| 聊聊Excel解析:如何处理百万行EXCEL文件 | 您所在的位置:网站首页 › excel表格怎么缩小文件 › 聊聊Excel解析:如何处理百万行EXCEL文件 |
聊聊Excel解析:如何处理百万行EXCEL文件
|
xcel表格在后台管理系统中使用非常广泛,多用来进行批量配置、数据导出工作。在日常开发中,我们也免不了进行Excel数据处理。 那么,如何恰当地处理数据量庞大的Excel文件,避免内存溢出问题?本文将对比分析业界主流的Excel解析技术,并给出解决方案。 如果这是您第一次接触Excel解析,建议您从第二章了解本文基础概念;如果您已经对POI有所了解,请跳转第三章阅读本文重点内容。 二、基础篇-POI说到Excel读写,就离不开这个圈子的的老大哥——POI。 
Apache POI是一款Apache软件基金会用Java编写的免费开源的跨平台的 Java API,全称Poor Obfuscation Implementation,“简洁版的模糊实现”。它支持我们用Java语言和包括Word、Excel、PowerPoint、Visio在内的所有Microsoft Office文档交互,进行数据读写和修改操作。 (1)“糟糕”的电子表格在POI中,每种文档都有一个与之对应的文档格式,如97-2003版本的Excel文件(.xls),文档格式为HSSF——Horrible SpreadSheet Format,意为“糟糕的电子表格格式”。虽然Apache幽默而谦虚地将自己的API冠以“糟糕”之名,不过这确实是一款全面而强大的API。 以下是部分“糟糕”的POI文档格式,包括Excel、Word等: Office文档对应POI格式Excel (.xls)HSSF (Horrible SpreadSheet Format)Word (.doc)HWPF (Horrible Word Processor Format)Visio (.vsd)HDGF (Horrible DiaGram Format)PowerPoint(.ppt)HSLF(Horrible Slide Layout Format) (2)OOXML简介微软在Office 2007版本推出了基于XML的技术规范:Office Open XML,简称OOXML。不同于老版本的二进制存储,在新规范下,所有Office文档都使用了XML格式书写,并使用ZIP格式进行压缩存储,大大提升了规范性,也提高了压缩率,缩小了文件体积,同时支持向后兼容。简单来说,OOXML定义了如何用一系列的XML文件来表示Office文档。 Xlsx文件的本质是XML让我们看看一个采用OOML标准的Xlsx文件的构成。我们右键点击一个Xlsx文件,可以发现它可以被ZIP解压工具解压(或直接修改扩展名为.zip后解压),这说明:Xlsx文件是用ZIP格式压缩的。解压后,可以看到如下目录格式: 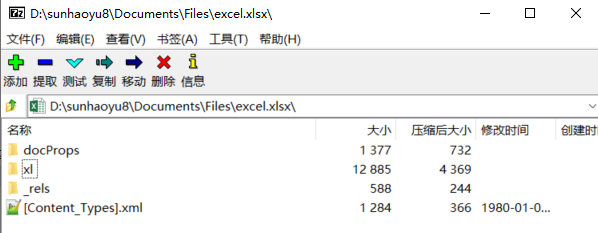
打开其中的“/xl”目录,这是这个Excel的主要结构信息: 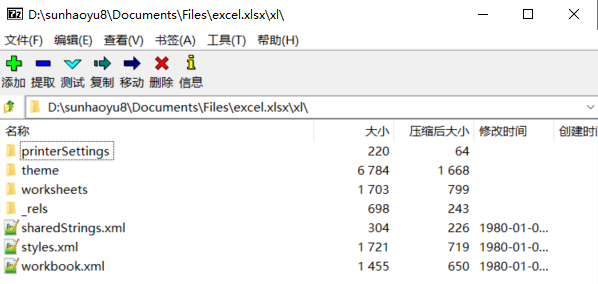
其中workbook.xml存储了整个Excel工作簿的结构,包含了几张sheet表单,而每张表单结构存储在/wooksheets文件夹中。styles.xml存放单元格的格式信息,/theme文件夹存放一些预定义的字体、颜色等数据。为了减少压缩体积,表单中所有的字符数据被统一存放在sharedStrings.xml中。经过分析不难发现,Xlsx文件的主体数据都以XML格式书写。 XSSF格式为了支持新标准的Office文档,POI也推出了一套兼容OOXML标准的API,称作poi-ooxml。如Excel 2007文件(.xlsx)对应的POI文档格式为XSSF(XML SpreadSheet Format)。 以下是部分OOXML文档格式: Office文档对应POI格式Excel (.xlsx)XSSF (XML SpreadSheet Format)Word (.docx)XWPF (XML Word Processor Format)Visio (.vsdx)XDGF (XML DiaGram Format)PowerPoint (.pptx)XSLF (XML Slide Layout Format) (3)UserModel在POI中为我们提供了两种解析Excel的模型,UserModel(用户模型)和EventModel(事件模型) 。两种解析模式都可以处理Excel文件,但解析方式、处理效率、内存占用量都不尽相同。最简单和实用的当属UserModel。 UserModel & DOM解析用户模型定义了如下接口: Workbook-工作簿,对应一个Excel文档。根据版本不同,有HSSFWorkbook、XSSFWorkbook等类。 Sheet-表单,一个Excel中的若干个表单,同样有HSSFSheet、XSSFSheet等类。 Row-行,一个表单由若干行组成,同样有HSSFRow、XSSFRow等类。 Cell-单元格,一个行由若干单元格组成,同样有HSSFCell、XSSFCell等类。 
可以看到,用户模型十分贴合Excel用户的习惯,易于理解,就像我们打开一个Excel表格一样。同时用户模型提供了丰富的API,可以支持我们完成和Excel中一样的操作,如创建表单、创建行、获取表的行数、获取行的列数、读写单元格的值等。 为什么UserModel支持我们进行如此丰富的操作?因为在UserModel中,Excel中的所有XML节点都被解析成了一棵DOM树,整棵DOM树都被加载进内存,因此可以进行方便地对每个XML节点进行随机访问。 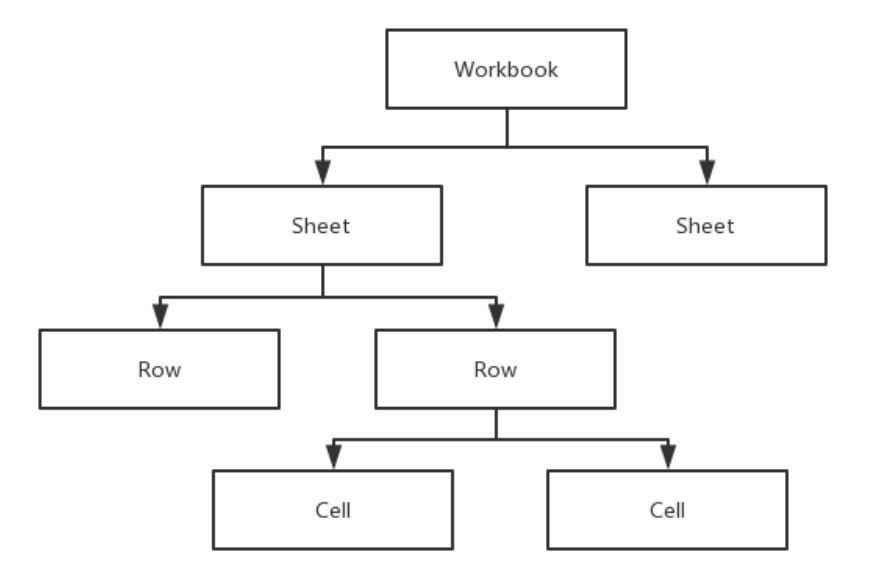 UserModel数据转换
UserModel数据转换
了解了用户模型,我们就可以直接使用其API进行各种Excel操作。当然,更方便的办法是使用用户模型将一个Excel文件转化成我们想要的Java数据结构,更好地进行数据处理。 我们很容易想到关系型数据库——因为二者的实质是一样的。类比数据库的数据表,我们的思路就有了: 将一个Sheet看作表头和数据两部分,这二者分别包含表的结构和表的数据。 对表头(第一行),校验表头信息是否和实体类的定义的属性匹配。 对数据(剩余行),从上向下遍历每一个Row,将每一行转化为一个对象,每一列作为该对象的一个属性,从而得到一个对象列表,该列表包含Excel中的所有数据。 接下来我们就可以按照我们的需求处理我们的数据了,如果想把操作后的数据写回Excel,也是一样的逻辑。 使用UserModel让我们看看如何使用UserModel读取Excel文件。此处使用POI 4.0.0版本,首先引入poi和poi-ooxml依赖: org.apache.poi poi 4.0.0 org.apache.poi poi-ooxml 4.0.0我们要读取一个简单的Sku信息表,内容如下: 
如何将UserModel的信息转化为数据列表? 我们可以通过实现反射+注解的方式定义表头到数据的映射关系,帮助我们实现UserModel到数据对象的转换。实现基本思路是: ① 自定义注解,在注解中定义列号,用来标注实体类的每个属性对应在Excel表头的第几列。 ② 在实体类定义中,根据表结构,为每个实体类的属性加上注解。 ③ 通过反射,获取实体类的每个属性对应在Excel的列号,从而到相应的列中取得该属性的值。 以下是简单的实现,首先准备自定义注解ExcelCol,其中包含列号和表头: import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Target({ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) public @interface ExcelCol { /** * 当前列数 */ int index() default 0; /** * 当前列的表头名称 */ String header() default ""; }接下来,根据Sku字段定义Sku对象,并添加注解,列号分别为0,1,2,并指定表头名称: import lombok.Data; import org.shy.xlsx.annotation.ExcelCol; @Data public class Sku { @ExcelCol(index = 0, header = "sku") private Long id; @ExcelCol(index = 1, header = "名称") private String name; @ExcelCol(index = 2, header = "价格") private Double price; }然后,用反射获取表头的每一个Field,并以列号为索引,存入Map中。从Excel的第二行开始(第一行是表头),遍历后面的每一行,对每一行的每个属性,根据列号拿到对应Cell的值,并为数据对象赋值。根据单元格中值类型的不同,如文本/数字等,进行不同的处理。以下为了简化逻辑,只对表头出现的类型进行了处理,其他情况的处理逻辑类似。全部代码如下: import com.alibaba.fastjson.JSON; import org.apache.commons.lang3.StringUtils; import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook; import org.shy.domain.pojo.Sku; import org.shy.xlsx.annotation.ExcelCol; import java.io.FileInputStream; import java.lang.reflect.Field; import java.text.DecimalFormat; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class MyUserModel { public static void main(String[] args) throws Exception { List skus = parseSkus("D:\sunhaoyu8\Documents\Files\skus.xlsx"); System.out.println(JSON.toJSONString(skus)); } public static List parseSkus(String filePath) throws Exception { FileInputStream in = new FileInputStream(filePath); Workbook wk = new XSSFWorkbook(in); Sheet sheet = wk.getSheetAt(0); // 转换成的数据列表 List skus = new ArrayList(); // 获取Sku的注解信息 Map fieldMap = new HashMap(16); for (Field field : Sku.class.getDeclaredFields()) { ExcelCol col = field.getAnnotation(ExcelCol.class); if (col == null) { continue; } field.setAccessible(true); fieldMap.put(col.index(), field); } for (int rowNum = 1; rowNum |
【本文地址】