| Stable Diffusion WebUI 实践: 基本技法及微调 | 您所在的位置:网站首页 › example用法 › Stable Diffusion WebUI 实践: 基本技法及微调 |
Stable Diffusion WebUI 实践: 基本技法及微调
|
我们使用AUTOMATIC111。 我们先来看txt2img。此选项卡执行 Stable Diffusion 的最基本功能:将文本提示转换为图像。 基本用法 Stable Diffusion checkpoint:选择您想要的模型。有很多已经训练好的模型可供选择,如果你有自己特别的需求,也可以训练自己的模型。 Prompt:描述您想在图像中看到的内容。下面会有稍微详细一些的介绍。 Negative prompt:反向提示文本。把你不想看到的东西都输入进去。下面会有稍微详细一些的介绍。 Sampling Method: 用于去噪,内置多种算法可供选择。比如,DPM++ 2M Karras,它很好地平衡了速度和质量。 Sampling Steps: 去噪过程的采样步骤数。越多越好,但需要更长的时间。例如,25 个步骤可能适用于大多数情况。 宽度和高度:输出图像的大小。使用 v1 模型时,您应该至少将一侧设置为 512 像素。例如,对于纵横比为 2:3 的肖像图像,将宽度设置为 512,将高度设置为 768。 Batch Count: 批次数量。 Batch size:每一批次要生成的图像数量。您可以在测试提示时多生成一些,因为每个生成的图像都会有所不同。 生成的图像总数等于Batch Count乘以Batch size。 CFG scale : Classifier Free Guidance scale,用于控制模型应在多大程度上遵从您的提示。 1 – 大多忽略你的提示。3 – 更有创意。7 – 遵循提示和自由之间的良好平衡。15 – 更加遵守提示。30 – 严格按照提示操作。 下图显示了使用固定种子值时更改 CFG 的效果。一般不要将 CFG 值设置得太高或太低。如果 CFG 值太低,Stable Diffusion 将忽略您的提示。当它太高时,图像的颜色会饱和,形态较为固定。  掌握了以上基本用法,你基本上就可以随意生成点什么开始练练手了。 比如, A Photo of a cat sitting on top of a building  怎么样的Prompt是好的Prompt? 怎么样的Prompt是好的Prompt?好的Prompt的特点 描述主题时要详细具体。使用多个方括号()可增加其强度,使用[]可减小强度。艺术家名字是一个很强的风格修饰语。根据使用谨慎使用。多尝试不同样式的混合。总的来说,为了生成高质量的特定图像,你的提示文本需要包括下面列出的项目的具体描述: 主题(必填)详细具体的描述你的画作的内容。 图像类别定义了艺术品的类别。 关键词说明Portrait肖像,将图像聚焦在面部/爆头上。Digital painting数字艺术风格Concept art插画风格,二维Ultra realistic illustration非常逼真的绘图Underwater portrait水下,使用于人物,如头发漂浮效果图像风格这些关键字进一步完善了艺术风格。 关键词说明hyperrealistic超写实的,增加细节和分辨率pop-art流行艺术风格Modernist现代派,鲜艳的色彩,高对比度哪种艺术家的风格在提示中提及艺术家是一种强烈的效果。可根据需要研究他们的作品并做出明智的选择。比如,以下艺术家风格: 关键词说明John Collier19世纪肖像画家。Stanley Artgerm Lau强烈的现实主义现代绘画。Frida Kahlo卡罗的肖像风格。John Singer Sargent适合和女人像一起使用,可生成19世纪精致的衣服,有些印象派提及艺术图片网站提及艺术图片网站是一种强烈的效果,可能是因为每个网站都有其基本艺术类型。 关键词说明pixiv日本动漫风格pixabay商业库存照片风格artstation现代插画,幻想分辨率关键词说明unreal engine非常逼真,详细的 3D细节sharp focus提高分辨率8k提高分辨率,使图像更像相机拍摄效果,更逼真,但有时会导致看起来比较假。vray3D 渲染,对于物体、景观和建筑最为合适。颜色为图像添加额外的配色方案。比如: 关键词说明iridescent gold闪亮的金色silver银色vintage复古效果更多的细节描绘为您的图像添加特定细节。比如,下面这些关键词: 关键词说明dramatic富有表现力的,增加人物脸部的情绪表现力。提升照片整体潜力/可变性。silk给衣服增加丝绸效果expansive更开放的背景,而主体相对变小low angle shot从低角度拍摄god rays阳光冲破云层psychedelic迷幻绚丽的色彩注意:这里提到的一些关键词不是规则。Stable Diffusion模型非常灵活。你应该多尝试使用一些有创意的关键字组合,结果一定会惊艳到你! Seed种子种子:用于在潜在空间中生成初始随机张量的种子值。实际上,它用于控制图像的内容。生成的每个图像都有自己的种子值。如果设置为 -1,AUTOMATIC1111 每次都将使用随机种子值。 使用如下prompt生成一张穿着汉服在打太极的中国女孩: a chinese pretty girl, 20 year old, intricate details face, (doing tai chi in the morning outside:1.2), Han Chinese Clothing 假设您使用相同的提示和设置,生成了 2 个图像。分别为: 种子为2227829080的图像:  种子为2227829084的图像:  觉得图片还不错。后续,可以基于这两个种子生成更多图片,进行微调。 我们现在希望生成与这两个图像相关的混合图像。  您可以将种子设置为2227829080,将变化种子设置为 2227829084,并在 0 和 1 之间调整Variation strength变化强度。 当Variation strength变化强度从 0 增加到 1 时,人物姿势、着装和背景等都将逐渐变化。类似于“渐变色”。  你可以根据需要,设置一个合适的变化强度,多批次自动生成更多的不同动作和姿态的图像,然后从中挑选出满意的作品。   Restore Face Restore Face为恢复脸部缺陷而训练的附加模型。以下是应用Restore Face之前和之后的对比示例。  Hires. fix. Hires. fix.高分辨率修复选项应用放大器来放大图像。您觉得需要这个选项,因为Stable Diffussion的本机分辨率为512像素(对于某些v2模型为768像素)。图像太小的话,无法用于多种用途。 为什么你不能把宽度和高度设置得更高一些,比如1024像素?偏离本机分辨率会影响构图,并产生一些其它问题,比如生成具有两个头部的图像。  首先生成一个512像素的图像。然后把它放大到更大的。 ControlNet模型ControlNet为Stable Diffusion增加了控制条件。比如边缘检测和人物姿态控制。 其OpenPose检测人体关键点,如头部、肩部、手部等的位置。它对于复制人物姿势很有用。 比如输入一个跳舞的男性照片,生成姿态控制提示,然后生成你想要的具有输入人物姿势的其它图像。  这里,我们将输入一个处于思考姿态的男性图像,生成在书桌前思考的女性图像。 展开ControlNet面板,如下图所示。  0) 输入prompt: a young female, highlights in hair, thinking at desk, brown eyes, wearing white T-shirt 1) 首先将姿势图像上传 2) 选中启用复选框 3) 选择预处理器和模型, 比如OpenPose关键点检测器和相应的模型 ControlNet面板应如下所示。 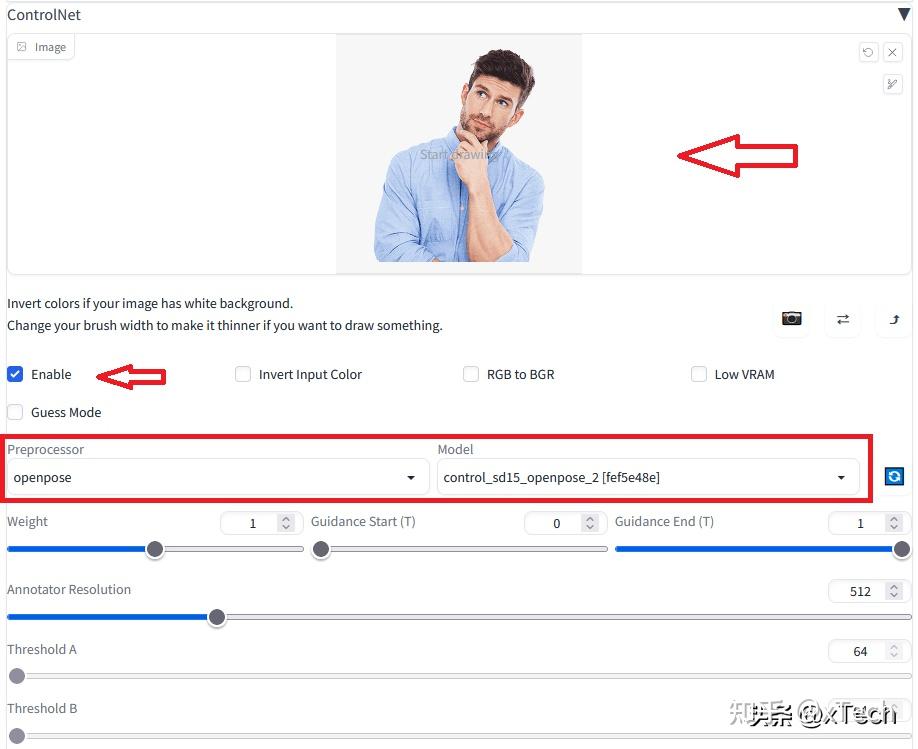 4)执行Generate   当然,你完全可以自由创作,比如:正在思考的钢铁侠,加菲猫   跳芭蕾的男人  跳芭蕾的女孩  今天大概的介绍了txt2img,接下来有空了再和大家探讨一下img2img。 还可以加入我的知识星球(AI达人星球)。 |
【本文地址】