| h5文件格式详解及h5文件与图片文件之间的相互转换(python实现) | 您所在的位置:网站首页 › fluent打不开h5文件 › h5文件格式详解及h5文件与图片文件之间的相互转换(python实现) |
h5文件格式详解及h5文件与图片文件之间的相互转换(python实现)
|
背景:h5文件详解
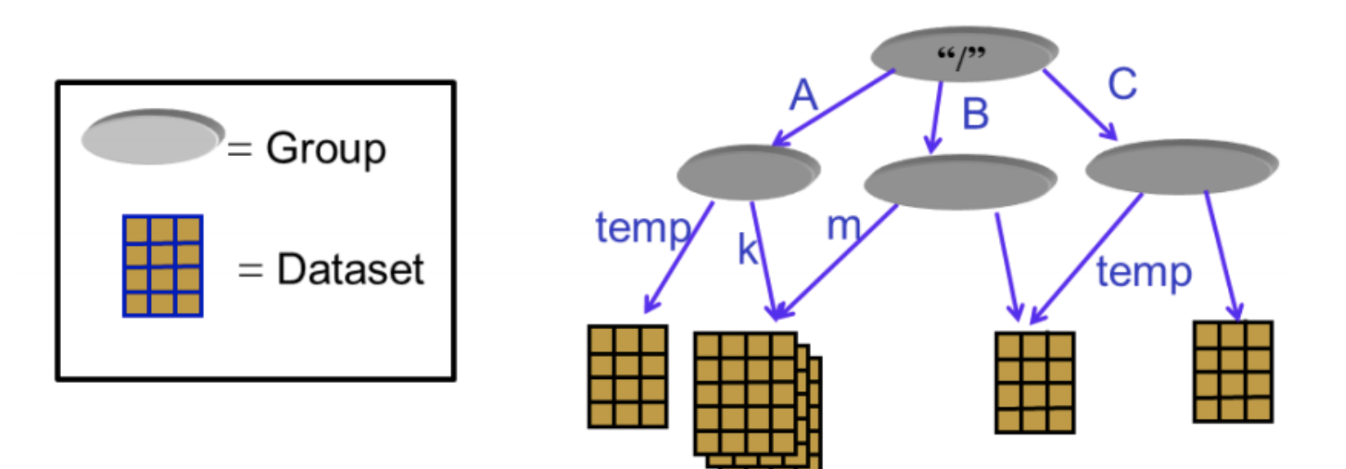
H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件。由美国超级计算中心与应用中心研发的文件格式,用以存储和组织大规模数据. H5将文件结构简化成两个主要的对象类型: 数据集dataset,就是同一类型数据的多维数组 组group,是一种容器结构,可以包含数据集和其他组,若一个文件中存放了不同种类的数据集,这些数据集的管理就用到了group! 直观的理解,可以参考我们的文件系统,不同的文件存放在不同的目录下: 目录就是hdf5文件中的group,描述了数据集DataSet的分类信息,通过group有效的将多种dataset进行管理和划分~ 文件就是hdf5文件中的dataset,表示具体的数据~ 下图就是数据集和组的关系:
简单总结为: h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集),下面来看下如何创建组和数据集。 实现:图片与h5文件的转化 一、图片转h51.先对图片进行排序,默认从1开始 from PIL import Image import os ##改变图片大小,修改图片名字 def get_smaller(path_in, name, path=None, width=64, length=64): ''' 检查文件夹是否建立,并建立文件夹 ''' if path == None: tar = os.path.exists(os.getcwd() + "\\" + name) if not tar: os.mkdir(os.getcwd() + "\\" + name) im_path = os.getcwd() + "\\" + name + "\\" else: tar = os.path.exists(path + "\\" + name) if not tar: os.mkdir(path + "\\" + name) im_path = path + "\\" + name + "\\" i = 1 list_image = os.listdir(path_in) for item in list_image: '''检查是否有图片''' tar = os.path.exists(im_path+str(i)+'.jpg') if not tar: image = Image.open(path_in+'\\'+item) smaller = image.resize((width, length), Image.ANTIALIAS) '''注意这里如果不加转换,很可能会有报错''' if not smaller.mode == "RGB": smaller = smaller.convert('RGB') smaller.save(im_path+str(i)+'.jpg') i += 1 get_smaller("E:\\桌面\\te\\001", "6")为了更方便地输入接下来的程序,我们需要有一定标准的数据集,也就是图片的大小最好是确定的 所以我们需要修改每一张图片,让其大小一定! 这里我选择把所有图片修改为64x64像素的,并重新编号存入另一个文件夹中! 这个函数的使用方法是:函数(原始图片文件夹路径,新文件夹名称) 你可以通过path关键字选择新文件夹的储存路径,也可以默认生成在当前目录 你还可以修改width和length来选择新图片的大小 总之,我们得到了最终要使用的图片,它们都在新文件夹中!
2.开始制作 import numpy as np import matplotlib.pyplot as plt import h5py import os def createData(path): pics = os.listdir(path) all_data = [] for item in pics: '''难免有图片打不开''' try: all_data.append(plt.imread(path+'\\'+item).tolist()) except Exception as pic_wrong: print(item+" pic wrong") return all_data def createSet(hf, name, tip, data): hf.create_dataset(name, data=data) t = [[tip]*len(data)] hf.create_dataset(name + '_tip', data=t) if __name__ == '__main__': hf = h5py.File('data-train.h5', 'w') all_data = createData('E:\\桌面\\te\\5') createSet(hf, 'train_set_1', 1, all_data) hf.close() 我的: import numpy as np import matplotlib.pyplot as plt import h5py import os def createData(path): pics = os.listdir(path) all_data = [] for item in pics: '''难免有图片打不开''' try: all_data.append(plt.imread(path+'\\'+item).tolist()) except Exception as pic_wrong: print(item+" pic wrong") return all_data def createSet(hf, name, data): hf.create_dataset(name, data=data) # t = [[tip]*len(data)] # hf.create_dataset(name + '_tip', data=t) if __name__ == '__main__': hf = h5py.File('data-train.h5', 'w') all_data = createData('E:\\桌面\\te\\image_3_new') createSet(hf, 'images2', all_data) hf.close()一张图片用imread之后是一个三维数组,64x64x3 个数据,64x64是像素,每个像素由red green blue三原色的值叠加来控制,函数 createdata 把 path 下所有图片的数组合并到一个列表中,得到一个4维数组,并返回,·createset 是做一个分类用的数据集,hf 是传入一个h5文件, name是在h5文件下新建的图片数据集的key;tip 是给图片数据加标签,并新生成一个以 name_tip 为key的数据集。相当于会有两个数据集,一个存图片数据,一个存图片数据的标签 一个h5文件可以print(hf.keys())来查看里面的key,每一个key对应一个数据集,一个h5文件可以有很多数据集~ h5文件的数据:(行表示图片个数,列表示刚才设置的64像素)
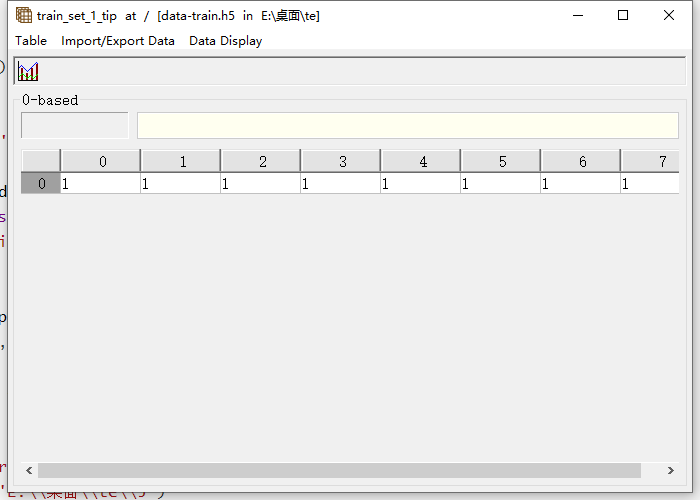
h5标签:(列表示图片个数,行表示标签内容)
reference:(1条消息) python:从零开始的图片h5py数据集制作是脑瘫啊的博客-CSDN博客h5py数据集 二、h5转图片 import cv2 import h5py import numpy as np from scipy.misc import imsave from skimage import transform hr_dataset = h5py.File('test_data.h5')['images2'] //h5文件路径 # label = h5py.File('data-train.h5')['train_set_1_tip'] lenght=len(hr_dataset) for i in range(len(hr_dataset)): y = hr_dataset[i] # x = label[i] cv2.imwrite('image_test/%s.png'%i, y) //写成png格式 # cv2.imwrite(str(i)+"0.png", x) |

【本文地址】