| flink从入门到精通 | 您所在的位置:网站首页 › flink简介500字 › flink从入门到精通 |
flink从入门到精通
|
文章目录
flink简介名称的由来什么是flink为什么需要flink
流式计算框架比较模型 Streaming ModelAPI 形式保证机制容错机制状态管理
flink基本概念flink架构图Job ManagerJob Manager内存模型checkpointexactly-once
Task ManagerTask Manager内存模型slot与parallelism
部署部署模式Application ModePer-Job ModeSession Mode
资源提供方式
flink的数据流类型无界数据流有界数据流
编程模型状态管理Keyed StateOperator State
flink简介
名称的由来
名称由来起源于德国的科研项目,在德语中,flink 一词表示快速和灵巧。 什么是flink
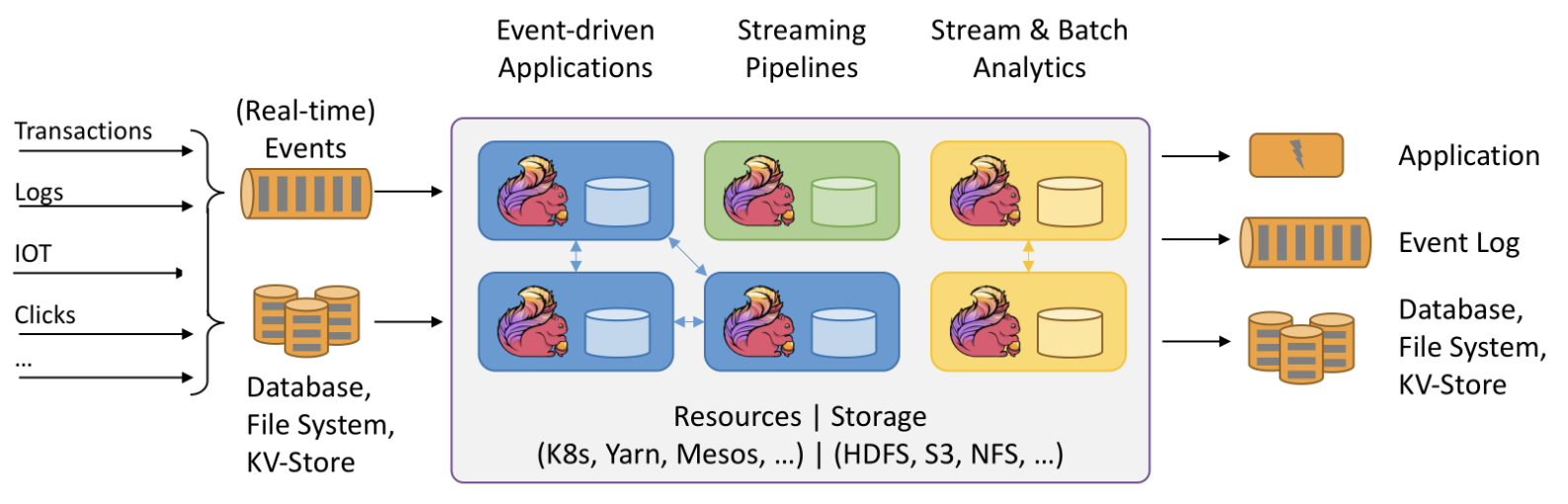
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。 flink可以将各类型数据源的数据中的各类型数据进行流式读取,并将数据实时计算处理后录入到各类型的目标数据源中。 flink的部署运行可以在k8s、Yarn、Mesos等、存储也可以使用HDFS、S3、NFS等 flink可以支持基于事件的应用处理,也可以对于流的分发处理,还可以对流或批的分析处理。 为什么需要flink在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如何进行有效的处理,成为当下大多数公司所面临的问题。随着雅虎对hadoop的开源,越来越多的大数据处理技术开始涌入人们的视线,例如目前比较流行的大数据处理引擎Apache Spark,基本上已经取代了MapReduce成为当前大数据处理的标准。但是随着数据的不断增长,新技术的不断发展,人们逐渐意识到对实时数据处理的重要性。相对于传统的数据处理模式,流式数据处理有着更高的处理效率和成本控制能力。Flink 就是近年来在开源社区不断发展的技术中的能够同时支持高吞吐、低延迟、高性能的分布式处理框架。 流式计算框架比较计算引擎的发展经历了几个过程,从第 1 代的 MapReduce,到第 2 代基于有向无环图的 Tez,第 3 代基于内存计算的 Spark,再到第 4 代的 Flink,各框架对比如下: 产品模型API保证次数容错机制状态管理延时吞吐量成熟度StromNative(数据进入立即处理)组合式(使用基础API的组合实现业务逻辑)At-least-onceRecord ACKs无Very LowLowHighTridentmirco-batching(小批处理)组合式Exectly-onceRecord ACKs基于操作的状态管理(每次操作有一个状态)LowLowHighSpark streamingmirco-batching声明式(提供封装后的高阶函数)Exectly-onceRDD Checkpoint基于DDStream的状态管理LowLowHighFlinkNative声明式Exectly-onceCheckpoint基于操作的状态管理LowHighHigh 模型 Streaming Model Naitve:数据进入立即处理;Micro-Batch:数据流入后,先划分成Micro-Batch,再处理; API 形式 组合式:操作更加基础的API操作,一步步精细控制,各组建组合定义成拓扑;声明式:提供封装后的高阶函数。封装后可提供初步的优化;可提供窗口管理、状态管理等高级操作; 保证机制 At-least-once,至少一次,出错情况下需要执行多次;Exectly-once,一次执行,保证OK; 容错机制 Record ACKs,每Tuple处理后经过ACK确认;RDD Checkpoint,基于RDD做Checkpoint。只需要重新计算特定RDD;Checkpoint:Flink的checkpoint,是一种快照(待补充详细介绍) 状态管理 基于操作的状态管理:每次操作有一个状态;基于数据的状态管理:每个数据有相应的处理状态; flink基本概念 flink架构图
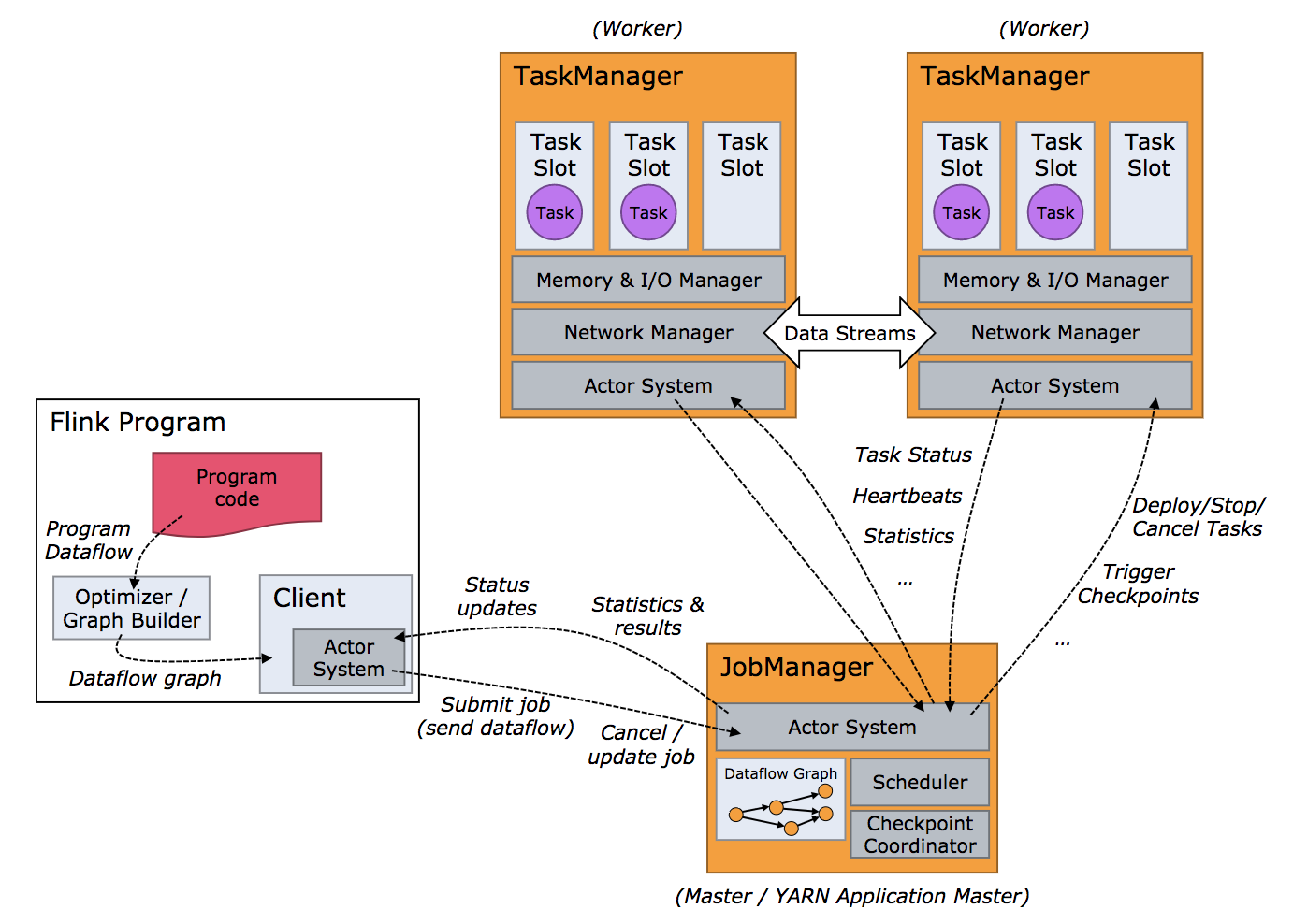
flink运行时的两个进程分别为Job Manager 和 Task Manager Job ManagerJob Manager(简称JM)主要负责调度task,协调checkpoint已经错误恢复等。当客户端将打包好的任务提交到JobManager之后,JobManager就会根据注册的TaskManager资源信息将任务分配给有资源的TaskManager,然后启动运行任务。TaskManger从JobManager获取task信息,然后使用slot资源运行task。 Job Manager内存模型 Total Process Memory:整个进程JVM所占的内存总空间。Total Flink Memory:JM程序使用的内存空间。JVM Heap:JM使用的堆内存空间。Off-Heap:JM堆外内存空间。Off-Heap Memory:调用native的方法是分配的内存空间。JVM Metaspace:类的元数据放在此空间内。JVM Overhead:留给JVM其他开销的空间。例如:Thread Stack、code cache、GC回收空间等等。
checkpoint
Total Process Memory:整个进程JVM所占的内存总空间。Total Flink Memory:JM程序使用的内存空间。JVM Heap:JM使用的堆内存空间。Off-Heap:JM堆外内存空间。Off-Heap Memory:调用native的方法是分配的内存空间。JVM Metaspace:类的元数据放在此空间内。JVM Overhead:留给JVM其他开销的空间。例如:Thread Stack、code cache、GC回收空间等等。
checkpoint
为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。 Checkpoint 其他的属性包括: 检查点存储:您可以设置检查点快照持久化的位置。默认情况下,Flink 将使用 JobManager 的堆。对于生产部署,建议改用持久文件系统。有关作业范围和集群范围配置的可用选项的更多详细信息,请参阅检查点存储。精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中传入一个模式来选择使用两种保证等级中的哪一种。对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。checkpoints 之间的最小时间:该属性定义在 checkpoint 之间需要多久的时间,以确保流应用在 checkpoint 之间有足够的进展。如果值设置为了 5000,无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。不过允许多个 checkpoint 并行进行是可行的,对于有确定的处理延迟(例如某方法所调用比较耗时的外部服务),但是仍然想进行频繁的 checkpoint 去最小化故障后重跑的 pipelines 来说,是有意义的。检查点外化存储(externalized checkpoints): 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。更多的细节请看 Externalized checkpoints 的部署文档。在 checkpoint 出错时使 task 失败或者继续进行 task:他决定了在 task checkpoint 的过程中发生错误时,是否使 task 也失败,使失败是默认的行为。 或者禁用它时,这个任务将会简单的把 checkpoint 错误信息报告给 checkpoint coordinator 并继续运行。优先从 checkpoint 恢复(prefer checkpoint for recovery):该属性确定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,这可以潜在地减少恢复时间(checkpoint 恢复比 savepoint 恢复更快)。未对齐的检查点:您可以启用未对齐的检查点以大大减少背压下的检查点时间。仅适用于exactly-once检查点且并发检查点数为 1。 exactly-once实现端到端的exactly-once语义需要以下条件: 内部保证 —— checkpointsource 端 —— 支持数据重放sink 端 —— 从故障恢复时,数据不会重复写入外部系统(幂等写入、事务写入)flink checkpoint在实现exactly-once语义时采用两阶段提交。 简单讲两阶段提交可以分为一下几个步骤。 预提交:根据checkpoint barrier每个算子以及source、sink做第一次的提交(预提交),记录checkpoint。等待预提交完成:等待所有预提交完成。但任何一个预提交失败,豆浆使link从最近一次的checkpoint重新开始。提交:所有预提交完成后发起提交请求,所有提交均需要成功,如果失败flink也会从最近一次checkpoint重新开始。详细的两阶段提交可以参照此文章。 Task Manager Task Manager内存模型 Total Process Memory:整个进程JVM所占的内存总空间。Total Flink Memory:TM程序使用的内存空间。JVM Heap:TM使用的堆内存空间。Framework Heap:框架自身使用的内存空间。Task Heap:任务使用的内存空间。Off-Heap Memory:TM堆外内存空间。Managed Memory:由Flink直接管理的off-heap内存,它主要用于排序、哈希表、中间结果缓存、RocksDB的backend。其实它是Task Executor管理的off-heap内存。Direct Memory:直接内存,是JVM在堆外直接向系统申请的内存。Framework Off-Heap:框架自身使用的堆外内存。Task Off-Heap:Task使用的堆外内存。Network:用于Task之间进行数据交换时使用的内存,其中数据交换方式包括内存与网络两种形式。JVM Metaspace:类的元数据放在此空间内。JVM Overhead:留给JVM其他开销的空间。例如:Thread Stack、code cache、GC回收空间等等。
slot与parallelism
Total Process Memory:整个进程JVM所占的内存总空间。Total Flink Memory:TM程序使用的内存空间。JVM Heap:TM使用的堆内存空间。Framework Heap:框架自身使用的内存空间。Task Heap:任务使用的内存空间。Off-Heap Memory:TM堆外内存空间。Managed Memory:由Flink直接管理的off-heap内存,它主要用于排序、哈希表、中间结果缓存、RocksDB的backend。其实它是Task Executor管理的off-heap内存。Direct Memory:直接内存,是JVM在堆外直接向系统申请的内存。Framework Off-Heap:框架自身使用的堆外内存。Task Off-Heap:Task使用的堆外内存。Network:用于Task之间进行数据交换时使用的内存,其中数据交换方式包括内存与网络两种形式。JVM Metaspace:类的元数据放在此空间内。JVM Overhead:留给JVM其他开销的空间。例如:Thread Stack、code cache、GC回收空间等等。
slot与parallelism
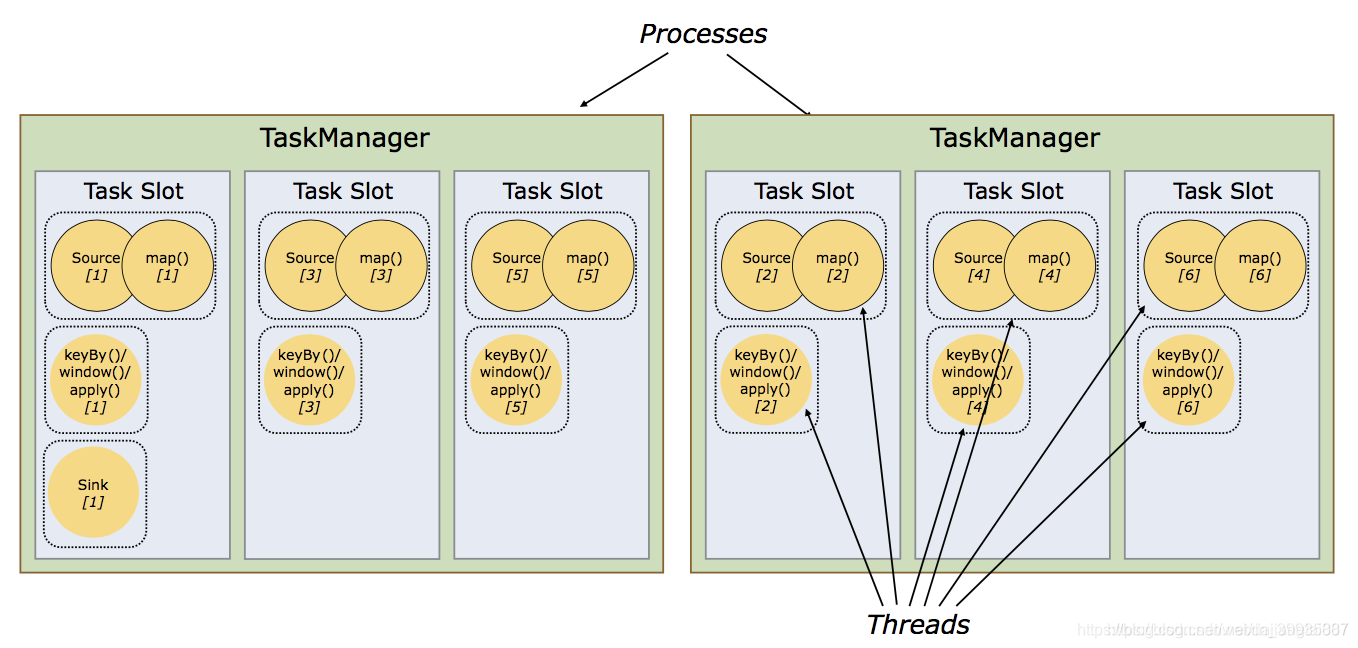
首先我们要知道什么是parallelism,parallelism就是并行度的意思,是同样一个task的最大并发数。以上是一个任务的graph,我们可以看到graph里描述所有算子的parallelism均为1. 当task在TM中执行的时候,需要并发执行时,每个task中的算子将根据parallelism数生成指定的subtask,每个subtask将在一个solt中执行,切上下游算子尽可能的在一个slot中执行,以免减少网络和线程间的通信。具体实例如下图。
flink的部署分为部署模式以及资源提供方式 部署模式Flink 可以通过以下三种方式之一执行应用程序: 在应用(application)模式下在 Per-Job 模式下在会话(session)模式下
flink以应用形式启动,所有用户可以在上面提交任务,如果此集群宕机,所有任务将失败。大多数生产环境不采用此模式。 Per-Job Mode此模式下,每个任务会在一个完整的鸡群中执行,包括JM和TM,资源将根据配置进行分配。任务之间不收影响。 Session Mode此模式下,会预先启动一个完整的flink集群,并且会将预先资源分配给所有的session。不同的session提交任务时,均在此集群中运行,但使用的资源数不能超过预先分配的资源数。此场景在多租户场景用于限制资源使用。 资源提供方式flink支持以下四种资源提供方式: StandaloneNative KubernetesYARNMesos较为常用的为Native Kubernetes和YARN,本文不做详细的描述。 flink的数据流类型Flink中的数据主要分为两类:有界数据流(Bounded streams)和无界数据流(Unbounded streams)。 无界数据流顾名思义,无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。 有界数据流相对而言,有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理:
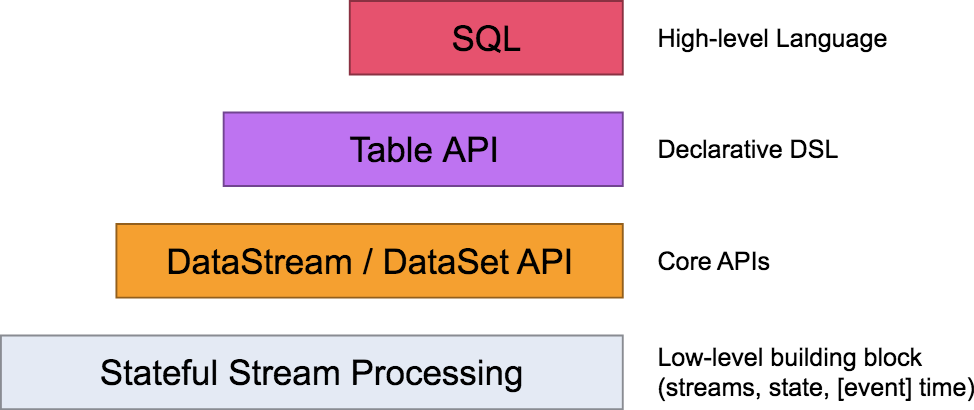
需要注意的是,我们一般所说的数据流是指数据集,而流数据则是指数据流中的数据。 编程模型在Flink,编程模型的抽象层级主要分为以下4种,越往下抽象度越低,编程越复杂,灵活度越高。
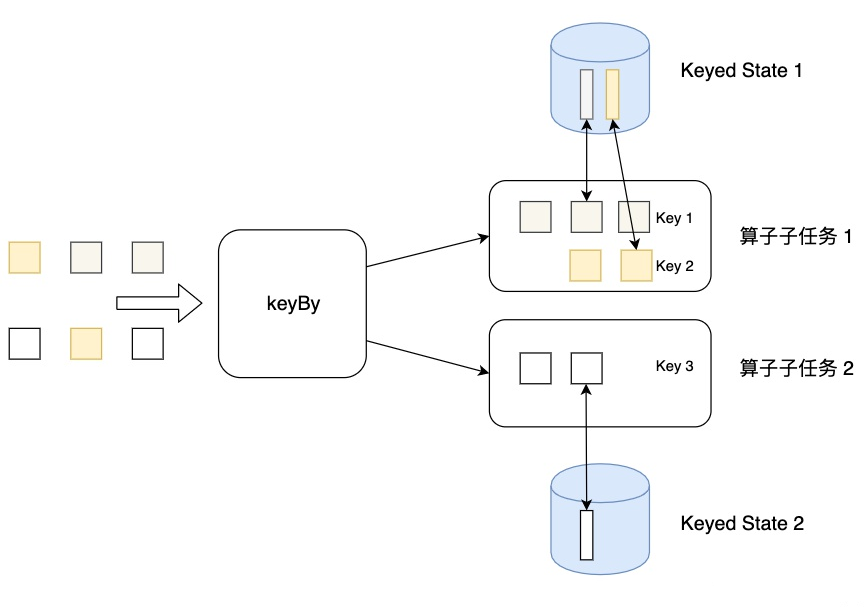
这里先不一一介绍,后续会做详细说明。这4层中,一般用于开发的是第三层,即DataStrem/DataSetAPI。用户可以使用DataStream API处理无界数据流,使用DataSet API处理有界数据流。同时这两个API都提供了各种各样的接口来处理数据。例如常见的map、filter、flatMap等等,而且支持python,scala,java等编程语言。 状态管理Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。 两者的具体区别有: 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当我们横向伸缩,或者说我们修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。只讲一下Managed State。 Managed State分为两种类型:Keyed State和Operator State。 Keyed StateFlink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。 需要注意的是键控状态只能在 KeyedStream 上进行使用,可以通过 stream.keyBy(...) 来得到 KeyedStream 。
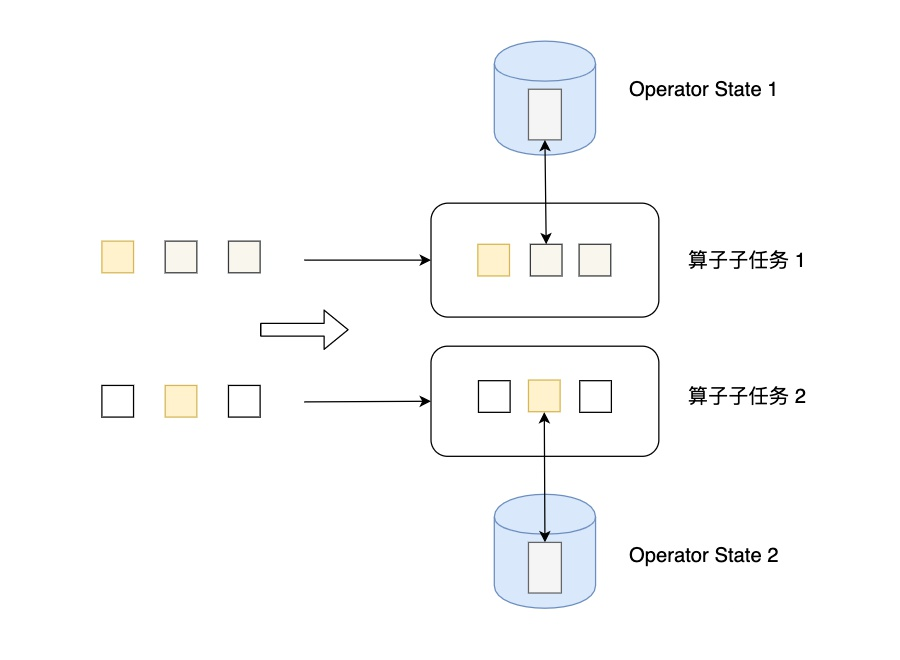
Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State): ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使用 AggregatingState 代替。MapState:维护 Map 类型的状态。 Operator StateOperator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。 算子状态不能由相同或不同算子的另一个实例访问。
Flink为算子状态提供三种基本数据结构: ListState:存储列表类型的状态。UnionListState:存储列表类型的状态,与 ListState 的区别在于:如果并行度发生变化,ListState 会将该算子的所有并发的状态实例进行汇总,然后均分给新的 Task;而 UnionListState 只是将所有并发的状态实例汇总起来,具体的划分行为则由用户进行定义。BroadcastState:用于广播的算子状态。如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。 |


【本文地址】