| 数据挖掘 | 您所在的位置:网站首页 › fordfulkerson标号算法 › 数据挖掘 |
数据挖掘
|
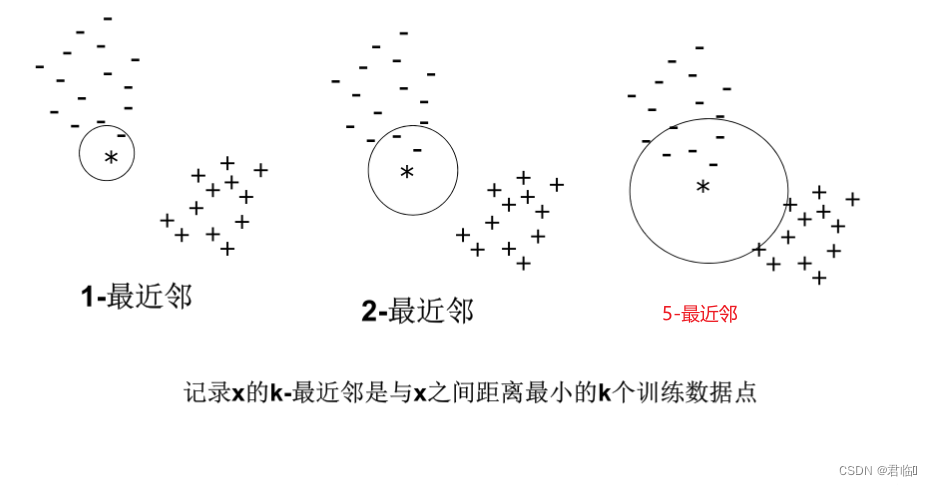
👨💻作者简介:练习时长两年半的java博主 📖个人主页:君临๑ 🎁 ps:点赞是免费的,却可以让写博客的作者开心好几天😎 文章目录 一、k-最近邻分类算法介绍 二、k-NN的特点 三、KNN算法的伪代码 四、KNN算法的python实现 一、k-最近邻分类算法介绍K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。 如图1所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在, 我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。 图一 我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别图1中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从图1中,你还能看到: 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。 于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。 步骤: 1:令k是最近邻数目,D是训练样例的集合 2: for每个测试样例z=(x ',y) do 3:计算z和每个样例(x,y) ∈ D之间的距离d(x ', x) 4:选择离z最近的k个训练样例的集合Dz包含于D 5.
6:end for 距离加权表决
(一)是一种基于实例的学习 需要一个邻近性度量来确定实例间的相似性或距离(二)不需要建立模型,但分类一个测试样例开销很大 需要计算与所有训练实例之间的距离(三)基于局部信息进行预测,对噪声非常敏感 (四)最近邻分类器可以生成任意形状的决策边界 决策树和基于规则的分类器通常是直线决策边界(五)需要适当的邻近性度量和数据预处理 防止邻近性度量被某个属性左右(六)k值的选择: 如果k太小,则对噪声点敏感如果k太大,邻域可能包含很多其他类的点(七)定标问题(规范化) 属性可能需要规范化,防止距离度量被具有很大值域的属性所左右 三、KNN算法的伪代码输入参数:k值、trainingSamples(训练数据集,M*N矩阵,M为样本数,N为属性数)、trainingLabels (训练数据集的分类标签0、1、2...,M*1矩阵) , testingSample(测试数据,1*N矩阵)输出参数: class(测试数据对应类别标签) 算法流程: 1、得到训练数据集trainingSamples的大小M,N 2、初始化Distance数组(M*1),用来存储每个训练样本与测试样本的距离。 3、对每一个训练样本trainingSamples(i,:)【 for i in range(M)】,计算其与测试样本testingSample之间的距离,存储在Distance[i]中 4、对Distance数组排升序【argsort函数】 5、取得排序前K个距离对应的序号,将序号对应的训练数据的分类标签得到赋给labs 6、得到labs数组的不重复元素,存储在数组All_labs 【unique函数】 7、得到不重复元素(数组All_labs )的个数LabNum 8、( for i in range(LabNum))对每一个不重复的分类标签All_labs[i],查找最近的k个类别标签labs中,等于All_labs[i]的有几个,将该数目作为第i类的投票数Vote[i] 9、求投票数Vote[i]的最大值所在的索引ind 10、All_labs[ind]是最大投票数对应的类别标签,即为算法输出结果class 四、KNN算法的python实现KNN_Classify_E: import numpy as np import math def KNN_Classify_E(trainingSamples,trainingLabels,testingSample,k): M=trainingSamples.shape[0] N=trainingSamples.shape[1] Distance=np.zeros((M,1)) for i in range(M): training = trainingSamples[i,:] Distance[i] = dist_E(training, testingSample) ind=np.argsort(Distance,axis=0)#axis=0 指明在列的方向排序 labs = trainingLabels[ind[:k]] labs = np.array(labs) All_labs = np.unique(labs) # labs 要从mat转为array,否则unique返回结果有问题 LabNum = All_labs.size; Vote = np.zeros((LabNum, 1)) for i in range(LabNum): vect = labs[labs == All_labs[i]] Vote[i] = vect.size ind = Vote.argmax(0) #默认 c = All_labs[ind] return c def dist_E(vect1,vect2): dist = -1 if (vect1.size != vect2.size): print('length of input vectors must agree') else: t = np.multiply((vect1 - vect2), (vect1 - vect2)) dist = math.sqrt(t.sum()) return distTestE: import numpy as np from KNN_Classify_E import * def classify_data(Tr_file_path, Tst_file_path): Tr = np.loadtxt(Tr_file_path, delimiter=",", dtype="double") Tst = np.loadtxt(Tst_file_path, delimiter=",", dtype="double") Tr = np.mat(Tr) Tst = np.mat(Tst) trAttr = Tr[:, :-1] trLabels = Tr[:, -1] tstAttr = Tst[:, :-1] tstLabels = Tst[:, -1] trAttr=normalize(trAttr) tstAttr=normalize(tstAttr) k = 3 predictlabel = np.zeros((tstLabels.size, 1)) for i in range(tstLabels.size): predictlabel[i, 0] = KNN_Classify_E(trAttr, trLabels, tstAttr[i, :], k) predict_right = predictlabel[predictlabel == tstLabels] acc = predict_right.size / predictlabel.size return acc def normalize2(Samples): meanValue = np.mean(Samples, axis=0) stdValue = np.std(Samples, axis=0) Samples2 = (Samples - meanValue)/stdValue return Samples2 def normalize(Samples): Samples = np.mat(Samples) M = Samples.shape[0] N = Samples.shape[1] Samples2 = np.mat(np.zeros((M, N))) for i in range(N): allAtr = Samples[:, i] STD = allAtr.std() MEAN = allAtr.mean() x = (allAtr - MEAN) / STD; Samples2[:, i] = x return Samples2 if __name__ == "__main__": Tr_file_path = '0data/diabets_Tr.csv' Tst_file_path = '0data/diabets_Tst.csv' acc = classify_data(Tr_file_path, Tst_file_path) print(acc)diabets_Tr:(训练数据)
diabets_Tst:(测试数据) |




【本文地址】