| 如何在自己的电脑上复现开源论文里的代码 | 您所在的位置:网站首页 › gitub怎么下载别人的代码 › 如何在自己的电脑上复现开源论文里的代码 |
如何在自己的电脑上复现开源论文里的代码
|
如何在自己的电脑上复现开源论文里的代码
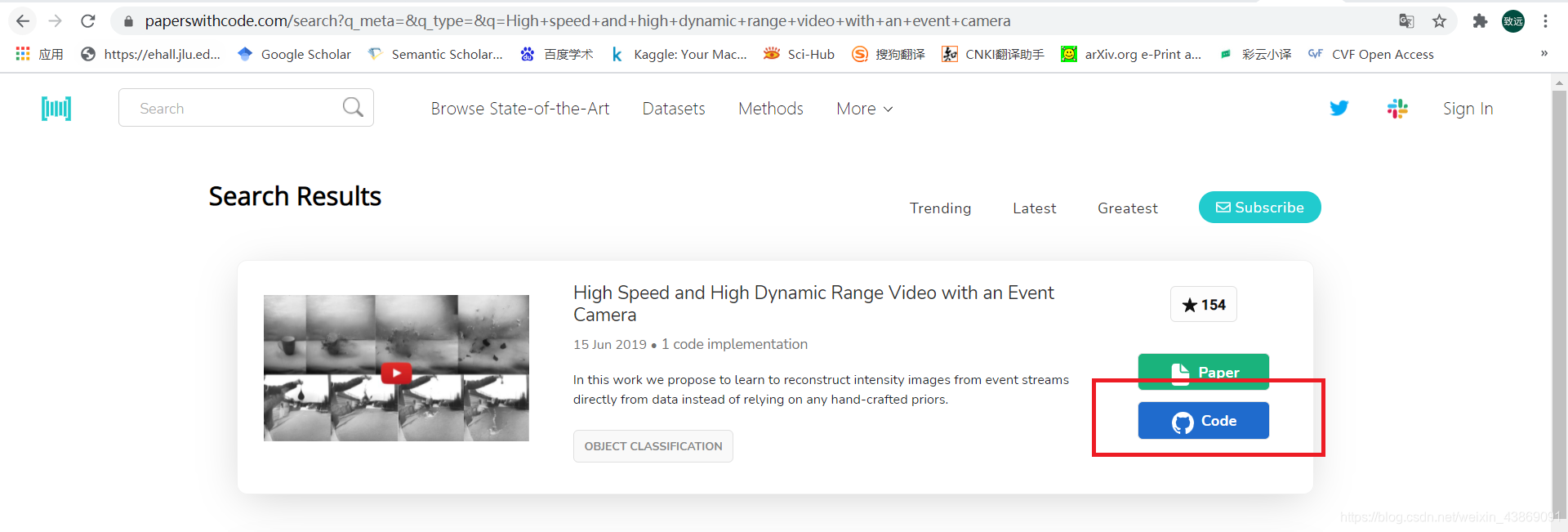
刚开始入门科研的小伙伴们总是苦于开源论文中的代码无法在自己的电脑上复现,接下来以文章High speed and high dynamic range video with an event camera作为线索来讲解如何在自己的电脑上运行论文里的代码。 步骤一:找到开源代码的链接不少开源论文在文中都附有代码的链接,点击访问即可找到对应的github工程,比如像这篇文章 如果没有的话也不必惊慌,如果论文是开源的,大多数情况下都可以去一些论文代码集成的网站上找到,这里推荐papers with code。打开网址,搜索框输出文章标题,即可搜索到代码链接: 进入对应的github工程,点击下载: 如果希望让我们的代码在自己的电脑上跑起来,我们就需要按照这里面的步骤去一步一步进行。实际上你可以使用markdown编辑器打开README文件,但是这里为了照顾大多数伙伴们,右键使用记事本将其打开进行阅读。 步骤四:安装相关依赖包、数据集与预训练权重
我们不一定需要完全遵从里面的每一个命令,例如在win10上的anaconda下载可使用图形化界面;如果你使用pip管理python包也可以使用pip,等等。总之,尽最大可能满足里面所写的对依赖包的要求。 随后根据提示从对应的网址下载预训练权重和数据文件。同样,我们可以将网页复制到浏览器直接进行下载,而不必使用命令进行下载。 这篇文章的REAMDE里面并没有写清楚下载后的文件应该放到哪里。根据经验,对应的文件应该放到对应名称的文件夹下。我们打开代码的当前目录,找到名称为data和pretrained的文件夹,将下载好的数据和预训练权重分别拷贝到这两个文件夹中。 接下来我们需要开始尝试运行代码。由于代码一般都是在linux上使用命令行运行,故在我们自己的电脑上也应该使用命令行运行代码。使用win+R,运行cmd,cd到当前目录,输入README中提到的运行命令: python run_reconstruction.py -c pretrained/E2VID_lightweight.pth.tar -i data/dynamic_6dof.zip --auto_hdr --display --show_events一般情况下代码就可以运行了。 当然如果你希望代码被多次运行,且使用可记录的参数,你可以在当前目录下新建一个txt文件,输入内容: cmd /k "python run_reconstruction.py -c pretrained/E2VID_lightweight.pth.tar -i data/dynamic_6dof.zip --auto_hdr --display --show_events"保存为后缀为bat的文件并双击运行,二者原理都是一样的。 至此,我们的代码可以在自己的电脑上运行了。 重要提醒:不少情况下,论文里的代码无法在自己的电脑上运行,可能是出于一下几个原因: 1.没有按照README里面的步骤进行操作 2.自己电脑上的依赖项、数据集、预训练权重等相关文件没有安装完整或者版本不匹配 3.Linux代码在windows上不兼容,可以通过在自己的电脑上安装虚拟机解决 4.可能是因为自己的电脑上的硬件不支持,例如报错显存不够。这时可以通过调整代码的运行参数来解决,例如选择较小的batch size或者分辨率 5.其它错误。常见的解决方案是将所报错误在网上进行搜索,查询论坛或者对相关硬件、依赖包提供技术支持的网站进行解决 |

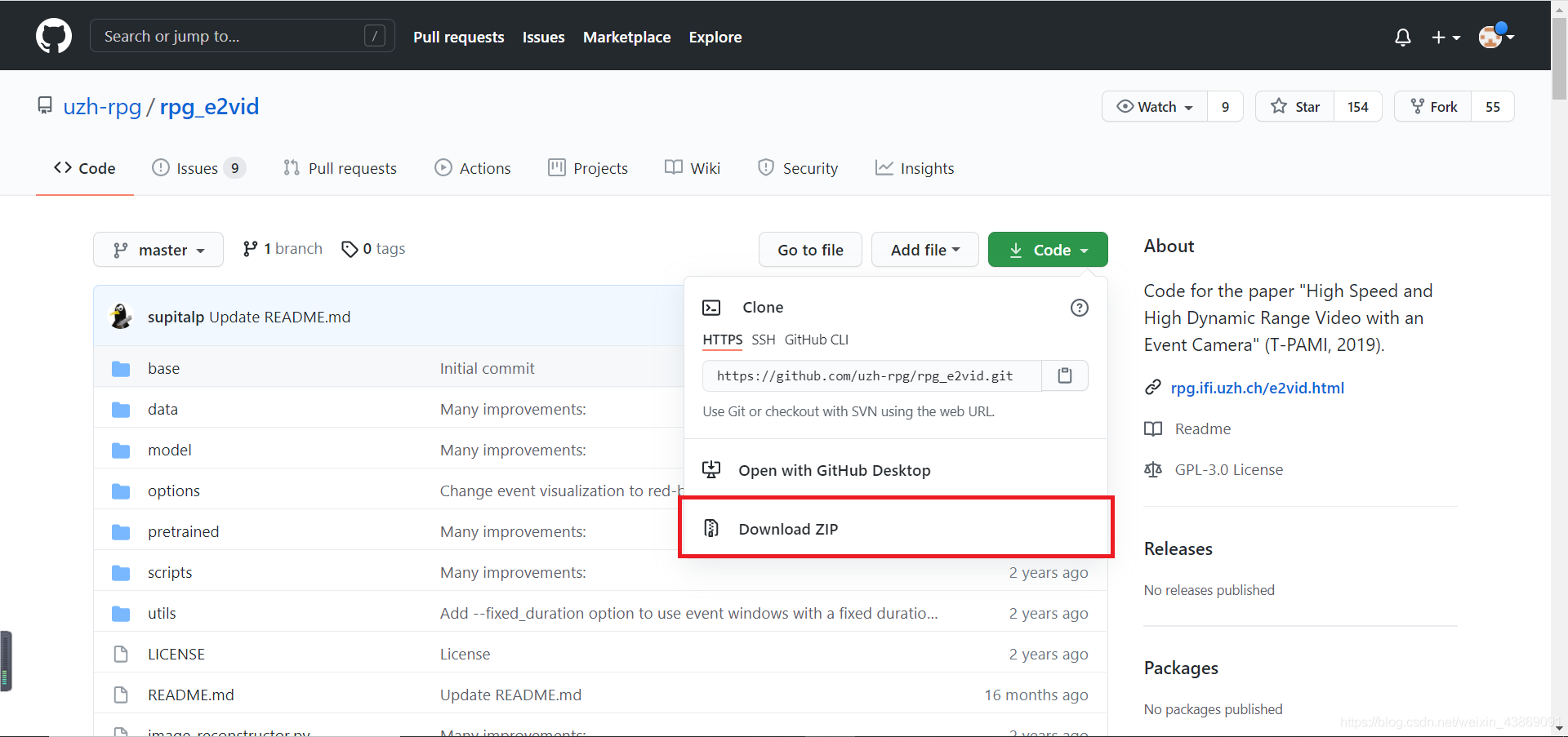
 此处选择你需要的代码版本:
此处选择你需要的代码版本: 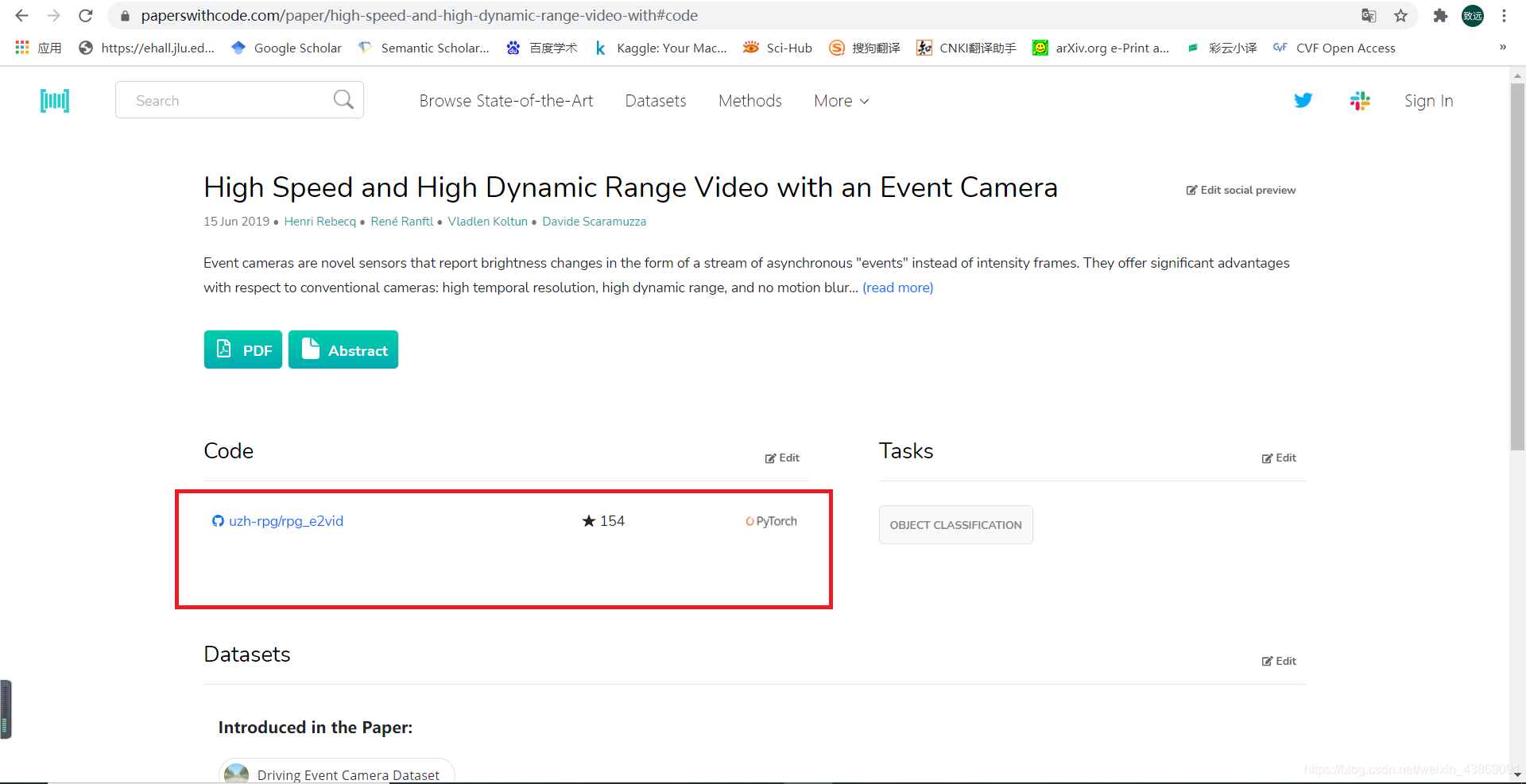
 得到对应代码的压缩包,进行解压。 大多数情况下,解压后的文件结构会形如这样:
得到对应代码的压缩包,进行解压。 大多数情况下,解压后的文件结构会形如这样: 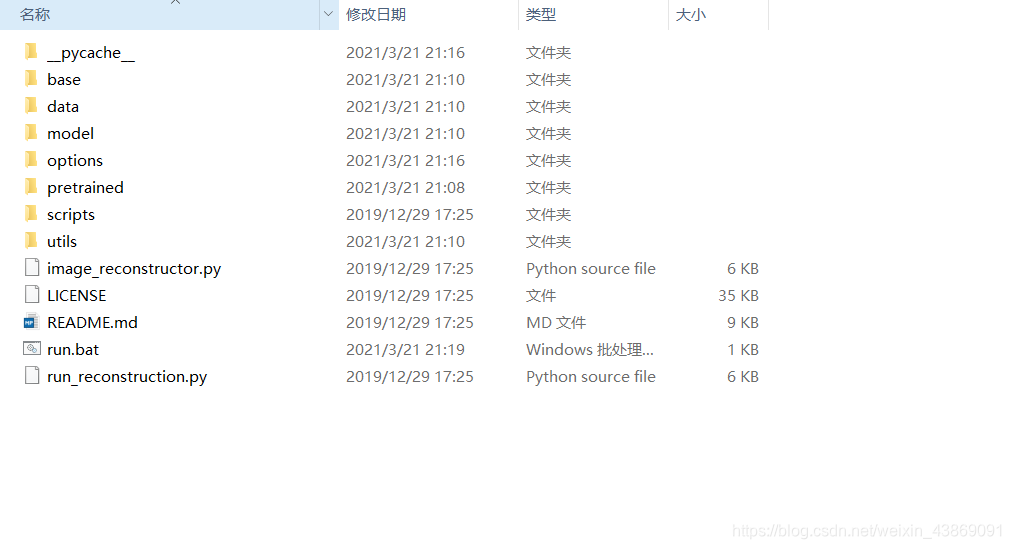 每一个文件夹对应着代码的不同部分,里面往往还会有一个README.md。
每一个文件夹对应着代码的不同部分,里面往往还会有一个README.md。 按照README中的要求,安装相关的依赖。比方说这里的reamme建议使用anaconda安装如下版本的相关的依赖包:
按照README中的要求,安装相关的依赖。比方说这里的reamme建议使用anaconda安装如下版本的相关的依赖包:
【本文地址】