| EXCEL 批量生成sheet表+生成超链接目录+某列按多条件去重罗列+提取单元格中的字母、数字 | 您所在的位置:网站首页 › excel根据名称计算数据 › EXCEL 批量生成sheet表+生成超链接目录+某列按多条件去重罗列+提取单元格中的字母、数字 |
EXCEL 批量生成sheet表+生成超链接目录+某列按多条件去重罗列+提取单元格中的字母、数字
|
文章目录
前言一、EXCEL 公式实现多个条件值匹配二、EXCEL 工作薄下SHEET表太多时你可以这样做1.生成多个相同表头的SHEET表1.1.批量生成SHEET表1.2.批量更改多个SHEET的表头(第一行或者前几行)2.EXCEL 使用超链接快速找到(定位)指定的SHEET表2.1.通过创造辅助列,编写公式2.2.WPS的用户可以使用“智能工具箱”(其他版本可能叫“文档助手”)
三、EXCEL 公式实现将某一列符合多个条件的值去重罗列出来四、EXCEL 公式提取规范字符串中的连续数字或字母五、EXCEL 公式提取不规则字符串中的所有数字或字母六、EXCEL 公式判断是否包含某些关键字七、EXCEL 公式返回数字对应的列字母(包括多字母的)总结
前言
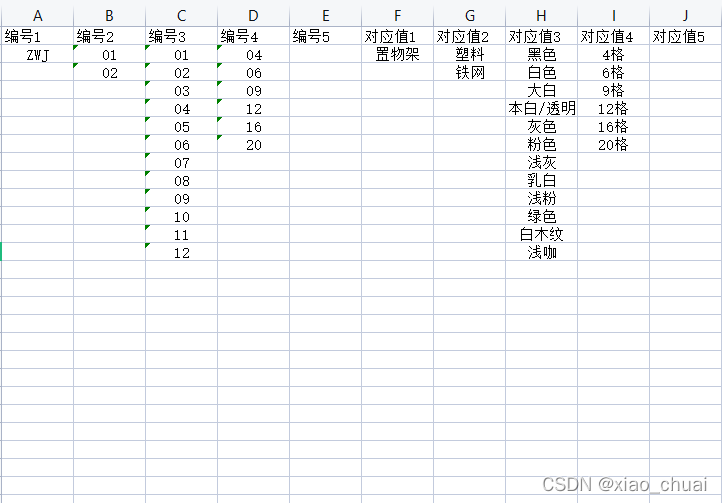
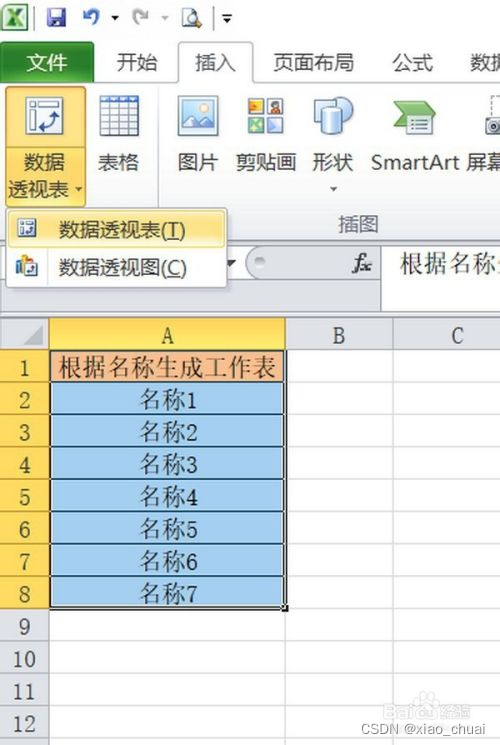
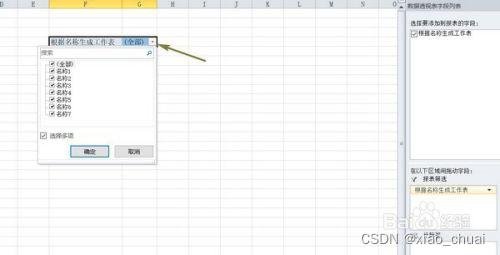
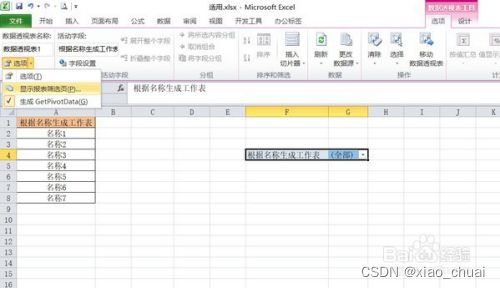
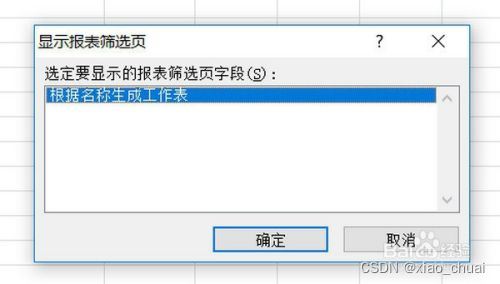
工作中总会有一些麻烦的问题想要用一套公式解决,在度娘查询到答案后,这些让人眼前一亮的公式总是一用就忘,下次继续度娘,这就很不高效了,因此从今天开始做总结记录,一遍更好地掌握知识。 注:标题先后顺序只是因记录顺序不同而这样,每个标题下的内容都可以看做独立内容。 一、EXCEL 公式实现多个条件值匹配场景模拟:当我需要将某一行的连续区域内的单元格作为条件去匹配对应区域内的值,并将在指定的目标区域返回所得的匹配结果作为文本拼接起来形成一个新的字符串。 模拟数据如下: 期望结果如下: 直接上伸手党公式: =SUBSTITUTE(TEXTJOIN("",TRUE,IF((TRANSPOSE($A$1:$E$100)=TRANSPOSE(L2:P2),""),TRANSPOSE($F$1:$J$100),)),0,"") 然后数组三键 公式解析: 拿如下数据举例。 1.TRANSPOSE()是将区域转置的函数,可将EXCEL中的区域当做矩阵来看,这里TRANSPOSE()主要作用是调整返回结果的顺序,作用解释完下面的原理再提。 2.TRANSPOSE($A$1:$E$100)=TRANSPOSE(L2:P2)返回的是一个100 X 5(跟区域的行列数一样)的一个只有TRUE,FALSE的逻辑矩阵,设为A。 如下所示 3.将TRANSPOSE($F$1:$J$100)设为矩阵B,那么IF函数可转化为IF(A,B,"")。而EXCEL中关于IF()函数的定义为: 判断是否满足一个条件:如满足返回一个值,如果不满足返回另一个值。 把他转化为矩阵去理解,其实际效果相当于A*B,结果为TRUE的返回B原来的对应的值,结果为FALSE的返回空白值""(空白可以看做一个值,也就是空白值"")。 如下所示: 公式应用注意事项: 1.条件、条件区域、结果区域列数要一致,可以观察公式中的几个区域,都是五列(当然也可以其他的相同列数)。 2.条件区域、结果区域的行数要一致,且不能太长。本人随机测试了下,一万行是可以的,更多行的区域需要使用者自主发现和调节。 二、EXCEL 工作薄下SHEET表太多时你可以这样做场景模拟: 1.根据单元格对应的名称批量生成对应SHEET表,且保持表头一致。 2.有一个数据总表,有大量的SHEET子表,想要快速定位到指定的SHEET表。 1.生成多个相同表头的SHEET表 1.1.批量生成SHEET表1.首先打开我们Excel,将我们要新建工作表的名称粘贴复制进Excel单元格中 2.选中所有的名称,然后选择菜单栏“插入-数据透视表”,显示出了的那个继续选择“数据透视表”,如图 3.在弹出来的“创建数据透视表”窗口里面勾选现有工作表,然后单击位置最后面的小图标,随便选中一个单元格,按确定,继续确定,如下图 5.单击全部后面的小箭头,选中我们的所有数据,然后将我们的“根据名称筛选数据表与全部单元格选中” 6.单击菜单栏“选项”,之后单击“数据透视表”下方“选项”旁边的小箭头,然后单击“显示报表筛选页”,弹出的小窗口确定 7.我们稍等待,就可以看到下方工作表名称那里生成了我们需要的工作表,不论有多少数据,重复上面的步骤就可以 原文为百度经验链接:https://jingyan.baidu.com/article/e73e26c01ba8c364acb6a75d.html 1.2.批量更改多个SHEET的表头(第一行或者前几行)1.选中一批SHEET的其中一个,选中状态的SHEET表框内填充色会与原先不同,如图 此时,你在这批SHEET中任何一个中的任一单元格做任意操作,其他SHEET的同一单元格也会在相同位置出现相同的操作。 基于如上原理,那么我们只要在其中一个SHEET中复制粘贴一个表头,那么其他SHEET中也会出现相同的表头。 注: 1.当有些单元格处于无法更改的状态或者某些操作跟某些单元格起冲突时,那么这个操作就无法批量进行 2.想要取消这些SHEET的激活状态,点击这批SHEET外的其他SHEET即可。 2.EXCEL 使用超链接快速找到(定位)指定的SHEET表模拟数据如下: 在C2单元格填写以下公式 =HYPERLINK("#"&A2&"!A1",A2) 其中,HYPERLINK(链接位置,[显示文本])有两个参数,第一个参数填的是超链接对应的位置,第二个表示这个单元格(超链接)要显示出来的文本。 2.2.WPS的用户可以使用“智能工具箱”(其他版本可能叫“文档助手”)我的WPS版本为:11.1.0.10667 点击智能工具箱——目录——创建表格目录——点击,如下图所示:
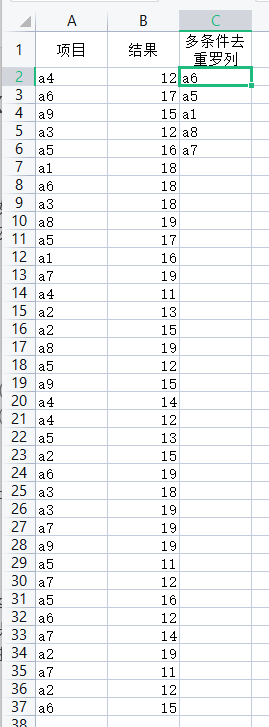
这个貌似是会员才有的功能,在其他的WPS版本里,相关功能可能是在“文档助手”等其他名称的工具箱中,读者自寻查找一下。 网上也有说用宏表函数GET.WORKBOOK(1)的,但宏表函数好像只能在EXCEL中使用。但我的WPS是用不了的,似乎要开启宏(要收费),因此我就没深入探究了。若是读者知道有其他使用公式实现一样功能的,还请顺便告知下。 宏表函数和以上内容的原文链接: https://baijiahao.baidu.com/s?id=1634485912489517484&wfr=spider&for=pc 三、EXCEL 公式实现将某一列符合多个条件的值去重罗列出来场景模拟:例如某些测试数据中,每个项目都测试出了若干个对应数据,现需求结果大于15的的数据去重罗列到出来,以便知道哪些项目是符合条件的。 数据如下: 场景模拟公式如下: =INDEX($A$2:$A$37,SMALL(IF(($B$2:$B$37>15)*(MATCH($A$2:$A$37,$A$2:$A$37,)=ROW($A$2:$A$37)-1),ROW($A$2:$A$37)-1,4^8),ROW(A1))) 然后数组三键 说明: 1.条件区域和目标区域的结束行都必须等于最大有效行,不能多也不能少,起始行根据个人实际情况调整,但公式中的各个区域的起始行和结束行都需要一样。 2.目标区域不能有空白单元格,这里注意了,空格不等于空白。 模板公式: =INDEX([目标区域],SMALL(IF(([条件1])*…*(([条件n]))*(MATCH([目标区域],[目标区域],)=ROW([目标区域])-1),ROW([目标区域])-1,4^8),ROW(A1))) 公式解析: 应用之前说过的矩阵(数组)思维来看待if()里面的逻辑文本:([条件1])*…*(([条件n]))*(MATCH([目标区域],[目标区域],)=ROW([目标区域])-1),那么, 1.条件1到条件n都会得到类似这样的一系列逻辑数组:{FALSE,TRUE,…,FALSE}*…*{TRUE,TRUE,…,FALSE} 2.MATCH([目标区域],[目标区域],)=ROW([目标区域])-1;读者们可以度娘下MATCH()公式的原理介绍,它在本公式中体现的一个原理是“根据条件,返回其第一个匹配结果对应所在区域的相对位置”,这里就实现了去重:“无论有多少个对应值,我只返回第一个”,match()公式本身返回的是一个数字数组,与ROW([目标区域])-1这个数字数组作用才返回逻辑数组,然后再根据之前讲过的if()中逻辑数组错误值和正确值的作用关系,与ROW([目标区域])-1作用,又返回一个符合条件的去重后的数字数组,在通过small(数组,k)来进行下拉时的顺序输出。 3.其实公式本身转化为实际操作是这样的:先进行条件筛选,在筛选的状态下,把目标区域的单元格复制出来,点击“数据”功能中的去重重复项。 这是非本人著作的比较详细的文章,有需要的可以看下: https://wenku.baidu.com/view/18e91f5780eb6294dc886c7a?fr=shopSearch-pc 四、EXCEL 公式提取规范字符串中的连续数字或字母场景模拟:对于某些编码数据,其内容是用数字和字母组成,现需求将单元格中的字母或数字提取出来,但字母、数字的相对位置,是否连续都需用不同的公式输出,现只考虑字母和数字全部在同一边的情形,例如ABCD1234这样的,而不是123ABC456DEF这样不连续的。 提取数字公式: {=MID(A2,MIN(FIND(ROW($1:$10)-1,A2&1/17)),COUNT(–MID(A2,ROW($1:$99),1))+ISNUMBER(FIND(".",A2)))} mid(字符串,开始位置,字符个数),通过这个基础公式,可以得到方向: 1.字符串:也就是你需求提取数字的字符串所在的单元格; 2.开始位置:获得字符串中第一个数字的位置; 3.字符个数:获得字符串中所有数字的个数。 通过获得这三个参数,那么字符串中的数字就可以提取出来了。 下面以图中A1例子为例,讲下公式拆解后的原理和过程: 参考并引用了该知乎回答中答主“Jqgsninimo”的答案: 作者:Jqgsninimo 链接:https://www.zhihu.com/question/268335545/answer/944153347 来源:知乎 ①ROW($1:$10)-1 结果: {0,1,2,3,4,5,6,7,8,9} 说明:ROW(reference)函数用于获取reference所引用区域中每一行的行号,形成行号数组 返回,一般用于构建等差数列(数组),例如: ROW($1:$5): {1,2,3,4,5} ROW($1:$5)*2+3: {5,7,9,11,13} 此处生成该数组用于从A1内容中查找所有数字字符。 ②A1&1/17 结果:例:FY-ZWJ0202200.0588235294117647 说明:&符号用于连接两个字符串。 将1/17的计算结果添加到A1内容的后面,1/17的结果为无限循环小数,在Excel中转化为文本表示为0.0588235294117647,可发现这其中完整包含了0到9的数字,这样做的目的是使FIND函数依次查找所有数字字符时不会出错,进而在MIN方法中获取到最先出现数字的位置,也就是原先的例子中的第一个出现的数字。 ③FIND(ROW($1:$10)-1,A1&1/17) 结果:{5,25,19,7,24,16,8,27,17,23} 说明:FIND(find_text,within_text,start_num)函数会从within_text的第start_num个字符开始查找find_text,返回find_text首次出现的位置;当找不到find_text 时,返回无效值:#VALUE! start_num参数可以忽略,当该参数忽略时,会从within_text 的第一个字符开始查找。 这里依次在A1内容中查找0至9数字字符的位置,形成位置数组 。 由于A1内容添加了包含所有数字字符的1/17后缀,即便A1内容中不含有某个数字字符,该函数也可以顺利生成位置数组。 ④MIN(FIND(ROW($1:$10)-1,A1&1/17)) 结果:9 说明:MIN(number1,number2,…)函数返回所有参数中最小的值。 获取A1内容中首个数字的位置,也就是MID()函数中参数:开始位置。 由于A1后缀了1/17,如果A1中不含有数字,该位置为后缀部分的首位,其值为A1内容的长度+1。 ⑤ROW($1:$99) 结果:{0,1,2,3,…,98,99} 说明:生成该数组用于从A1内容中提取各个位置的内容。 这里设置为99,主要是为了能完全覆盖A1内容中的所有字符的位置。 若是目标字符是长度超过99的字符串,也可设置更大的数字,例如ROW($1:$999)。 ⑥MID(A1,ROW($1:$99),1) 结果:{例,:,F,Y,-,Z,W,J,0,2,0,2,2,0} 说明:MID(text,start_num,num_chars)函数返回text自第start_num个字符开始的num_chars个字符所构成的字符串。 如果num_chars 超出了text的范围,则忽略超出的部分。 从A1内容中出现的第一个数字字符开始,依次提取各个位置的字符串,构成字符数组 。 对于MID函数来说,如果第二个参数,也就是开始位置超出原字符串长度,则忽略超出的部分,或者说可能返回的是一个空值,这里我们也忽略不计。 ⑦–MID(A1,ROW($1:$99),1) 结果:{#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,0,2,0,2,2,0} 说明:添加两个负号使得数组内的字符串都被强制转化为数字并取正,这就导致两个结果: 全部为数字字符的字符串会转化为数字并取正,大于等于0;包含其他字符的字符串运算失败,变为无效值#VALUE。 其实这里的结果是为了便于下面的解释而修正的结果,实际上如果数组中包含一个无效值,则整个数组都变为无效,也即这个数组的真实的结果是:#VALUE!,但我们可以通过某些函数来剔除错误/无效值的影响。 ⑧COUNT(–MID(A1,ROW($1:$99),1)) 结果:6 说明:COUNT 函数计算包含数字的单元格个数以及参数列表中数字的个数。 使用 COUNT 函数获取区域中或一组数字中的数字字段中条目的个数。 该函数具有以下特性: Ⓐ如果参数是一个数组或引用,则只计算其中的数字。 数组或引用中的空白单元格、逻辑值、文本或错误值将不计算在内。基于以上特性,该函数对于{#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,#VALUE!,0,2,0,2,2,0}的计数,实际计数的是{0,2,0,2,2,0}这个数组,因此得到结果6。 ⑨ISNUMBER(FIND(".",A1)) 结果:FALSE 说明:ISNUMBER(VALUE)检查一个值是否为数值,是则返回TRUE(可当做数值1来进行几何计算),否则返回FALSE(可以当做数值0来进行几何计算)。 这里是对字符串中的数字部分是否包含“小数点”进行判断,但也有个弊端,那就是若是小数点“.”是在字母中当做点来表示,那也会判断为TRUE,也就是结果是1,那么此时字符个数就会比实际大1,若是数字在前的情况例如:1234AB.CD,此时使用公式就会返回1234A,因为代表字符个数部分的公式的计算出来的结果比实际大1,因此在使用时注意调节。 ⑩COUNT(–MID(A1,ROW($1:$99),1))+ISNUMBER(FIND(".",A1)) 结果:6 说明:这里就是用于计算目标字符串中,所有数字的个数(包括正确位置的小数点),其结果就是整个MID()函数中的“字符个数”。 如上①至⑩所述,得到了“开始位置”和“字符个数”这两个参数,所以就可以用MID()来提取数字了。 提取字母公式: {=SUBSTITUTE(A2,MID(A2,MIN(FIND(ROW($1:$10)-1,A2&1/17)),COUNT(–MID(A2,ROW($1:$99),1))+ISNUMBER(FIND(".",A2))),""} 提取字母公式实际上就是在提取数字公式的基础上加了SUBSTITUTE()公式,该公式作用就是将字符串中的某些字符替换为指定的字符,那么我把字符串中的数字替换成空白值“”,那不就实现了提取字母了? 当然应当注意的是这两个公式都是都是建立在数字和字母都是连续的,例如ABC123或者123ABC这样的格式的。 那么当我们想提取不连续的字母数字甚至汉子组合的时候,怎么做呢?请继续看下面 五、EXCEL 公式提取不规则字符串中的所有数字或字母to be continue… 六、EXCEL 公式判断是否包含某些关键字场景模拟:有时对于一列数据,我希望知道是否包含了某一列的关键字,且列出这个关键字的具体内容,用vlookup(),index(match())这类,只是用来匹配相同内容的字段,而非“查找是否包含某列(些)关键字”,因此通过如下公式实现: 判断是否包含其中的关键字: =IF(ISERROR(LOOKUP(2,1/IF(B:B"",FIND(B:B,A2)),B:B)),“否”,“是”) 注:B:B是关键字所在的列,A2指的是需求判断的单元格。 说明: 1.可直接选择一整列,无须填入关键字列所在列的有效行数,比较方便。 2.该公式仅用于判断是否包含某个关键字,但不返回具体是哪个关键字。 返回具体包含的关键字: =IFERROR(LOOKUP(1,0/FIND(B$1:B$4,A2),B$1:B$4),"") 注:B$1:B$4是关键字所在的列的有效区域,可视实际情况调整最大行数,即非空,有内容的具体区域,A2指的是需求判断的单元格。 说明: 1.需要限定了关键字区域不能存在空白,即最大行数不能大于关键字的有效区域,故而需要手动调整实际行数。 2.该公式能返回目标单元格包含了具体哪个关键字。 七、EXCEL 公式返回数字对应的列字母(包括多字母的)场景模拟:在引用一些数据时,需要选中指定的区域,例如SUMIFS([求和区域],[区域1],[条件1],[区域2],[条件2],…),但在做一些模板类型的表格时,经常会遇到一个问题,若是某次系统数据更新了,原本引用的区域位置发生了变化怎么办?这时我们就会需要动态地、可变地返回指定区域,依次来避免引用数据错误的问题,这时我们就需要能精确的返回列字母了。 多字母列号返回: SUBSTITUTE(ADDRESS(1,列序号,4),1,) 说明: 1.列序号表示的是从A列为1算起,目标列所在相对位置的序号,例如A为1,B为2…,AA为27,依次类推。 2.可将列序号 替换为 match([目标字段],[字段所在区域],0),这样能得到指定字段所在的列对应的列字母,但这里只是得到一个列字母,要想得到对应的区域,需要先用文本拼接符拼接起来,再用indirect(),将这个文本转化为可引用的区域,以此实现动态变化。 总结以上内容都是关于EXCEL数据处理的一些小技巧,总体的应用环境是关于电商产品编码的管理,个人是建议对编码实现标准化管理,这样有助于后期的维护和更新。 关于公式中矩阵思维的理解,本人理解有限,所以不能很好的描述出来。 注:公式中的{}代表数组三键,即我们写完公式之后会敲击Enter来进行输出,此时的敲击换成了Ctrl + Shift + Enter,这就是数组三键,而不是在公式中输入{} |

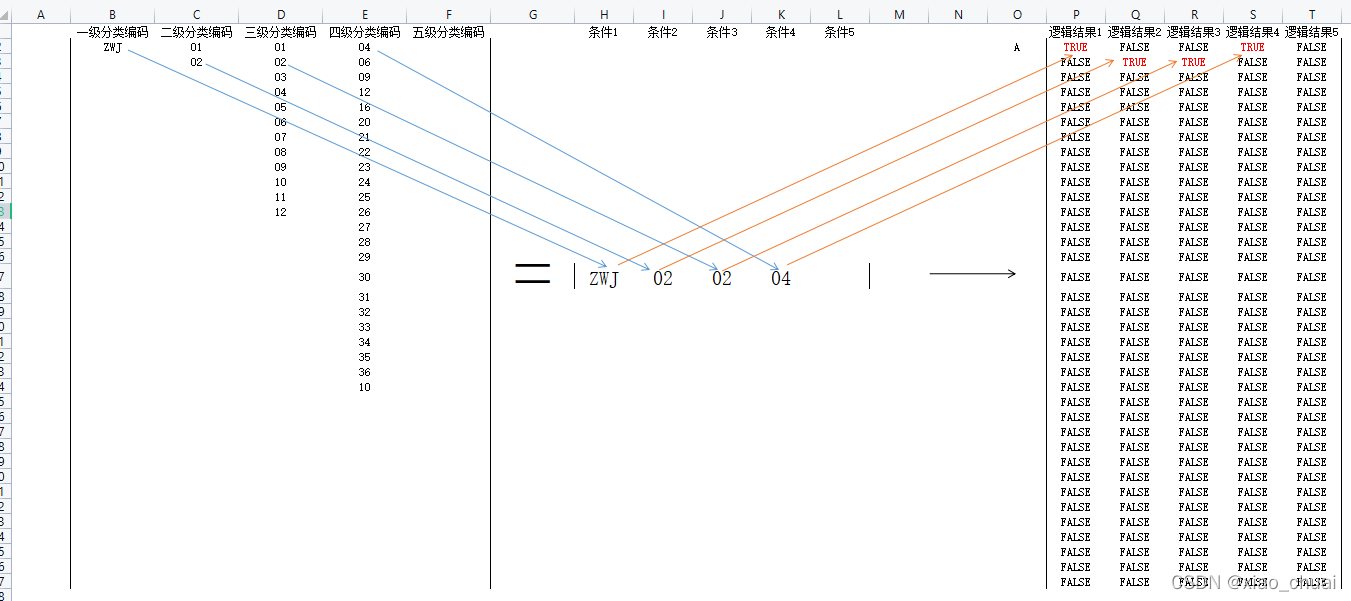 博主学渣,忘了这种求出0,1(FALSE,TRUE相当于0,1)的方式在矩阵里叫什么了,大概就是这个原理,嗯…
博主学渣,忘了这种求出0,1(FALSE,TRUE相当于0,1)的方式在矩阵里叫什么了,大概就是这个原理,嗯… 4.再用TEXTJOIN()将结果进行拼接,这里注意了,TEXTJOIN是按行拼接的,那要是不转置,那按图中的结果那就是TEXTJOIN("",TRUE,{“置物架”,"","",“4格”,""},{"",“铁网”,“白色”,"",""},{"","","","",""},{"","","","",""},…,{{"","","","",""}}) = 置物架4格铁网白色,但我的需求是将结果按级数的顺序进行拼接,也就是一级分类在结果字符串中的第一个,二级分类在结果字符串中的第二个…以此类推,将这个需求转为图中就是要想办法按列拼接,但TEXTJOIN只能按行拼接,那我们换个思路,我们将结果转置一下,那原来的列不就变成行了吗?那么此时进行的按行拼接其实际效果就相当于我们需要的按列拼接。
4.再用TEXTJOIN()将结果进行拼接,这里注意了,TEXTJOIN是按行拼接的,那要是不转置,那按图中的结果那就是TEXTJOIN("",TRUE,{“置物架”,"","",“4格”,""},{"",“铁网”,“白色”,"",""},{"","","","",""},{"","","","",""},…,{{"","","","",""}}) = 置物架4格铁网白色,但我的需求是将结果按级数的顺序进行拼接,也就是一级分类在结果字符串中的第一个,二级分类在结果字符串中的第二个…以此类推,将这个需求转为图中就是要想办法按列拼接,但TEXTJOIN只能按行拼接,那我们换个思路,我们将结果转置一下,那原来的列不就变成行了吗?那么此时进行的按行拼接其实际效果就相当于我们需要的按列拼接。
 4.之后将我们的列名“根据名称生成工作表”拖动至下方“报表筛选”中,如图
4.之后将我们的列名“根据名称生成工作表”拖动至下方“报表筛选”中,如图 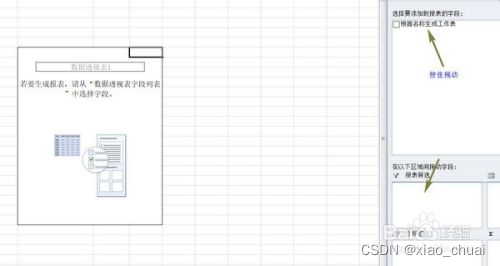

 2.基于选中的SHEET处于选中状态的情况下,按住键盘上的Shift + 鼠标左键单击选中一批SHEET表中的最后一个,就可以使得这批SHEET都处于相同激活状态。如下图
2.基于选中的SHEET处于选中状态的情况下,按住键盘上的Shift + 鼠标左键单击选中一批SHEET表中的最后一个,就可以使得这批SHEET都处于相同激活状态。如下图 
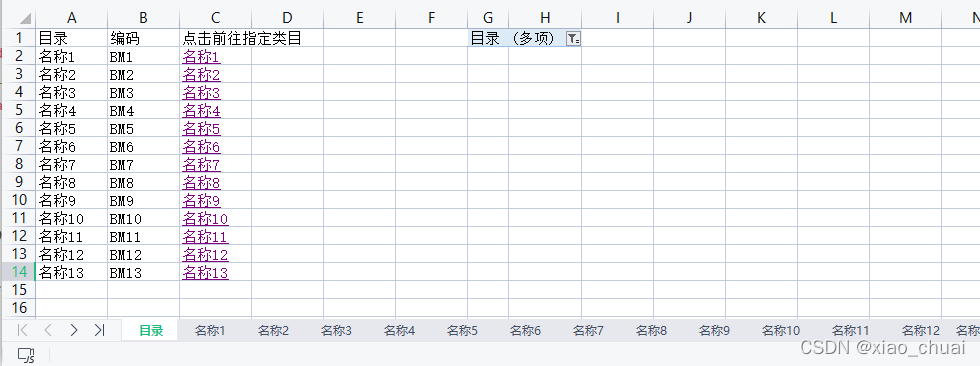 想要生成这样一个到达指定SHEET的目录表有以下两种方式:
想要生成这样一个到达指定SHEET的目录表有以下两种方式:
 按个人所需选择
按个人所需选择 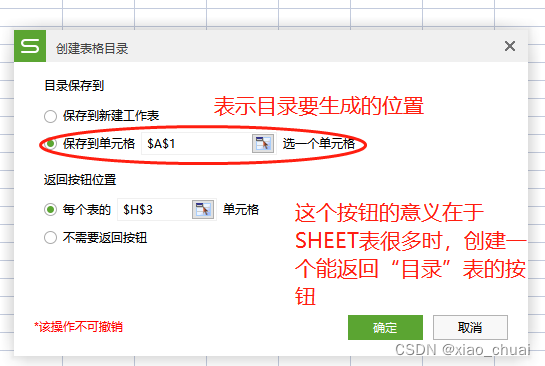 在“目录”这张表里的A1单元格中生成了所有子表的超链接目录
在“目录”这张表里的A1单元格中生成了所有子表的超链接目录 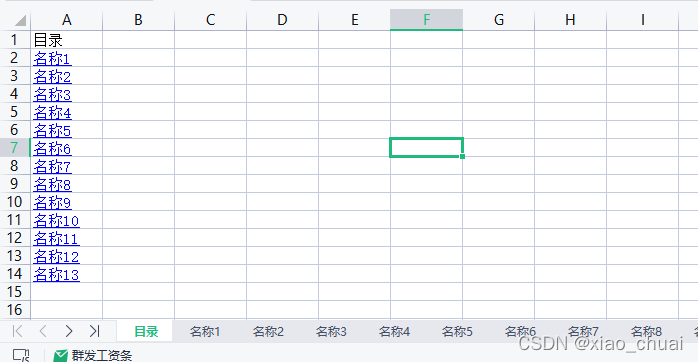 在每个子表的H3中创建了一个返回“目录”表的按钮
在每个子表的H3中创建了一个返回“目录”表的按钮 

【本文地址】