|
pandas通常在读取excel数据之后,如果需要进行去重,有两种方式,一种是进行标记,另一种是在pandas中直接去重 如下图所示,excel数据: 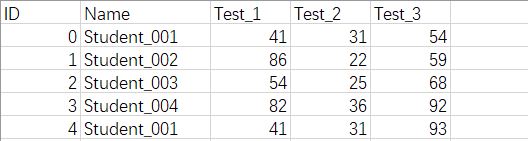 (1)使用drop_duplicates(subset=None, keep=‘first’, inplace=False)删除重复项 参数解释: Parameters ---------- subset : column label or sequence of labels, optional Only consider certain columns for identifying duplicates, by default use all of the columns(指定列标记,默认当每一条行记录完全 相同时,才会认定为重复行) keep : {‘first’, ‘last’, False}, default ‘first’ - first : Drop duplicates except for the first occurrence. - last : Drop duplicates except for the last occurrence. - False : Drop all duplicates. (删除重复行时,保留first还是last还是全部删除) inplace : boolean, default False Whether to drop duplicates in place or to return a copy (直接替换还是保留副本) (1)使用drop_duplicates(subset=None, keep=‘first’, inplace=False)删除重复项 参数解释: Parameters ---------- subset : column label or sequence of labels, optional Only consider certain columns for identifying duplicates, by default use all of the columns(指定列标记,默认当每一条行记录完全 相同时,才会认定为重复行) keep : {‘first’, ‘last’, False}, default ‘first’ - first : Drop duplicates except for the first occurrence. - last : Drop duplicates except for the last occurrence. - False : Drop all duplicates. (删除重复行时,保留first还是last还是全部删除) inplace : boolean, default False Whether to drop duplicates in place or to return a copy (直接替换还是保留副本)
>>> import pandas as pd
>>> df = pd.read_excel(r'C:\Users\liuchao\Desktop\Students.xlsx', 'Sheet1')
>>> df
ID Name Test_1 Test_2 Test_3
0 0 Student_001 41 31 54
1 1 Student_002 86 22 59
2 2 Student_003 54 25 68
3 3 Student_004 82 36 92
4 4 Student_001 41 31 93
# 如上图所示,df中其实是没有重复的,因此在做删除时,是不会删除任一行的
>>> df.drop_duplicates()
ID Name Test_1 Test_2 Test_3
0 0 Student_001 41 31 54
1 1 Student_002 86 22 59
2 2 Student_003 54 25 68
3 3 Student_004 82 36 92
4 4 Student_001 41 31 93
# 删除Name中的相同数据,并保留最后重复中的最后一行记录
>>> df1 = df.drop_duplicates(['Name'], keep='last')
>>> df1
ID Name Test_1 Test_2 Test_3
1 1 Student_002 86 22 59
2 2 Student_003 54 25 68
3 3 Student_004 82 36 92
4 4 Student_001 41 31 93
# 只有当Name, Test_1中两列重复时,才删除重复行
>>> df2 = df.drop_duplicates(['Name', 'Test_1'], keep='first')
>>> df2
ID Name Test_1 Test_2 Test_3
0 0 Student_001 41 31 54
1 1 Student_002 86 22 59
2 2 Student_003 54 25 68
3 3 Student_004 82 36 92
# 由于此时inreplace默认为false,因此df并不会发生变化
>>> df
ID Name Test_1 Test_2 Test_3
0 0 Student_001 41 31 54
1 1 Student_002 86 22 59
2 2 Student_003 54 25 68
3 3 Student_004 82 36 92
4 4 Student_001 41 31 93
(2)使用df.duplicated(subset=None, keep=‘first’)对重复行进行标记
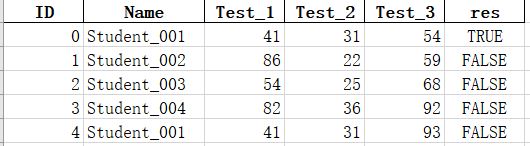
>>> df['res'] = df.duplicated(['Name'], keep='last')
>>> df
ID Name Test_1 Test_2 Test_3 res
0 0 Student_001 41 31 54 True
1 1 Student_002 86 22 59 False
2 2 Student_003 54 25 68 False
3 3 Student_004 82 36 92 False
4 4 Student_001 41 31 93 False
# 这样便对原数据进行了标记,可以将结果输入到excel中,做进一步处理
>>> df.to_excel(r'C:\Users\liuchao\Desktop\Students.xlsx', 'Sheet2', index=None)
 哈哈,以上就是对pandas如何处理重复数据的学习,如果您有兴趣,欢迎关注我的公众号:python小工具。一起让办公变得更方便吧 哈哈,以上就是对pandas如何处理重复数据的学习,如果您有兴趣,欢迎关注我的公众号:python小工具。一起让办公变得更方便吧 
|