| pandas DataFrame表格(列)拼接(concat,append,join,merge) | 您所在的位置:网站首页 › excel多行数据合并成一列行且能复制到其他表格 › pandas DataFrame表格(列)拼接(concat,append,join,merge) |
pandas DataFrame表格(列)拼接(concat,append,join,merge)
|
文章目录
一、pd.concat()二、df.append()三、df.join()四、pd.merge()五、列拼接及其他
方法名说明concat()axis设置用于df间行拼接(增加行)或列拼接(增加列)进行内联或外联拼接操作append()dataframe数据类型的方法,提供了行方向(堆叠行)的拼接操作join()dataframe数据类型的方法,提供了列方向(拼接列)的拼接操作,支持左联、右联、内联和外联四种操作类型merge()提供了类似于SQL数据库连接操作的功能,支持左联、右联、内联和外联等全部四种SQL连接操作类型
一、pd.concat()
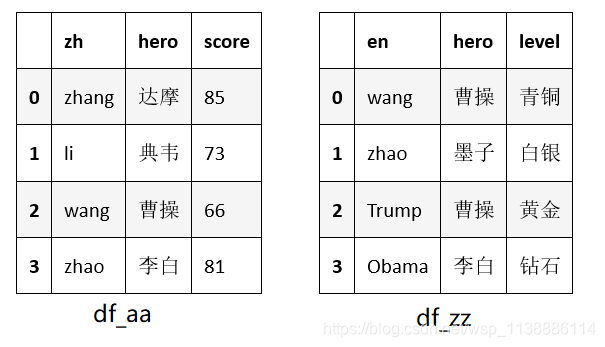
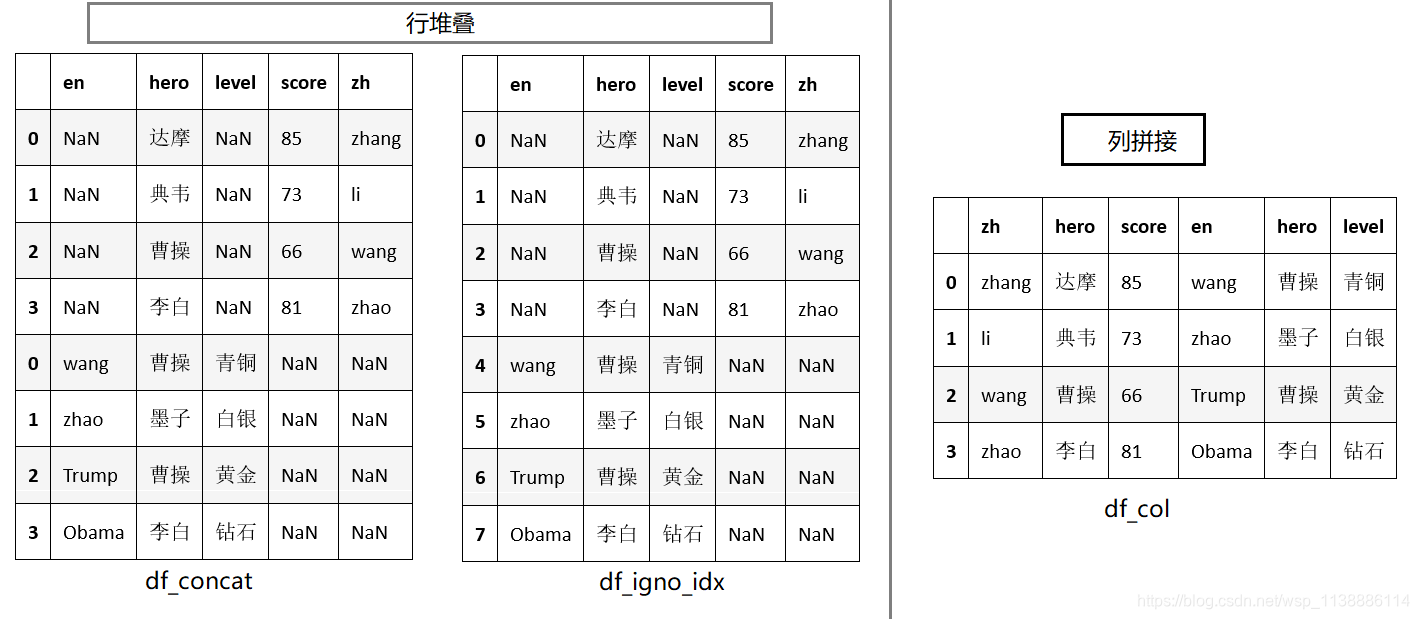
concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False,copy=True) 常用参数说明: axis:拼接轴方向,默认为0,沿行拼接;若为1,沿列拼接 join:默认外联’outer’,拼接另一轴所有的label,缺失值用NaN填充;内联’inner’,只拼接另一轴相同的label; join_axes: 指定需要拼接的轴的labels,可在join既不内联又不外联的时候使用 ignore_index:对index进行重新排序 keys:多重索引 import pandas as pd df_aa = pd.DataFrame({'zh':['zhang','li','wang','zhao'], 'hero':['达摩','典韦','曹操','李白'], 'score':['85','73','66','81']}) df_zz = pd.DataFrame({'en':['wang','zhao','Trump','Obama'], 'hero':['曹操','墨子','曹操','李白'], 'level':['青铜','白银','黄金','钻石']})
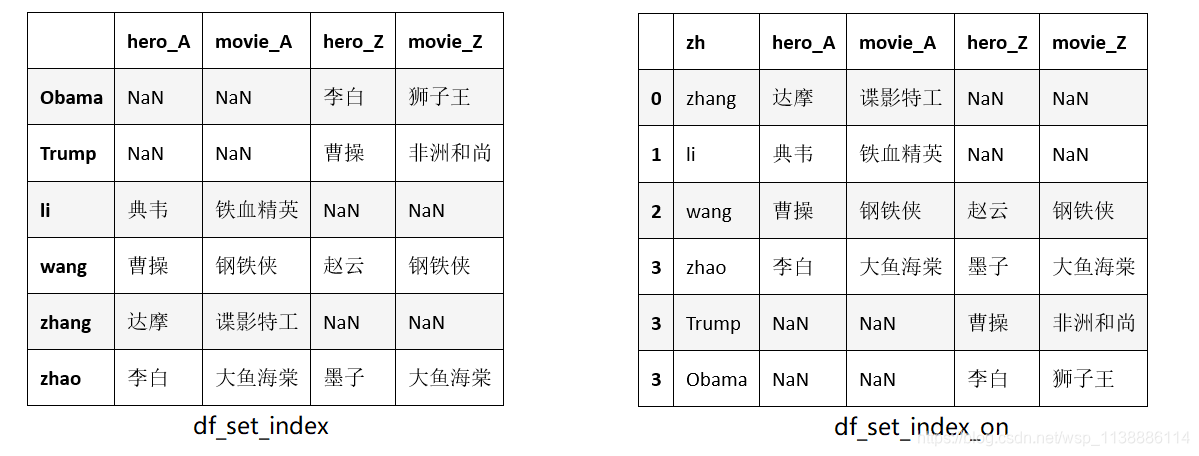
append(self, other, ignore_index=False, verify_integrity=False) 常用参数说明: other:另一个df ignore_index:若为True,则对index进行重排 verify_integrity:对index的唯一性进行验证,若有重复,报错。若已经设置了ignore_index,则该参数无效 三、df.join()join(other, on=None, how=‘left’, lsuffix=’’, rsuffix=’’, sort=False) 主要用于索引上的合并 常用参数说明: on:参照的左边df列名key(可能需要先进行set_index操作),若未指明,按照index进行join how:{‘left’, ‘right’, ‘outer’, ‘inner’}, 默认‘left’,即按照左边df的index(若声明了on,则按照对应的列);若为‘right’abs照左边的df。若‘inner’为内联方式;若为 ‘outer’为全连联方式 。 sort:是否按照join的key对应的值大小进行排序,默认False rsuffix:当left和right两个df的列名出现冲突时候,通过设定后缀的方式避免错误 import pandas as pd df_AA = pd.DataFrame({'zh':['zhang','li','wang','zhao'], 'hero':['达摩','典韦','曹操','李白'], 'movie':['谍影特工','铁血精英','钢铁侠','大鱼海棠']}) df_ZZ = pd.DataFrame({'en':['wang','zhao','Trump','Obama'], 'hero':['赵云','墨子','曹操','李白'], 'movie':['钢铁侠','大鱼海棠','非洲和尚','狮子王']}) df_AA.join(df_ZZ) # 两者有相同的列名‘hero’,'movie',所以报错 df_suffix = df_AA.join(df_ZZ , lsuffix='_A', rsuffix='_Z') # 通过添加后缀避免冲突
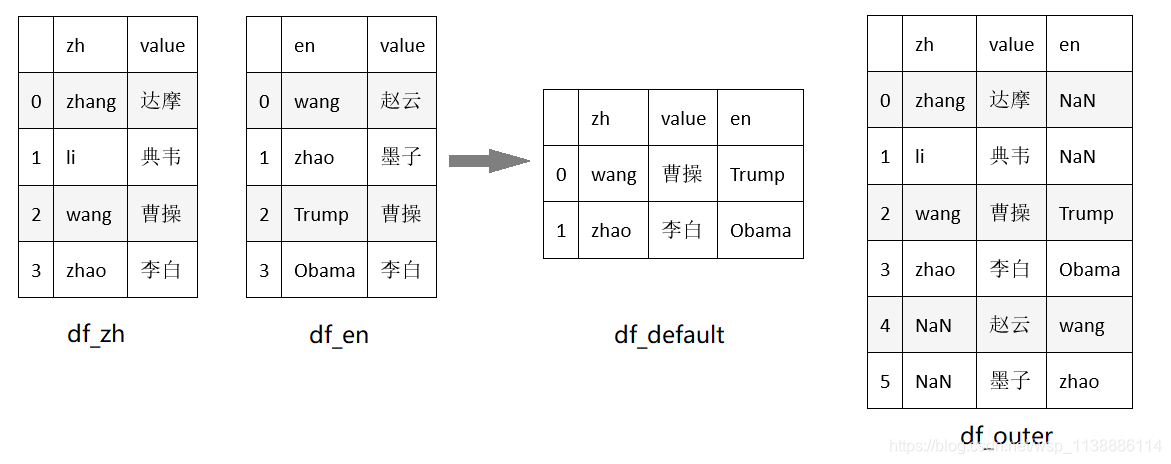
pandas.merge是pandas的全功能、高性能的的内存连接操作,在习惯上非常类似于SQL之类的关系数据库。 merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(’_x’, ‘_y’), copy=True, indicator=False) 常用参数说明: left和 right:两个要合并的DataFrame; how:连接方式,有 inner、left、right、outer, 默认为inner; on:指的是用于连接的 列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键; left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用; right_on:右侧DataFrame中用于连接键的列名; left_index:使用左侧DataFrame中的 行索引作为连接键; right_index:使用右侧DataFrame中的行索引作为连接键; sort:默认为True,将合并的数据进行排序,设置为False可以提高性能; suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’, ‘_y’); copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能; indicator:显示合并数据中数据的来源情况示例1:默认连接键 import pandas as pd df_zh = pd.DataFrame({'zh':['zhang','li','wang','zhao'], 'value':['达摩','典韦','曹操','李白']}) df_en = pd.DataFrame({'en':['wang','zhao','Trump','Obama'],'value':['赵云','墨子','曹操','李白']}) df_default = pd.merge(df_zh,df_en) # 使用默认参数 df_outer = pd.merge(df_zh,df_en,how='outer') # 外联模式下 ''' 从下图看出:显然以两个DataFrame列名交集(也就是value字段)作为连接键,且默认为内联(取交集) '''
示例5:类似Excel的vlookup函数 import pandas as pd df1 = pd.read_excel('./shili.xlsx',sheet_name = 'Sheet2') df2 = pd.read_excel('./shili.xlsx',sheet_name = 'Sheet3') result = pd.merge(df1,df2.loc[:,['学号','分数']],how='left',on = '学号') print('df1,df2',df1,df2) # 效果如下图 print('result',result) # 效果如下图
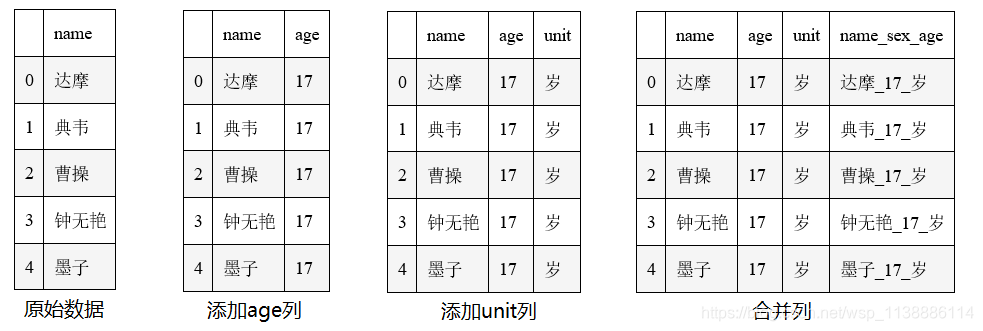
以下涉及:字符串列的合并,新建并填充列(整列类型转换),数值列的合并 import pandas as pd import numpy as np from pandas import Series,DataFrame raw_data = ['达摩','典韦','曹操','钟无艳','墨子'] data_Dateframe = pd.DataFrame({"name":raw_data}) data_Dateframe['age'] = 17 # 添加age列并填充int 17 data_Dateframe['unit'] = '岁' # 添加unit列并填充str 岁 data_Dateframe['age'] = data_Dateframe['age'].astype('str') # int2str data_Dateframe['name_sex_age'] = data_Dateframe['name'].str.cat([data_Dateframe.age,data_Dateframe.unit],sep='_') print(data_Dateframe)
鸣谢: https://www.cnblogs.com/wodexk/p/10803979.html |
 pandas 合并多个csv文件
pandas 合并多个csv文件
 示例1:指定连接键on – 与连接方式how
示例1:指定连接键on – 与连接方式how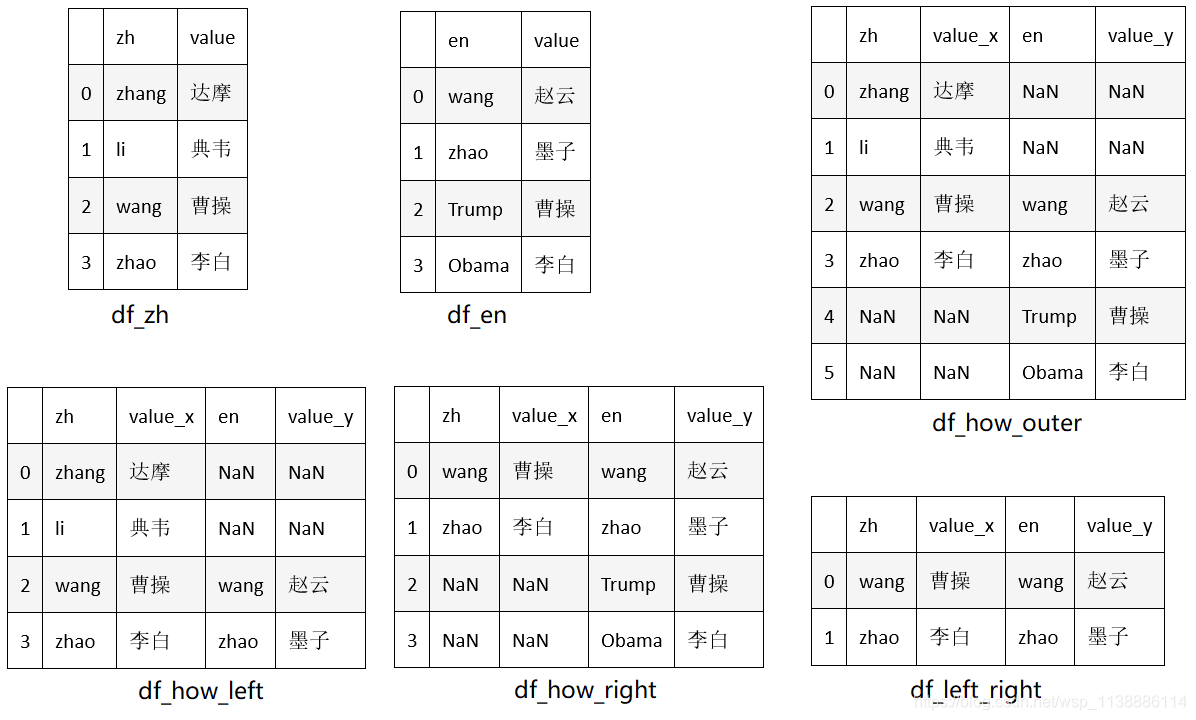

 Dataframe_tuple_list_dict: 将Dataframe转成元组、列表及字典
Dataframe_tuple_list_dict: 将Dataframe转成元组、列表及字典【本文地址】
公司简介
联系我们