的加速访存速度。 注:文中可能有还没有完全理解的地方,能够提出修改意见更好 1.CPU访存策略如果是用CPU进行访存,之前提到了,我们实际上是面向编译器编程的方式,因为我们自己是无法在代码中直接写出我们想怎么样利用寄存器和Cache,寄存器的使用是汇编代码实现的,而Cache、主存的使用是操作系统及硬件系统提供的。在这个部分,我提供一个矩阵乘法的例子,并且用VTune进行性能分析,来查看整体的访存性能。 在矩阵乘法运算中,最需要注意的就是B矩阵的连续访存问题,如果我们代码用最基本的方式写,那么会是这样。  可以明显发现,在整体的内存访问中,对B的访存是不连续的,同时我们可以在VTune下查看他的汇编代码以及耗时情况。  有如下几点发现:①编译器在优化的情况下已经自动将我们的计算步骤向量化,已经使用了XMM寄存器以及SSE指令集,这里使用的mulss指令,不会对xmm寄存器中所有的值都操作,而是将下32位纳入计算中,其他部分不会计算,所以这里虽然做了四次SSE指令,但是也只有4次运算②有四条mulss指令,观察发现,前面三条指令耗时几乎是第四条mulss指令的15~25倍,说明了mulss的指令原本其实有这很高的效率,为什么前面的mulss指令存在较大的耗时,是因为mulss指令不仅仅是运算,在X86_64架构下面汇编指令往往可以和内存读取绑定在一起,这样在mulss的时候其实隐式触发了内存读取操作,这样在前面计算的时候,存在很多非连续访存的操作,导致了大量的CacheMiss。为了印证这个想法,我做了如下的测试。  可以发现,这里的代码和上面的代码由两处不同,首先我们将j和k的位置翻转了一下,这样我们可以保证C和B的内存访问都变成连续的了,其次,我们将A的访问变成了一个变量,这样可以隐式将这个变量保存在栈中,可以减少对A数组的主存访问,这个时候因为C的向量化,我们没法用一个单独的变量去保存结果值,这里可能会造成一定的性能损失,但不管怎么样先看下VTune里面的结果。  有如下几点发现:①首先可以看见整体的性能损耗变得很低,提升大概有350%左右②两段代码的汇编说明了mulss数量一致,但是其耗时完全不一样,最大的时间点耗在了一个addss指令上面,可以说明,我们对B、C矩阵的连续访存很重要,可以保证我们的代码可以贴近CPU汇编的访存方式,通过好的汇编指令,优化整体性能。 同样,在之前硬件矩阵乘法优化的时候我也提出了一种Transpose的想法,这样的话,也可以提高整体连续访存的效率。   此处还有额外的两个测试,是同种类型的,也就是没有使用exchange,但是将B矩阵做了transpose,其MemoryBound直接降低了24%~26%,最原始的内存访问方式中LLC(Last Level Cache) Miss量大的可怕,意思就是基本上,大量的内存访问都是忽视了Cache这样的加速结构。在后面的分析中,我还发现了对于两个Transpose的方法对比,如果用变量作为辅助,在Store这一项中,用了一个变量来间接存储的方式,比直接用C矩阵作为左值进行赋值的方式,在Store的次数方面少了几个量级。 我后面又去想了完全向量化的方法,利用AVX2指令集,利用提供的库手写SIMD指令,因为测试的时候TYPE使用的是float 32位,一个支持AVX2的ymm寄存器是256位,所以设定size为8。然后在循环中利用SIMD加速计算。具体SIMD指令可以参考[1]  利用VTune对Memory进行Profile,可以得到如下的结果,这个结果对内存访问的描述比Hotspots更加详细。  可以发现前面四项基本上还是和上面分析的一致,我们优化之后的版本效率的确不错,但是DRAM Bound太高,Average Latency高达63。 疑问:但是按理来说我们对内存的访问和原始的exchange版本应该是一样的,为什么两者的内存访问差异这么大,后续还是要对这个部分进行优化。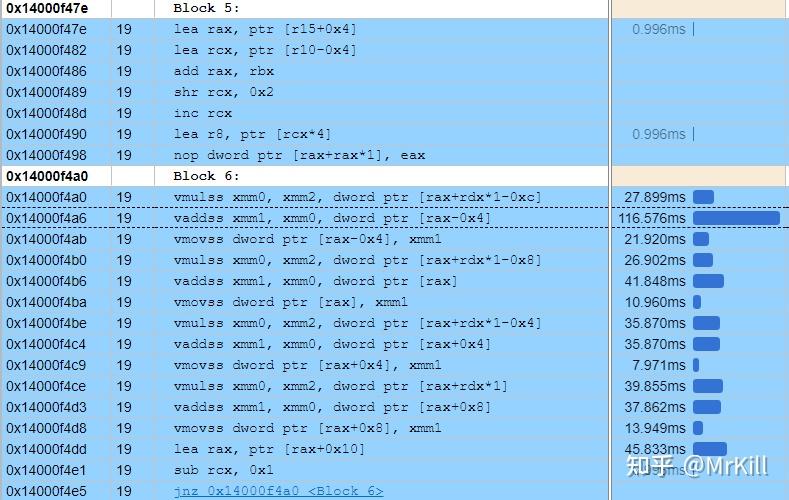 serial_matmul_exchange serial_matmul_exchange serial_matmul_exchange_opt serial_matmul_exchange_opt自己写的AVX提供的指令是ps结尾的,说明的确在SIMD并行了。当然还会有多线程和MPI的方法,但是CPU部分的多线程还是不够优秀,甚至我们还可以通过卡cache来实现访存加速,我的C技术还不足以能够考虑到这些。 2021年6月29日更新日志: 在CPU计算部分我当时觉得自己C技术不太够,然后买了本《GPU Parallel Program Development Using CUDA》前面讲了很多CPU的优化方法,恶补了两天,将原本的优化通过Cache和OpenMP的多线程加强了一下。以下数据是在2048*2048的规模下,下面两个优化方法开了6线程,其中非Part版本我是用的动态分配的Buffer,而Part版本的Cache优化,是固定了BufferSize卡在了L1 Cache,然后对问题进行分块计算,这样其实优化了A和C的访存,但是增加了B的不连续访问(这个部分是消耗大头),后期可能还有希望优化这个Part的访存方式,不过相比较与最原始的结果加速比已经快接近100倍了。  2.GPU访存策略[2] 2.GPU访存策略[2]上面对CPU的性能分析,可以很容易的引申想到一个问题,我们是否能够用这样的方法降低GPU端的访存时间,这个想法是很自然的,当然结果也是很出人意料的。这里不会过多赘述关于GPU架构的事情,着重讲一下我们需要重点注意的事项,也就是,共享内存(Shared Memory)是对于一个Block而言的,并且其内存级别是L1 Cache,一个Block对应一个流多处理器(Stream Multiprocessor),在CUDA中,基本的同步运行单元不是一个Block,而是一个Warp(SM中并发执行线程束)——即32个Thread(在Nv显卡评价体系中的一项计算能力在1.2版本之后就将原本24个Thread提升到了32个Thread,1.2版本及以下的显卡基本上很难看见了,所以默认Warp就是以32Thread为整体,进行同步和运行)。 熟悉体系结构的人大概都能够理解L1 Cache的性能水平,是作为仅次于寄存器的访问速度,为寄存器存储数据的一级Cache体系,CUDA提供了可编程的共享内存,我可以提出自己的访存优化基本思想也就是——在编程阶段尽量利用好共享内存。 仍然以矩阵乘法为例子介绍我对GPU访存的优化方法,以及各种写法是如何体现GPU硬件架构执行方法的。 首先来看这样的问题。 策略一:既然我们有这么多Thread,那在一个Grid上每个Thread都分配C矩阵中的一个element,如果不太能理解的话,意思就是,我们将Block这个层级给忽视掉(但不是在编程阶段不分配,我们需要分配的Block数量就是# of C elements/# of max Threads in one block),所有分配的Thread数量就等同于C矩阵的长*宽。下面图示说明了C的行列对应的(Block,Thread)的线程位置。  策略二:虽然我们有这么多Thread,但是感觉资源还是不能乱用,将C矩阵中的一行计算量分配到一个Block上面去,然后再在Block里面分配该行的element到Thread中。也就是,我们不将整个C矩阵平铺到Grid上,而是将C矩阵的一行结果的计算分配给一个Block,那么我们需要的Block数量就是C的行数,因为一行的element数可能会超过一个Block里面分配的最大Thread数量,每个Thread可能就需要计算多个C的结果,如果不清楚,可以利用下面这个示意来理解一下。C行的编号和一个Block内的Thread编号对应关系,所以我们每个Thread里面需要对自己处理C行的位置做一个循环,知道当前Thread认为要处理的C element id比C行要长,说明Thread就执行结束了,这里是一维是因为都是同一个Block内的,所有Block都可以被这个表示。  两个策略介绍完毕,如果没有测试结果,如果从直观上理解的话(以下的陈述都是基于4096*4096数据量),第一种方案申请的线程比第二种方案申请的线程多,按理来说高线程维度应该意味着高效率;从另一种角度来说,第二种方案里面的每个线程都要计算4个C结果而第一种方案里面每个线程都只需要计算1个C结果。  策略一 策略一 策略二 策略二 利用nvprof可以发现,原本利用了更多计算资源的Grid方法,效率反而更加不堪,甚至连持平都算不上,这就说明了GPU编程的第一点,并不是多Thread就代表更多的性能,要依靠架构来构建计算模型,那么是为什么多Thread会导致低的效率呢?我们的策略是将计算平铺在Grid上,那么一个Block中的Thread计算可能需要访问A的不同行,那么A的访存其实是存在不连续的问题的,原本只有B是不连续的缓存,并且多资源意味着多的Launch开销。 那我们就以Block模型作为框架继续后面的实验,在CPU阶段我们利用了exchange和transpose的方法来优化内存访问,如果我们在GPU架构下也这样优化,会导致什么结果呢?  实验结果看出来,如果我们和CPU一样对B进行转置操作,那么其耗时将会比Grid更加长,达到了整个系统测试中最坏的情况,我们此时还是在全局内存中进行实验的。这个暂时还是只有我的猜想:我们原始版本的代码,对于每一个Thread的访存是不连续的,但是我们并不是以Thread为单位运行,而是以Warp为单位进行,这个时候访存如果访问B[k*Num+c],那么Warp中的整体访存会是B[k*Num+c1:k*Num+c32]这个整体内存提取是连续的,而我们取转置的话会导致单一Thread访存是连续的但是整体Warp访存是不连续的,这样可以对应上GPU架构计算的问题,我认为这种描述是合理的。当然,这个时候我同时也测试了A_trans,这个效率又并没有提升,没有提升并不意味着可以推翻我前面的分析。B的访存是以c作为单位,也就是ThreadId,而A的访存是以r作为单位,也就是BlockId,我们作为一整个单位的是Warp也就是同一个Block内的32个Thread,所以对与同一个Block的所有Thread,所有A的访问是固定的,也就是A[r*Num:(r+1)*Num],这个值可以放在Block的内存中,如果转置访问,可能每个Block中保存A的Cache在不断地刷新,因为A的访问同步比B的需求低,所以性能影响没有B那么大。 后面通过查阅官方文档[3]中对3.X计算能力下Global Memory的描述,可以发现的确是以Warp为单位进行全局内存访存的,提供的图中更多的表示的是Cache在访存时的表现,但是也可以作为一个直观的Warp内存访问参考。原文有个对L1 Cache和L2 Cache的描述。 A cache line is 128 bytes and maps to a 128 byte aligned segment in device memory. Memory accesses that are cached in both L1 and L2 are serviced with 128-byte memory transactions, whereas memory accesses that are cached in L2 only are serviced with 32-byte memory transactions. Caching in L2 only can therefore reduce over-fetch, for example, in the case of scattered memory accesses.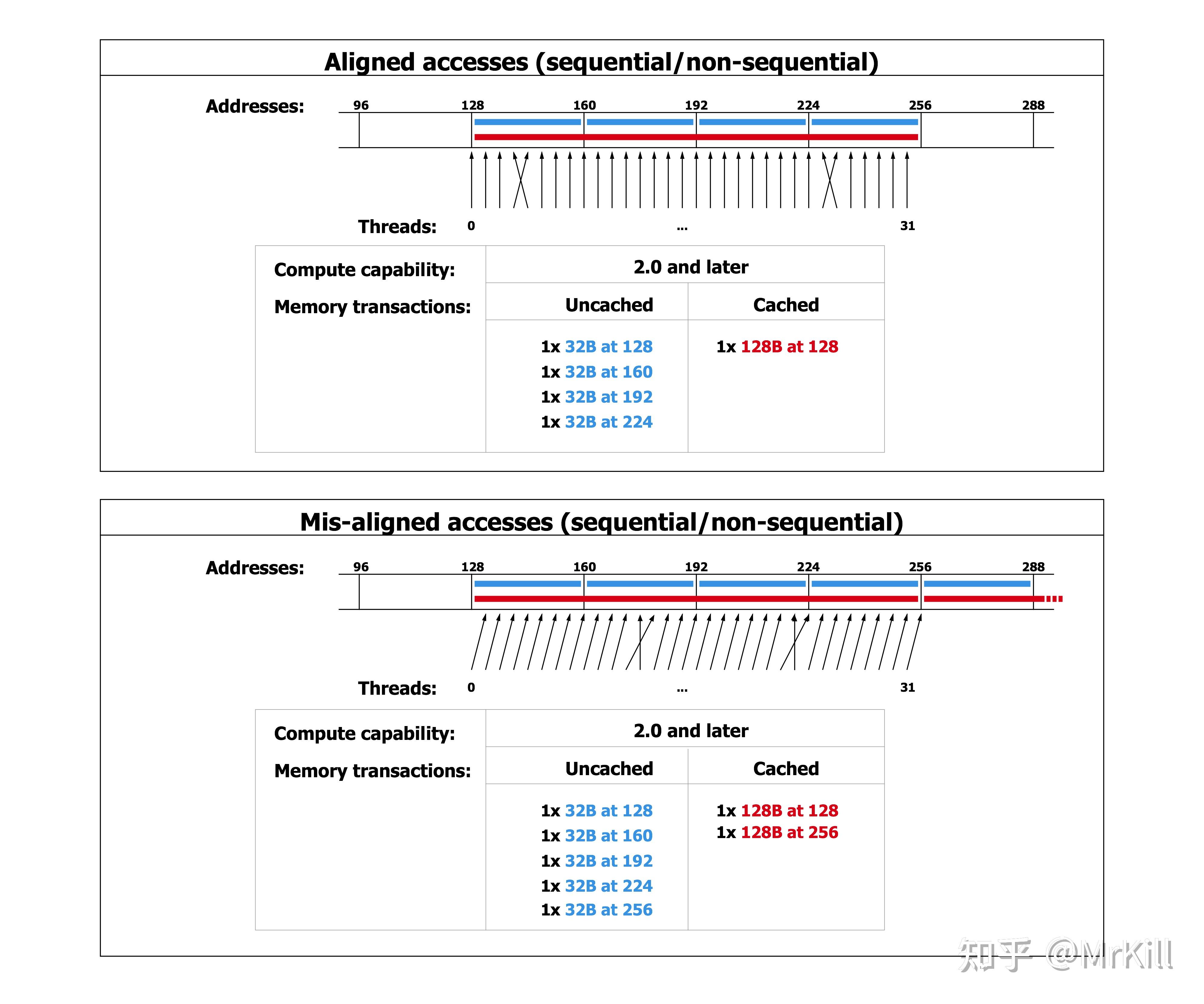 来源自Nv官方文档 来源自Nv官方文档差不多需要导入shared memory了,我们直到目前为止,所有的内存分配策略都是依赖于编译器的“心情”,但是shared memory作为programmable L1 cache,我们可以将重复的数据load到shared memory,然后直接从这里面load大量重复数据到reg。可能需要额外解释一下,每个Thread读取的A都是自己需要的A,然后Block内的所有Thread都并行执行,那么sharedData就会读取到A一行的数据。这里存在一个线程同步指令,是为了保证下面在获取shared数据的时候,所有线程都取到数了。  共享内存版本 共享内存版本 4096*4096规模 4096*4096规模实验结果看出来,一个意外的惊喜,也就是我们的共享内存的版本并没有原版好,但是可以看出来,我们A_trans优化的确起了作用,因为之前的测试都是在4096*4096的方阵中测试的,我将数据量调小到512*512。  512*512规模 512*512规模在小的数据规模阶段,很多之前因为数据访问量导致的问题都缩小了,Block的性能甚至不如Grid(当然这不应该是主要考虑的,因为在数据量小的时候,Grid所承担的内存冲突减少了许多,并且其整体消耗的资源更加多)在数据量小的时候,shared memory优化体现了很好的性能,说明之前性能问题并不是因为shared memory的效率而引起的,更有可能的是因为数据规模导致了另一项计算属性的变化导致的。后面通过查阅资料得知,当分配的共享内存过多的时候会影响warp的活跃数量(系统为了压制整体共享内存容量),所以我应该要手动压制共享内存,然后换取更高的warp收益,并且之后我也用nvprof的--print-gpu-trace写出了更加详细的结果,下面的profile结果表现了SSMem和DSMem的使用情况。 //!!!Profiler描述 Regs: Number of registers used per CUDA thread. This number includes registers used internally by the CUDA driver and/or tools and can be more than what the compiler shows. SSMem: Static shared memory allocated per CUDA block. DSMem: Dynamic shared memory allocated per CUDA block. SrcMemType: The type of source memory accessed by memory operation/copy DstMemType: The type of destination memory accessed by memory operation/copy //!!!数据量在512的情况下 ==26596== Profiling application: .\rank.exe ==26596== Profiling result: Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput SrcMemType DstMemType Device Context Stream Name 316.52ms 161.54us - - - - - 1.0000MB 6.0453GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 316.93ms 161.35us - - - - - 1.0000MB 6.0525GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 317.09ms 812.05us (512 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_grid(float const *, float const *, float*, int) [115] 318.47ms 1.2841ms (512 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block(float const *, float const *, float*, int) [120] 320.25ms 7.8293ms (512 1 1) (1024 1 1) 31 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_B(float const *, float const *, float*, int) [125] 328.57ms 833.24us (512 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_A(float const *, float const *, float*, int) [130] 329.65ms 483.50us (512 1 1) (1024 1 1) 32 0B 2.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared(float const *, float const *, float*, int) [135] 330.32ms 7.0978ms (512 1 1) (1024 1 1) 30 0B 2.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_B_shared(float const *, float const *, float*, int) [139] 337.73ms 486.16us (512 1 1) (1024 1 1) 32 0B 2.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_A_shared(float const *, float const *, float*, int) [144] 338.45ms 1.4263ms (512 1 1) (1024 1 1) 40 4.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared_opt(float const *, float const *, float*, int) [149] 340.10ms 392.84us (16 16 1) (32 32 1) 28 8.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker(float const *, float const *, float*, int) [154] 341.25ms 774.74us (16 16 1) (32 32 1) 30 8.2500KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker_opt(float const *, float const *, float*, int) [159] //!!!数据量在1024的情况下 ==12004== Profiling application: .\rank.exe ==12004== Profiling result: Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput SrcMemType DstMemType Device Context Stream Name 387.91ms 844.79us - - - - - 4.0000MB 4.6239GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 389.05ms 1.4978ms - - - - - 4.0000MB 2.6080GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 390.60ms 10.916ms (1024 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_grid(float const *, float const *, float*, int) [115] 402.41ms 10.997ms (1024 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block(float const *, float const *, float*, int) [120] 413.87ms 70.587ms 497.06ms 8.0363ms (1024 1 1) (1024 1 1) 32 0B 4.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared(float const *, float const *, float*, int) [135] 505.82ms 57.591ms (1024 1 1) (1024 1 1) 30 0B 4.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_B_shared(float const *, float const *, float*, int) [139] 564.30ms 6.9879ms (1024 1 1) (1024 1 1) 32 0B 4.0000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_A_shared(float const *, float const *, float*, int) [144] 571.74ms 6.1819ms (1024 1 1) (1024 1 1) 40 4.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared_opt(float const *, float const *, float*, int) [149] 578.69ms 2.4475ms (32 32 1) (32 32 1) 28 8.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker(float const *, float const *, float*, int) [154] 581.44ms 2.9623ms (32 32 1) (32 32 1) 30 8.2500KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker_opt(float const *, float const *, float*, int) [159] //!!!数据量在4096的情况下 ==21704== Profiling application: .\rank.exe ==21704== Profiling result: Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput SrcMemType DstMemType Device Context Stream Name 296.99ms 18.888ms - - - - - 64.000MB 3.3089GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 316.19ms 18.080ms - - - - - 64.000MB 3.4569GB/s Pageable Device GeForce GTX 107 1 7 [CUDA memcpy HtoD] 334.27ms 1.34147s (16384 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_grid(float const *, float const *, float*, int) [115] 1.67664s 1.31505s (4096 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block(float const *, float const *, float*, int) [120] 2.99232s 6.32444s (4096 1 1) (1024 1 1) 31 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_B(float const *, float const *, float*, int) [125] 9.31758s 1.59079s (4096 1 1) (1024 1 1) 32 0B 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_A(float const *, float const *, float*, int) [130] 10.9091s 1.58318s (4096 1 1) (1024 1 1) 32 0B 16.000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared(float const *, float const *, float*, int) [135] 12.4928s 5.31664s (4096 1 1) (1024 1 1) 30 0B 16.000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_B_shared(float const *, float const *, float*, int) [139] 17.8102s 1.46801s (4096 1 1) (1024 1 1) 32 0B 16.000KB - - - - GeForce GTX 107 1 7 parallel_matmul_block_trans_A_shared(float const *, float const *, float*, int) [144] 19.2788s 366.97ms (4096 1 1) (1024 1 1) 40 4.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_block_shared_opt(float const *, float const *, float*, int) [149] 19.6466s 205.24ms (128 128 1) (32 32 1) 28 8.0000KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker(float const *, float const *, float*, int) [154] 19.8524s 238.35ms (128 128 1) (32 32 1) 30 8.2500KB 0B - - - - GeForce GTX 107 1 7 parallel_matmul_checker_opt(float const *, float const *, float*, int) [159]我们之前是A中一行的数据都要放在共享内存内部,这样在扩大的时候共享内存太大导致Warp活跃数降低。那么我们可以利用分阶段将每一行的A分为多段,然后每一段就是共享存储需要的内存,是我们设置固定的,所以按照这种逻辑在处理一行的数据的时候,我们共享内存也需要刷新。因为对sharedData操作很多,我们都需要同步。  结果数据可以查阅上面提供的nvprof的导出,实现结果和参考资料中提供的架构策略一致,的确是存在共享内存太多导致Warp活跃数量较低的因素(比较普通的shared和shared_opt就可以看出来)动态内存分配的时候可能会在运行时动态将内存分配出来,并且降低Warp活性,但是静态内存分配会在编译阶段判断是否溢出来控制是否运行。动态分配更加灵活,但是潜在的性能下降概率更大。 根据上面想法更新的计算结构: 既然我们已经可以将横向分块,那么我们可以将矩阵分为小块,每一块计算的时候,都是两个共享内存块在A、B中移动计算,这个时候,共享内存的灵活度应该更大。 并且根据上面的实验,采用静态shared memory分配应该更好。还利用CUDA提供的二维Block和Thread,可以将C矩阵分割给Block,然后每个分割中的element给Block下的Thread,这个时候Thread内共享与棋盘大小相同的A矩阵和B矩阵。  计算结果同样可以参考上面的nvprof。二维棋盘式访存优化可以达到目前最快的访存速度,个人认为与一维访存优化更快的原因是,同一个Block里面对A的访存也被优化了,这样访存优化效率是对两个初始矩阵都存在读入优化。 使用共享内存还存在一个很重要的问题,就是Bank Conflict,这是也是由于之前提到过的,GPU中以Warp为单位执行操作,当Warp想读写同一个地方的时候,会存在冲突。 注[3]:网上还有少数老的文章会提及以half warp为一个内存操作的说法,根据Nv的官方文档在显卡属性——计算能力版本这一项参数指标,在计算能力2.0升级的描述中,已经说明了Bank已经达到32,并且执行以Warp而不是1.X级别中的half warp执行方式,现在基本上没有这样架构的显卡了。GPU访存策略中还有一个很重要的点,就是Bank Conflict。是以Warp为单位的Thread去访存的时候,会遇见的访存冲突代价,下面是nv官方文档中提供的图示,个人认为还是很清楚的,图2说明了同时读同一个Bank里面的同一个数据会触发广播机制。  来源自Nv官方文档Left:Linear addressing with a stride of one 32-bit word (no bank conflict).Middle:Linear addressing with a stride of two 32-bit words (two-way bank conflict).Right:Linear addressing with a stride of three 32-bit words (no bank conflict). 来源自Nv官方文档Left:Linear addressing with a stride of one 32-bit word (no bank conflict).Middle:Linear addressing with a stride of two 32-bit words (two-way bank conflict).Right:Linear addressing with a stride of three 32-bit words (no bank conflict). 来源自Nv官方文档Left:Conflict-free access via random permutation.Middle:Conflict-free access since threads 3, 4, 6, 7, and 9 access the same word within bank 5.Right:Conflict-free broadcast access (threads access the same word within a bank). 来源自Nv官方文档Left:Conflict-free access via random permutation.Middle:Conflict-free access since threads 3, 4, 6, 7, and 9 access the same word within bank 5.Right:Conflict-free broadcast access (threads access the same word within a bank).如果我们需要频繁访问同一个共享内存中的一个Bank中的不同位置,那就GG了,有这样一个例子可以描述这样一个现象——矩阵转置。 const int blockSize = 32; __global__ void parallel_mattra_2d_shared(const TYPE* A, TYPE* C, int Num) { __shared__ TYPE tmp[blockSize][blockSize]; int xIndex = blockDim.x * blockIdx.x + threadIdx.x; int yIndex = blockDim.y * blockIdx.y + threadIdx.y; if (xIndex |
【本文地址】