| Pandas读取excel数据 | 您所在的位置:网站首页 › excel求皮尔森相关系数 › Pandas读取excel数据 |
Pandas读取excel数据
|
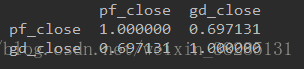
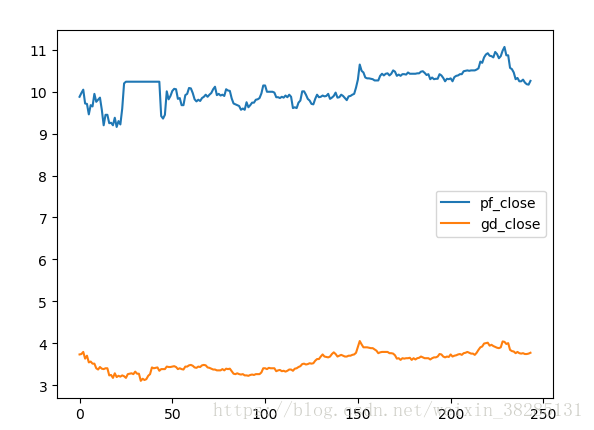
利用Pandas和tushare进行一个简单的数据读取和分析 一丶Pandas的DataFrame操作方法一个表格型数据,提供列名和不同的值,以及索引值 通过下面代码记录一些DataFrame的方法 from pandas import Series,DataFrame #一个字典数据 data={'nike':['hello','world','baby','love'], 'year':[2000,1526,11616,123], 'name':['bob','lucy','amy','andy']} #将字典/列表 数据转化为DataFrame d=DataFrame(data) print(d) #改变数据的输出顺序,按列的形式 print(DataFame(data),columns=['name','year','nike']) #改变其输出的索引名(按abcd索引而不是0123) print(DataFrame(data),columns=['name','year','nike'],index=['a','b','c','d']) #添加一列则该列全部值为21 d['number']=21 #添加一列用Series赋值 d1=Series([1,2,3,4]) d['number']=d1 d2=d.T#数据转置 二丶数据抽取和保存分析这里用到了一个库tushare,里面有很多的数据,链接地址为: http://tushare.org/trading.html 我们从这里面抽取了浦发银行和广大银行的数据,然后保存和分析其相关性 import matplotlib.pyplot as plt import numpy as np import tushare as ts from pandas import DataFrame,Series s_pf='600000'#浦发银行股票代码 s_gd='601818'#光大银行股票代码 sdate='2017-01-01'#数据获取开始日期 edate='2017-12-31'#数据获取结束日期 df_pf=ts.get_h_data(s_pf,start=sdate,end=edate).sort_index(axis=0,ascending=True)#竖着排序 df_gd=ts.get_h_data(s_gd,start=sdate,end=edate).sort_index(axis=0,ascending=True)#竖着排序 #将两个数据整合到一起 df=pd.concat([df_pf.close,df_gd.close],axis=1,keys=['pf_close','gd_close']) #填充数据 df.ffill(axis=0,inplace=True) #保存数据 df.to_csv('pf_gd.csv') #然后对数据进行分析 corre=df.corr(method='pearson',periods=1)#方法选择person相关性 print(corre) plt.plot(figsize=(20,12)) plt.show() 输出结果:相关性接近0.7
|
【本文地址】
公司简介
联系我们