| countifs、rank等统计函数详解:如何在Excel、Python、SQL中实现 | 您所在的位置:网站首页 › excel里rank函数怎么计算 › countifs、rank等统计函数详解:如何在Excel、Python、SQL中实现 |
countifs、rank等统计函数详解:如何在Excel、Python、SQL中实现
|
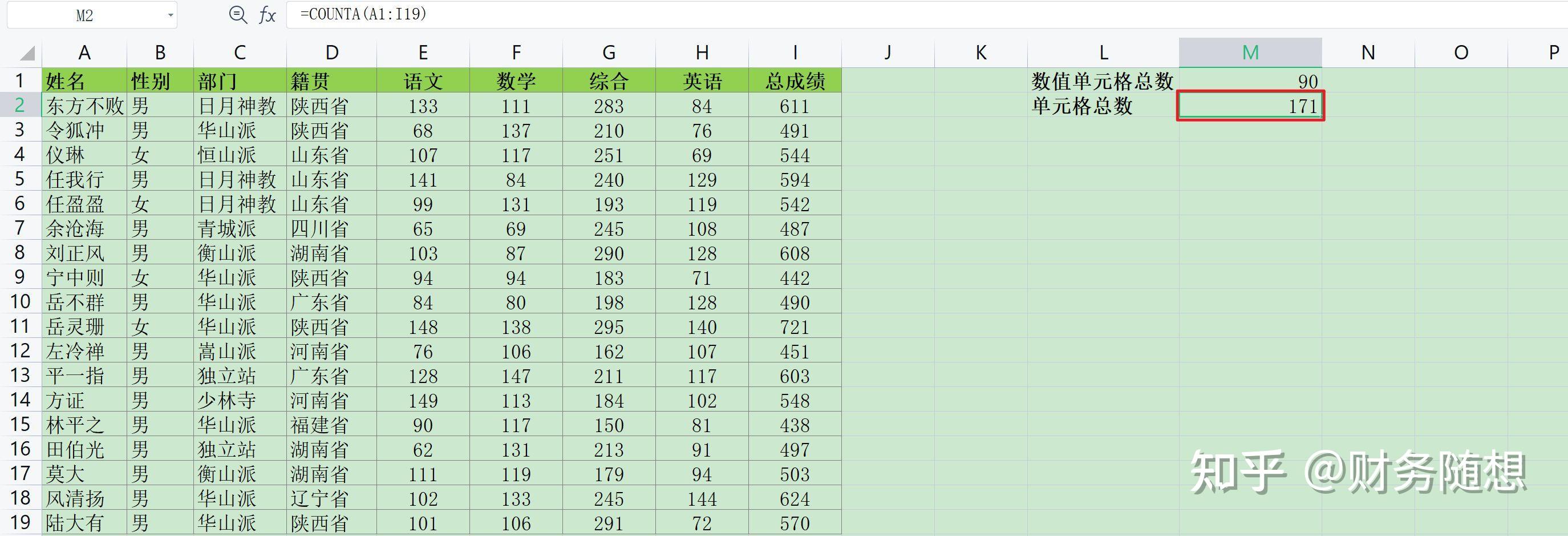
前面已经介绍了最重要的求和sum,sumifs,sumproduct等函数,统计类函数还有很多,比如计数函数count,countb,countifs,求平均值函数average,avergeifs,排名函数rank.eq,rank.avg最大值max,maxifs,最小值min,minifs,百分位排名函数percentrank.inc,分位值函数percentile.inc,筛选条件下分类汇总函数subtotal,本文都会做出讲解并按实例进行演示: 问题1:提取成绩单表格里是数值的单元格个数,和非空的单元格总的个数 问题2:提取全部总成绩的最大值、最小值,以及华山派总成绩的最大值、最小值 问题3:按总成绩分数多少进行排名 问题4:分别求出各门派的人数,各门派性别为男的人数 问题5:求出所有成绩的平均值,以及求出按门派分类总成绩的平均值 问题6:求出总成绩在90%分位上的值,以及求出每个人成绩排名的分位值 Excel实现:问题1:提取成绩单表格里是数值的单元格个数,以及非空单元格总的个数
只统计数值单元格公式 =COUNT(A1:I19) 统计包括文本单元格公式=COUNTA(A1:I19)
说明: COUNT(value1, [value2], ...),函如其名count英文本身就是计数的意思,所以这个函数计算包含数字的单元格个数以及参数列表中数字的个数 COUNTA(value1, [value2], ...) 这里面count后的a是英文all的意思,即COUNTA函数计算包含任何类型的信息(包括错误值和空文本 (""))的单元格 类似的函数还有一个COUNTBLANK,即只统计指定区间内单元格为空值的个数
问题2:提取全部总成绩的最大值、最小值,以及华山派总成绩的最大值、最小值 最大值=MAX(I2:I19) 最小值=MIN(I1:I19)
MAX(number1, [number2], ...) 函如其名,返回一组值中的最大值,最多255个参数,和sum函数参数个数一样 参数可以是数字或者是包含数字的名称、数组或引用。 例如:把总成绩列命名为总成绩
然后MAX的参数直接引用总成绩=MAX(总成绩)
结果一样 逻辑值和直接键入到参数列表中代表数字的文本被计算在内。 如果参数是一个数组或引用,则只使用其中的数字,数组或引用中的空白单元格、逻辑值或文本将被忽略。 比如把岳灵珊的成绩改成文本“我想你”,则MAX计算过程自动忽略这个文本
如果参数不包含任何数字,则 MAX 返回 0,比如以姓名列作为MAX的参数
如果参数为错误值或为不能转换为数字的文本,将会导致错误 比如把岳灵珊成绩改为#N/A错误,则函数返回错误
MIN的函数用法同MAX一样,只是取最小而已 各门派总成绩的最大值=MAXIFS(I:I,C:C,K2) 各门派总成绩的最小值=MINIFS(I:I,C:C,K2)
MAXIFS(max_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...) 这个函数用法同SUMIFS类似,MAXIFS返回一组给定条件或标准指定的单元格中的最大值, MINIFS则返回一组给定条件或标准指定的单元格中的最小值 问题3:按总成绩分数多少进行排名 公式如下: =RANK(I2,I:I,0) =RANK.EQ(I2,I:I,0) =RANK.AVG(I2,I:I,0)
我们可以看到,一共有三个排名函数,rank,rank.eq,rank.avg 其中RANK函数最初的时候只有一个,后面两个是从第一个函数进行拆分而来的,RANK.EQ与RANK是全继承关系,也就是功能完全一样,所以我们这里只介绍后面两个就可以 RANK.EQ(number,ref,[order]) rank英文是排序的意思,EQ是单词equal相等的缩写,这个函数返回一列数字的数字排位,其大小与列表中其他值相关;如果多个值具有相同的排位,则返回该组值的最高排位,也就说比如两个人并列第一名,则两个人的排名都是第1,后面直接从第3名往下接,而RANK.AVG的排法在这里会把两个人都弄成1.5名,即(1+2)/2 =1.5 名,如果是三个人并列第一,则是(1+2+3)/3=2名
第一个参数是要找到排位的数字,这里面即是每个人的总成绩单元格 第二个参数是第一个参数所在列表的区域,Ref是单词reference引用的缩写 第三个参数是排序类型,默认或者填0为倒序,其他数字都是升序排列 RANK.AVG函数参数与RANK.EQ相同 如果把第三参数改为1,则变升序排列
问题4:分别求出各门派的人数,各门派性别为男的人数 各门派的人数=COUNTIFS(C:C,K2)
各门派性别为男的人数=COUNTIFS(C:C,K2,B:B,"男")
其实还是有COUNTIF这个条件函数的,个人建议直接PASS掉这个COUNTIF COUNTIFS(criteria_range1, criteria1, [criteria_range2, criteria2],…) 用法和SUMIFS,MAXIFS函数都类似,这个函数返回统计满足所有条件的次数 最少两个条件,第一个是条件区域,第二个是条件,可以使用通配符进行匹配 问题5:求出所有成绩的平均值,以及求出按门派分类总成绩的平均值 =AVERAGE(I1:I19) 或者 =AVERAGE(总成绩)(前面已经定义列区域名称)
AVERAGE(number1, [number2], ...) 单词本身就是平均值的意思,函如其名,返回参数平均值 这个函数只计算里面是数值的平均值,比如在最下面加一个文本我想你,则不计算
这个函数也不计算布尔值,如果要计算文本单元格在内的所有单元格平均值则要用=AVERAGEA(I1:I20)
AVERAGEA 比AVERAGE函数多了一个字母,A代表ALL的意思 求出按门派分类总成绩的平均值=AVERAGEIFS(I:I,C:C,K2)
问题6:求出总成绩在90%分位上的值,以及求出每个人成绩排名的分位值 求出总成绩在90%分位上的值:=PERCENTILE(I2:I19,0.9)
这个实际意义就是说只要成绩超过614.9分,就可以超过成绩单里面90%的人了 PERCENTILE(array,k),percentile单词的意思是百分位数,也就是指排在某个百分比位数的值是多少 这个函数可以决定检查得分高于第某个百分点的候选人。 第一个参数是定义相对位置的数组或数据区域。 第二个参数0到1之间的百分点值,包含 0 和 1。 后面又衍生分裂为两个新函数,percentile.inc 和 percentile.exc, inc是include的缩写,exc是exclude缩写 percentile.inc完整地继承了percentile函数功能,percentile.exc,函数的第二个参数不能为0或者100% 例:考多少分可以超过100%(也就是最高分)的人:=PERCENTILE(I2:I19,1)
但是如果用:=PERCENTILE.EXC(I2:I19,1)就会报错
求出每个人成绩排名的分位值:=PERCENTRANK.INC($I$2:$I$19,I2)
这个函数也有.exc的变体:=PERCENTRANK.EXC($I$2:$I$19,I2)这里排名百位分没有了1和0的值
我们以前者为准,这个百分位排名函数也可以用rank间接计算出来 =(K2-1)/(COUNT($K$2:$K$19)-1)
略有一点差异,影响不大 PERCENTRANK.INC(array,x,[significance]),percent是百分比,rank是排名,即百分比排名函数,将某个数值在数据集中的排位作为数据集的百分比值返回,此处的百分比值的范围为0 到1(含 0 和 1)。 第一个参数是定义相对位置的数值数组或数值数据区域 第二个参数是需要得到其排位的值 第三个参数可选。 用于标识返回的百分比值的有效位数的值,如果省略,则PERCENTRANK.INC使用 3 位小数 附加:Excel筛选条件下进行求和,计数,最大值,最小值 先筛选部门华山派,然后在最下方单元格输入公式=SUBTOTAL(9,I2:I19)即可求出筛选状态下的和
如果用SUM公式求和,则会返回所有单元格包括没筛选部分的成绩之和
SUBTOTAL(function_num,ref1,[ref2],...) 第一个参数是函数类型,输入数字 1-11 或 101-111,用于指定要为分类汇总使用的函数。 如果使用 1-11,将包括手动隐藏的行,如果使用 101-111,则排除手动隐藏的行;始终排除已筛选掉的单元格。 Function_num(包括隐藏的行) Function_num(忽略隐藏的行) 函数 1 101 AVERAGE 2 102 COUNT 3 103 COUNTA 4 104 MAX 5 105 MIN 6 106 PRODUCT 7 107 STDEV 8 108 STDEVP 9 109 SUM 10 110 VAR 11 111 VARP 第二个参数是引用的数据区域 例:我们筛选华山派求和人数=SUBTOTAL(2,I2:I19)
此时我们将令狐冲和岳灵珊两个人手动隐藏(非筛选隐藏)
此时我们得到的值里不包括隐藏项,所以这个第一参数官方文档说明是不是有些问题? 其他的一些功能:求最大值
求所有值相乘
Python实现: 问题1:提取成绩单表格里是数值的单元格个数,和非空的单元格总的个数 统计非空的单元格总的个数: import pandas as pd df = pd.read_excel("c:/study_note/xiao_subtotal.xlsx",sheet_name = "成绩单") df.count().sum()+df.shape[1]
因为pandas通过count函数并不统计第一行,列首是作为列索引字段的
统计表格里是数值的单元格个数: df.iloc[:,[4,5,6,7,8]].count().sum() 或者 df.loc[:,"语文":"总成绩"].count().sum()
问题2:提取全部总成绩的最大值、最小值,以及华山派总成绩的最大值、最小值 df["总成绩"].max() df["总成绩"].min()
df.groupby("部门")["总成绩"].max()["华山派"] df.groupby("部门")["总成绩"].min()["华山派"]
问题3:按总成绩分数多少进行排名 倒序排名: df["总成绩提名"] =df["总成绩"].rank(ascending= False,method="min")
相同名次下平均取值: df["总成绩提名"] =df["总成绩"].rank(ascending= False,method="average")
升序排列 df["总成绩提名"] =df["总成绩"].rank(ascending= True,method="min")
问题4:分别求出各门派的人数,各门派性别为男的人数 df.groupby("部门")["部门"].count()
df[df["性别"] == "男"].groupby("部门")["部门"].count()
或者用个麻烦点的方法: a = df.groupby(["部门","性别"]).count() a = a.reset_index().set_index(["性别","部门"]) a["姓名"].loc["男",:]
问题5:求出所有成绩的平均值,以及求出按门派分类总成绩的平均值 df["总成绩"].mean()
df.groupby("部门")["总成绩"].mean()
问题6:求出总成绩在90%分位上的值,以及求出每个人成绩排名的分位值 df["总成绩"].quantile(0.9)
quantile的单词是分位点的意思 求出每个人成绩排名的分位值: df["成绩排名"]= df["总成绩"].rank(ascending = True, method="min") df["百分位排名"] = (df["成绩排名"]-1)/(df["总成绩"].count()-1)
SQL实现: 1提取成绩单表格里是数值的单元格个数,和非空的单元格总的个数 SELECTcount(姓名) +count(性别)+ count(部门)+count(籍贯)+count(语文)+count(数学)+count(综合)+count(英语) +count(总成绩) AS"单元格数"FROM score ;
这个是不包括列首的单元格数,只要再此基础上加字段数即可
提取成绩单表格里是数值的单元格个数 SELECTcount(语文)+count(数学)+count(综合)+count(英语)+count(总成绩) AS"单元格数"FROM score ;
问题2:提取全部总成绩的最大值、最小值,以及华山派总成绩的最大值、最小值 SELECTmax(总成绩) AS"最大值"FROM score ;
SELECTmin(总成绩) AS"最大值"FROM score ;
SELECTmax(总成绩) AS"最大值"FROM score WHERE 部门='华山派';
SELECTmin(总成绩) AS"最大值"FROM score WHERE 部门='华山派';
问题3:按总成绩分数多少进行排名 降序排名: SELECT *,rank() OVER (ORDERBY 总成绩 DESC) AS"分数排名"FROM score;
升序排名: SELECT *,rank() OVER (ORDERBY 总成绩) AS"分数排名"FROM score;
其中SQL排名还有两种: SELECT *,ROW_NUMBER() OVER (ORDERBY 总成绩 DESC) AS"分数排名"FROM score; 这种排名两个值相同时,并不会显示两个相同的并列名次,而是依然按顺序号进行往下排 比如把平一指的成绩也改为608: UPDATE score SET 总成绩 = '608'WHERE 姓名='平一指';
可以看到第4名和第5名的成绩是一样的,但是还是按顺序进行排序 SELECT *,DENSE_RANK() OVER (ORDERBY 总成绩 DESC) AS"分数排名"FROM score; 这种形式出现两个并列排名后面依然会按顺序进行往下排,比如两个并列第4名,后面依旧接第5名
问题4:分别求出各门派的人数,各门派性别为男的人数 SELECT 部门,count(姓名) AS 部门人数 FROM score GROUPBY 部门;
SELECT 部门,count(姓名) AS 部门人数 FROM score WHERE 性别 ='男'GROUPBY 部门 ;
问题5:求出所有成绩的平均值,以及求出按门派分类总成绩的平均值 SELECTavg(总成绩) AS 平均值 FROM score ;
SELECT 部门,avg(总成绩) AS 平均值 FROM score GROUPBY 部门;
问题6:求出总成绩在90%分位上的值,以及求出每个人成绩排名的分位值 第一个问题没找到解决办法,后面找到再补 求出每个人成绩排名的分位值: CREATETABLE temp4( 姓名 VARCHAR(10), 排名 INT ); INSERTINTO temp4 SELECT 姓名,rank() OVER (ORDERBY 总成绩 ) AS 排名 FROM score; SELECT 姓名,(排名-1)/17AS 百分位排名 FROM temp4 ORDERBY 百分位排名 DESC;
Tableau实现: 问题1:提取成绩单表格里是数值的单元格个数,和非空的单元格总的个数 可以像SQL一样用COUNT函数求出,这里没必要用Tableau来实现,焉用牛刀? 问题2:提取全部总成绩的最大值、最小值,以及华山派总成绩的最大值、最小值 把总成绩字段移到文本上面,然后点小三角下拉列表,找到最大值和最小值
把总成绩字段再复制一个,然后筛选为显示最小值,把这两个字段同时拖到左下角度量值里面,如下:
问题3:按总成绩分数多少进行排名 创建成绩排名字段,输入公式RANK(SUM([总成绩]),'desc') 然后将成绩排名字段拖到左下角度量值里面
问题4:分别求出各门派的人数,各门派性别为男的人数 一个取巧的办法,把部门拖到行空格里,然后把姓名拖到标记里面的详细信息,可以看到一个小方块代表一个人
或者把姓名拖到文本里,显示每个门派包括哪些人,
以上两个方法都不能直接计数,正确方法如下: 创建计算字段,命名为部门人数,输入公式COUNT([部门])
把部门人数字段拖到文本上面即可求出各门派的人数
把性别字段拖到筛选器下面,然后筛选性别为男,即可求出各门派性别为男的人数
问题5:求出所有成绩的平均值,以及求出按门派分类总成绩的平均值 直接在字段总成绩上面筛选度量-平均值就可以,拖到文本上面
把部门字段拖到行空格处,即可显示各部门平均值
问题6:求出总成绩在90%分位上的值,以及求出每个人成绩排名的分位值 直接筛选总成绩字段-度量-百分位-90即可得到在90%分位上的值
创建计算字段百分位数,输入公式:RANK_PERCENTILE(SUM([总成绩]),'asc')
然后将字段拖到左下角度量那里即可
觉得有用点个赞,一起交流一起学习! |














































































【本文地址】