| float占几个字节 | 您所在的位置:网站首页 › float所占字节数 › float占几个字节 |
float占几个字节
|
下面是从网上搜集到的几个关于浮点数的例子,结果可能会因为操作系统和编译器的不同而不同。我的平台是Linux 64位,gcc版本是4.4.7,编译时使用默认选项 。 int把float换成double doublegcc编译时加上-mfpmath选项: gcc -mfpmath=387 compare.c -o compare.o float p3x = 80838.0f; float p2y = -2499.0f; double v321 = p3x * p2y; printf("%f",v321); //-202014162,not -202014160比较下面2个程序的运行时间:test.c floattest1.c float直觉是test.c里有更多的浮点数运算,运行效率会更低些,但是实际的结果是: time ./test.o real 0m1.520s user 0m1.520s sys 0m0.001s time ./test1.o //slower about 10 times real 0m11.241s user 0m11.243s sys 0m0.001s我们接下来会逐个解释上面程序的运行结果。 小数的二进制表示整数12.34可以表示的数字是 : 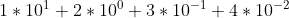
同理,101.11可以表示的数字是 : 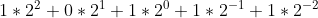
通用的,二进制串 : 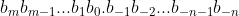
可以表示的数字是 : 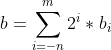
上面给出的是通过二进制小数如何转换成十进制小数,那么给出一个十进制小数,如何得出二进制小数呢?我们通过上面的公式可以很容易的看出,二进制小数乘以2,相当于小数点向右移动一位。例如,0.110101 * 2 = 1.10101。于是一直乘下去就得出110101。所以,给出一个十进制小数,对于小数部分,我们一直乘以2,将整数部分记录下来,小数部分继续乘以2,,直到小数部分为0为止。记录下的整数部分就是小数的二进制表示。 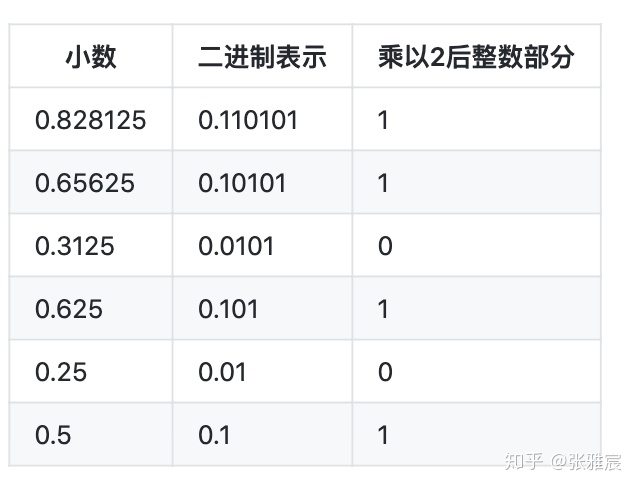
0.828125的二进制表示就是0.110101.这里很容易想到一个问题,不是所有的小数乘以2都能乘到1.0的,比如0.828125可以精确表示,但是像1/5这样的数字是不能用有限的二进制小数表示的,因为它不能像上面那样一直乘到1.这也是人们常说的浮点数的精度问题,因为二进制小数表示是无限的,我们只能退而求其次,用有限的位数表示它们。 IEEE浮点数表示利用上面的方法,5.25用二进制表示是101.01,那么这个数字直接在内存中存储可以吗?肯定不行。因为计算机不知道有小数点这么个东西。我们可以规定小数点默认在第一位,例如,1.0101,而101.01 = 0.10101 * 2^2(乘以2,相当于小数点右移)。所以,内存中起码要记录2个值,一个是10101,一个是10(2的二进制),最后通过硬件或者软件按照规定计算出存储的浮点数为1.0101 * 2^2 = 101.01 = 5.25。像整数一样,浮点数也有正负,我们同样可以用一个符号位来表示,0正1负。 国际标准IEEE 754规定了浮点数的二进制的表示,和上面描述的一样: (-1)^s表示符号位IEEE规定M表示有效数字,大于等于1,小于2。也就是我们上面说的1.0101。但是IEEE默认M的第一位是1,所以把1舍去,在计算机中只存储0101,等到读出来时再加上1。这样可以挤出1位有效位。2^E表示指数位。但是这个E是个无符号整数。所以,E的真实值必须减去一个真实值,8位减去127,11位减去1023。(可以想下为什么是127和1023?)。对于上面的例子,2^E表示为2^129,即10000001。当然E还有特殊情况,我们后面再说。对于单精度的浮点数,s、E、M分别为1、8、23位。对于双精度的浮点数,s、E、M分别为1、11、52位。 对于单精度来说,上面提到的5.25,s=0,E=10000001,M=0101000...0再比如0.1,用二进制表示为0.00011[0011]....,其中[0011]是无限循环的。转换为IEEE规定的二进制表示就是(-1)^0 * 1.1[0011] * 2^(-4 + 127)。所以s = 0,E=123,M=1[0011]。 我们可以用Float (IEEE754 Single precision 32-bit)方便的查看单精度小数的IEEE表示: 
为什么用移码表示阶码 规格化小数和非规格化小数 浮点数的舍入因为位数有限,所以浮点运算只能近似的表示实数运算。所以我们需要舍入操作。IEEE规定了4种舍入操作 : 默认的方法是找到最近的匹配(向偶数舍入)。比如1.6舍入到2,1.4舍入到1,这是找到最近的匹配。但是1.5(1 和3的中间数)舍入到哪呢?答案是向偶数舍入,即2。向0舍入。即舍入后的数字要向0靠拢。1.4/1.6/1.5 -> 0,-1.5 -> -1。(C语言中float/double向int转换使用此方式)。向下舍入。即舍入后的数字比舍入前的数字小。 1.4/1.6/1.5 -> 1,-1.5 -> -2。向上舍入。即舍入后的数字比舍入前的数字大。 1.4/1.6/1.5 -> 2,-1.5 -> --1。上面都是舍入到整数,对于小数我们也可以使用舍入到偶数。考虑舍入到小数点后2位。比如1.2349999 -> 1.23,1.23500001 -> 1.24.1.235000 -> 1.24(1.235是1.23和1.24的中间值)。 那么对于二进制呢?考虑舍入到小数点后2位。相同的,只有形如XXX...X.YY...Y100才是中间值(假设Y是精度的最后一位,那么舍入后的Y必然是0或者1,所以中间值必然有Y100这种形式)。那么,10.00011 -> 10.00,10.00110 -> 10.01,10.00100 -> 10.00(中间值)。 C语言中int/float/double的相互转换C语言中的float和double在支持IEEE浮点数的机器上对应单精度和双精度浮点数。当int/float/double互相转换时遵循以下的原则(int假设32位,float/double所占字节数在16/32/64位平台上都是32/64位): int转为float不会溢出,可能会被舍入。(因为同为32位,但是float只有23位表示有效数字,8位表示指数,1位表示符号位)。int转为double,可以保留精确的数值。(因为double有52位表示有效数字)。float转为double,可以保留精确的数值。double转为float,因为指数和有效数字位数都变小。所以可能溢出到+∞或者-∞。也可能被舍入。double/float转为int,会按照向0舍入的原则。1.999 -> 1.-1.9999 -> -1。 |
【本文地址】