| 以实战学习pandas使用方式:统计考生成绩统计及分布 | 您所在的位置:网站首页 › excel学生成绩统计优秀多少个 › 以实战学习pandas使用方式:统计考生成绩统计及分布 |
以实战学习pandas使用方式:统计考生成绩统计及分布
|
以实战学习pandas使用方式:统计考生成绩统计及分布
引子需求逐步实现使用 pandas 读 excel初始化一些数据获取 excel 列名获取总表的统计数据分班级数据各科目比率统计统计名次分布
写入文件小结
引子
老顾日常工作,是用不到 python 的,所以,老顾的 python 学习进度推进的非常缓慢,至今没用上 pandas 和 numpy,即便参加了新星计划艾派森的学习小组,也没什么动力去看这方面的内容。 结果,昨天在群里,有个小伙伴问老顾能不能帮忙做个数据统计。由于老顾最近准备开营做一期数据库进阶查询的内容,所以这个小伙伴就问怎么用数据库做。 然后的然后,发现这个小伙伴是学了一些 python 基础的。。。。。好么,放着 pandas 不用,想要装个 sqlserver 。。。。也是够可以的。 于是,老顾就用这个小伙伴的内容,做了一次学习,熟悉一下 pandas。 CSDN 文盲老顾的博客,https://blog.csdn.net/superwfei 需求
然后,需要得到全部学生各科的平均分,及格率以及优秀率。 其次,将总表按班级分成多个子表,并对每个班级统计各科的平均分,及格率及优秀率。 再然后,出一个统计表,统计各科目中,各班的平均分,合格率,优秀率,并按照一定权重,计算出最后的合计分,并对合计分进行排名。 最后,出一个简单的统计,统计每个班,前n名各有多少人。 嗯。。。。。好么,一看这需求,那 pandas 必须上啊,一个学习 pandas 的好机会。 逐步实现 使用 pandas 读 excel import pandas as pd source = r'期中测试成绩汇总.xls' df = pd.read_excel(source,sheet_name='学生总成绩')为了以后使用方便,把文件名单独放到变量中,后续使用就方便一点。 然后,pandas 自带读 excel 文件的方法,并且可以指定 sheet。很方便哦。 初始化一些数据对于平均分,我们好弄,但是及格率和优秀率,却需要一些数据支持了。经过与小伙伴的沟通,初始了两个字典。 # 初始化常数,满分和统计比率 full = {'语文':120,'数学':120,'英语':120,'物理':70,'政治':70,'化学':50,'历史':50,'总分':600} grade = {'及格':60,'优秀':80}用full来记录各科目的满分成绩,用 grade 来记录各档次为满分的百分之多少。 获取 excel 列名为了保证数据的一致性,我们要读一次 excel 列名,在之后附加数据的时候,保证各列的顺序不会发生紊乱。 # 获取列名 columns = [k for k,d in df.iteritems()]pandas 自己提供了 iteritems 方法,这就是一个迭代推导式,直接遍历即可。 获取总表的统计数据 # 平均分 print(['','平均分'] + [round(v,2) for v in df.mean()]) # 各种率 print([['',g + '率'] + [round(len(df[df[k] >= full[k] * grade[g] / 100]) / len(df) * 100,2) for k,d in df.iteritems() if k in full] for g in grade])
而各种率,老顾就用推导式直接弄了,推导式的学习,可以参考老顾的文章《python 基础系列篇:八、熟练掌握推导式》。 计算方式也很简单,使用 pandas 自带的筛选功能 pd[pd[列] 条件] 可以得到符合条件的结果集,用 len 测下长度,比上总数,就是各种率了。 这里的条件,就是用各科满分成上各种率的比例,为了避免出错,还要限定列是出现在各科目字典中的。 总之,用推导式就完事。 最后把这几个数据,也转成 DataFrame。 # 获取总平均分,总及格率,总优秀率 app = pd.DataFrame([[],[]] + [['','平均分'] + [round(v,2) for v in df.mean()]] + [['',g + '率'] + [round(len(df[df[k] >= full[k] * grade[g] / 100]) / len(df) * 100,2) for k,d in df.iteritems() if k in full] for g in grade],columns=columns) 分班级数据后边的数据,要分成各个班级,做成子表,所以,先获取下班级信息。集合加排序,很方便。 # 获取班级号 clss = sorted(set(df['班级']))需要注意变量名不要使用关键字,比如 class 或者 cls 之类的,会报语法错误哦。 得到班级号之后,直接用列表推导式,得到各班级各自的成绩即可。还是用 DataFrame 的筛选功能。 # 获得各班成绩 班级成绩 = [df.loc[df['班级'] == k] for k in clss]变量名可以用中文哦,实在不知道怎么给变量起名,作为起名废,那就直接上中文。 然后按照总表得到的统计方式,统计各班的统计信息。 # 获得各班统计 班级统计 = [pd.DataFrame([[],[]] + [['','平均分'] + [round(v,2) for v in 班级成绩[i].mean()]] + [['',g + '率'] + [round(len(班级成绩[i][班级成绩[i][k] >= full[k] * grade[g] / 100]) / len(班级成绩[i]) * 100,2) for k,d in 班级成绩[i].iteritems() if k in full] for g in grade],columns=columns) for i,k in enumerate(clss)]推导式玩得转,代码就看着很简略。 各科目比率统计再次沟通后得到各比率的权重和列名集合,继续用推导式得到结果。 # 四率计算 四率列名 = ['班级','平均分','折合','及格率','折合','优秀率','折合','巩固率','折合','合计分','名次'] 四率 = [[[k,班级统计[i].loc[2][科目],round(班级统计[i].loc[2][科目] * .2,2),班级统计[i].loc[3][科目],round(班级统计[i].loc[3][科目] * .5,2),班级统计[i].loc[4][科目],round(班级统计[i].loc[4][科目] * .1,2),100,10,round(班级统计[i].loc[2][科目] * .2 + 班级统计[i].loc[3][科目] * .5 + 班级统计[i].loc[4][科目] * .1 + 10,2),0] for i,k in enumerate(clss)] for 科目 in full]名次项,小伙伴有特殊需求,需要1班和2班比较,3,4,5,6,7班进行比较,得出各自的排名。所以,这个只能用循环做了。 final = [] for i,k in enumerate(full): arr = 四率[i] rank1 = sorted(set([v[9] for u,v in enumerate(arr) if u 1]),reverse=True) for u,j in enumerate(arr): j[10] = (rank1 if u |
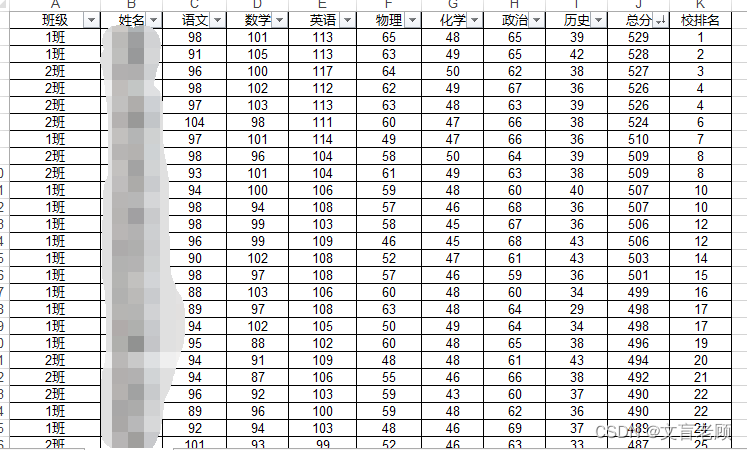 首先,是有这么一个 excel 表,记录了某年级全部学生的考试成绩。
首先,是有这么一个 excel 表,记录了某年级全部学生的考试成绩。 可以看到平均分很方便,直接 mean 即可。。。。。
可以看到平均分很方便,直接 mean 即可。。。。。【本文地址】