| 中金前沿论文导读系列:Segment Anything,CV领域新进展 MetaAI在4月5日发布了SAM模型,一个通用的图像分割模型。这是大模型在CV领域的一个新的技术突破,业界甚至有人惊呼... | 您所在的位置:网站首页 › everything怎么用英语说 › 中金前沿论文导读系列:Segment Anything,CV领域新进展 MetaAI在4月5日发布了SAM模型,一个通用的图像分割模型。这是大模型在CV领域的一个新的技术突破,业界甚至有人惊呼... |
中金前沿论文导读系列:Segment Anything,CV领域新进展 MetaAI在4月5日发布了SAM模型,一个通用的图像分割模型。这是大模型在CV领域的一个新的技术突破,业界甚至有人惊呼...
|
来源:雪球App,作者: 贝叶斯韭黄,(https://xueqiu.com/3928984383/246831064) MetaAI在4月5日发布了SAM模型,一个通用的图像分割模型。这是大模型在CV领域的一个新的技术突破,业界甚至有人惊呼“CV不存在了!”我们在这里为大家做出解读和分析。 Segment Anything简介Segment Anything Model(以下简称“SAM”)为Meta最新成果。在这篇论文中,Meta构建了一个可以对任意图片进行分割的模型,并根据模型提供了一个高质量的10亿掩模图片数据集(SA-1B)。 基于网络上的大规模数据训练出来的自然语言模型(“LLM”)正在革命AI行业,其具备较强的Zero-shot和Few-shot学习能力,是泛化的通用模型。在自然语言领域,我们已经见证了GPT-4、LLAMA等多个知名模型具备上述的强大能力。但在计算机视觉领域(“CV”),相关的研究少了很多。CLIP和ALIGN两个将文本和图像连接起来的模型是这一领域亮眼的工作。基于CLIP,OpenAI进一步开发了DALL.E系列模型,将文本提示(“Prompt”)直接转换为图像。 SAM模型建立了一个可以接受文本提示、基于海量数据训练而获得泛化能力的图像分割大模型。在SAM基模型之上,通过提示工程后可以解决不同的下游分割任务。 Demo可以在这里玩到。 图:通过鼠标的悬停,可以选中任意一个物体分割出来;或者通过鼠标圈选一个框,可以提取框中的所有物体。
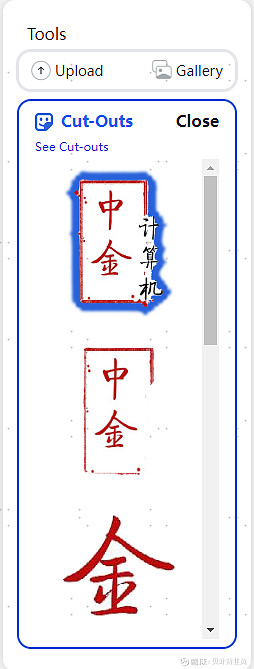
资料来源:MetaAI,中金公司研究部 图:使用Everything功能可以直接提取所有的物体,并在cut-outs里面看到它们
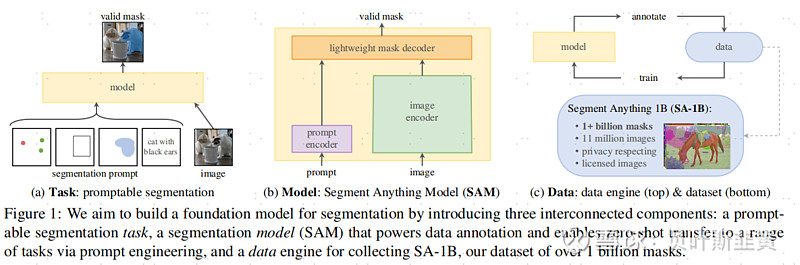
资料来源:MetaAI,中金公司研究部 官方的能力说明: (1) SAM允许用户通过单击或交互式单击要包括和排除的点来分割对象。该模型还可以通过边界框提示。 (2) 当面临分割对象的模糊性时,SAM可以输出多个有效的遮罩,这是解决实际分割问题的重要而必要的能力。 (3) SAM可以自动查找并遮罩图像中的所有对象。 (4) SAM可以在预计算图像嵌入之后,实时为任何提示生成分割遮罩,从而允许与模型进行实时交互。 什么是图像分割,为什么要图像分割?图像分割是计算机视觉中的一项重要任务,它涉及到将图像划分为多个区域或片段,每个区域或片段代表图像的一个有意义的部分。图像分割之所以重要,有几个原因,包括: ►对象识别:图像分割有助于识别和确认图像中的不同物体。通过将图像分为不同的区段,每个区段都可以被单独分析,从而更容易识别物体和它们的属性。 ►对象检测:图像分割也可以帮助检测图像中的物体,把它们从背景中分离出来。这在自动驾驶等应用中特别有用,自动驾驶汽车需要检测其他汽车、行人和障碍物。 ►图像编辑:图像分割是许多图像编辑任务中的一个重要步骤,如去除物体、颜色校正和图像合成。通过将图像划分为不同的片段,单个片段可以被修改而不影响图像的其他部分。 ►医学成像:在医学成像中,图像分割被用来从医学图像中提取特定结构或潜在病灶存在的区域。这可以帮助诊断、治疗计划和监测各种疾病。 ►便利下游任务:图像分割的下游工作包括物体识别、物体检测、物体跟踪、图像修复、图像分类和许多其他计算机视觉任务。这些任务需要准确和有效的图像分割作为预处理步骤,以便从图像中提取有意义的信息。 Segment Anything Model的设计亮点图表:SAM的基础架构包含三个关键部分,可提示的分割任务,SAM模型,和一个超过1100万张照片、超过10亿的掩膜(Mask)的数据集
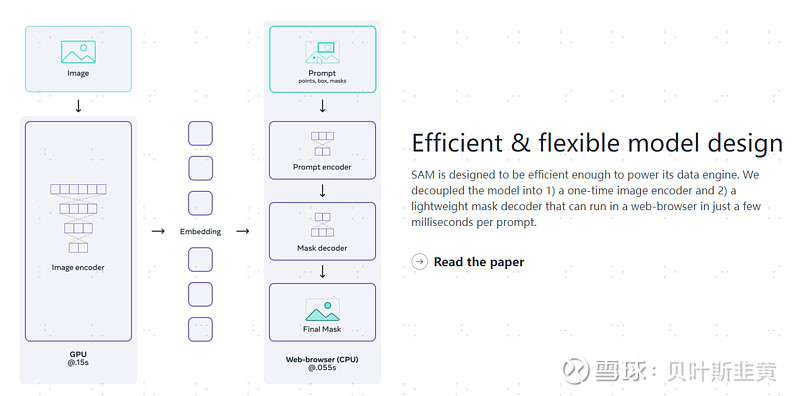
资料来源:《Segment Anything》,中金公司研究部 任务定义:SAM融合了提示学习技术——NLP领域已经大规模的使用了提示学习技术,MetaAI团队尝试将NLP领域的提示翻译为文本分割领域的提示。在文本分割领域,MetaAI定义的一个提示可以是一个勾选框,一个点,或者自然语言。 模型构建:SAM模型需要同时满足三个限制:1)灵活的提示;2)实时计算Mask(理解为一个分割出来的结果);3)支持模糊的感知能力。而SAM模型通过一个image encoder 和一个Fast prompt encoder/mask decoder优雅的解决了这个问题。 图:在打开图片的使用,0.15秒的时间计算出图片的Embeddings, 然后在网页上用CPU处理,在0.55s内即可对Prompt/mask进行轻量化的encode/decode,非常优雅的模型设计
资料来源:MetaAI Blog,中金公司研究部 图像引擎:为了实现模型的强大泛化能力(可以Zero-shot的识别几乎万事万物),SAM的训练需要庞大的分割过的图像数据,然而目前并没有这么丰富的数据集。因此MetaAI建立了一个Data engine。在第一阶段,SAM帮助标注人员来进行Mask的标注;在第二阶段,训练人员目标于增加物品的多样性,以帮助SAM可以标注万事万物。此时,SAM可以自动标注一批物体,而标注人员只要标注其他的部分即可;在最终阶段,通过在图片上施加一个点组成的矩阵来识别,SAM可以自动在一个图片上平均每张产生~100个高质量的Mask。 注意,这个模型的训练过程还是用到了专业的标注人员。但是通过交互式的注释,在第一阶段一个掩码标注平均只需要14秒时间(比COCO掩码标注快6.5倍)。 图表:SAM模型进行图像分割的示例,来自SA-1B
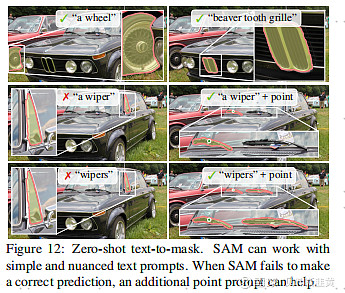
资料来源:《Segment Anything》,中金公司研究部 模型训练的成本模型训练过程中,Meta从一位版权图片提供商处获得了图片,具体的费用未被披露。在训练过程中,Meta使用了256张英伟达A100 GPU训练了68小时,相对成本并不算高昂。 模型的局限性SAM模型在Zero-shot的点击物体生成对应Mask(理解为点击一下物体,即可把他提取出来),以及边缘检测、物品发现、实例分割等项目上都有很好的表现。但在Zero-shot text-to-mask上表现一般,有时候需要人类给一个点的提示,可能表现会更好一些。MetaAI团队在论文中也承认这边的探索仍有更多的工作可以做。 实例分割 实例分割是一种计算机视觉技术,用于将图像中的每个物体实例分割成单独的对象。 边缘检测 边缘检测是一种计算机视觉技术,用于检测图像中物体之间的边界。 物体提议 物体提议是一种计算机视觉技术,用于在图像中提出可能包含物体的区域。 文字到mask 文字到Mask是一种计算机视觉技术,可以参考下方的图片 图:用文字要求SAM找到Wipers,可能会失败;但是如果给一个点的提示,它能够完整的找到整个Wiper,甚至触类旁通找到旁边的Wiper(雨刷)
资料来源:SAM Paper,中金公司研究部 SAM模型尽管表现较好,但对于垂类领域的专用模型来说,可能在精度上表现不佳。与此同时,对于一些小的连接件,可能会错误的标注出来。在边缘的精度上,也没有一些算力需求更大的算法那么精细。 图表1:SAM模型将柯基的项圈也分割了出来
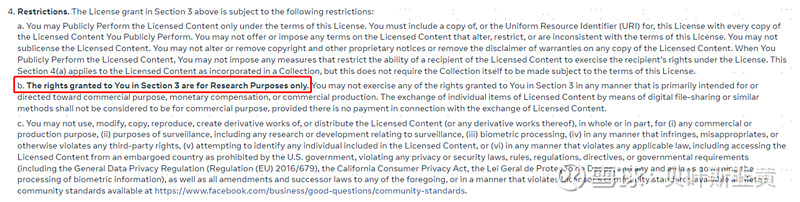
资料来源:MetaAI,中金公司研究部 License和限制SAM模型本体为Apache 2.0协议,为宽松协议,可商用,可魔改。虽然一般Meta都会额外要求不可商用,但我们目前还没看到相关的Term。 论文中注明 ,SA-1B数据集在Apache 2.0许可证下开源,但仅供研究使用。项目地址:网页链接 图表:SA-1B数据集不可商用,仅供研究使用
资料来源:MetaAI,中金公司研究部 头脑风暴:潜在用例和影响一个识别万事万物的通用CV模型要出现了?尽管目前SAM模型的Text-to-mask能力还没做的很完善(下图是一个案例),但是可能我们距离一个能够识别,并且知道自己识别了什么物体的通用模型是否更近了一步?这可能是有些人惊呼CV不存在了的原因。
众所周知,Meta在元宇宙上投入颇丰。未来,SAM算法有望根据用户的目光跟踪,随时注意到用户正在观察的物体,成为MR、XR场景下非常重要的基础交互能力。如果进一步打开想象,当我们手指物体,命令机器人、或者摄像头“把那个打开/拿给我”,机器人或者摄像头也能相应的理解我们的意思。算力提升后的SAM模型将成为元宇宙和诸多领域在用户交互上的基础能力。 预告:我们近期还会解读另外一个近期大模型领域的重磅工作,结合这两个工作来看的话,元宇宙的到来(或者抛弃链圈,我们就说XR和三维化)可能比每个人想象的都快。跟随苹果MR设备的发布,元宇宙可能迎来“文艺复兴”。
大逻辑是:CV能力的增强,利好整体CV行业应用的渗透,CV的能力越强,相关的应用就能更加的获得用户的认可,获得用户支出的倾斜。一句话来说:任何有摄像头的场景,都是受益场景! 自动驾驶:有利于加速数据标注,加速算法迭代,更快拥抱L5级自动驾驶的诞生 相关公司:中科创达、四维图新、光庭信息(未覆盖)、虹软科技(硬件组覆盖) 安防和智慧城市 相关公司:海康威视(硬件组覆盖)、大华股份(硬件组覆盖)、商汤、当虹科技、网达软件(未覆盖)、锐明技术(未覆盖)、苏州科达(未覆盖) 家庭用摄像头和机器人 相关公司:萤石网络(硬件组覆盖)、石头科技(家电组覆盖)、科沃斯(机械&家电组联合覆盖) 工业质检和工业视觉 相关公司:用友网络、创新奇智、凌云光(硬件组覆盖)、奥普特(机械组覆盖)、天准科技(硬件组覆盖)、矩子科技(未覆盖)、奥比中光(未覆盖)。 MR、XR 中科创达(IoT核心能力服务商)、中软国际、XR相关消费电子公司(详询硬件组) 其他领域数据标注:SAM模型的算法对于数据标注行业的影响显而易见,预计把握先机的龙头企业将继续凭借R&D优势冲击中小长尾企业。另外还有一些行业属于变相的数据标注,技术的发展意味着思有望大幅降低成本。 相关公司:海天瑞声,四维图新,航天宏图(航空航天组覆盖) 基础算法:对于CV基础算法企业,来自海外大厂和开源的竞争愈发明显,行业集中度提升成为必然方向,需要关注领先大厂。 相关公司:商汤、百度、虹软科技 MLOps:永远的掘金卖铲,只要企业(不是大厂)用更多的AI,无论是CV还是NLP,MLOps永远受益 相关公司:星环科技,万达信息,中国软件 $海康威视(SZ002415)$ $大华股份(SZ002236)$ $寒武纪-U(SH688256)$ |








【本文地址】