| Druid入门到实战及面试 | 您所在的位置:网站首页 › druid查询zk耗时 › Druid入门到实战及面试 |
Druid入门到实战及面试
|
第一章、druid入门
1.什么是Druid?
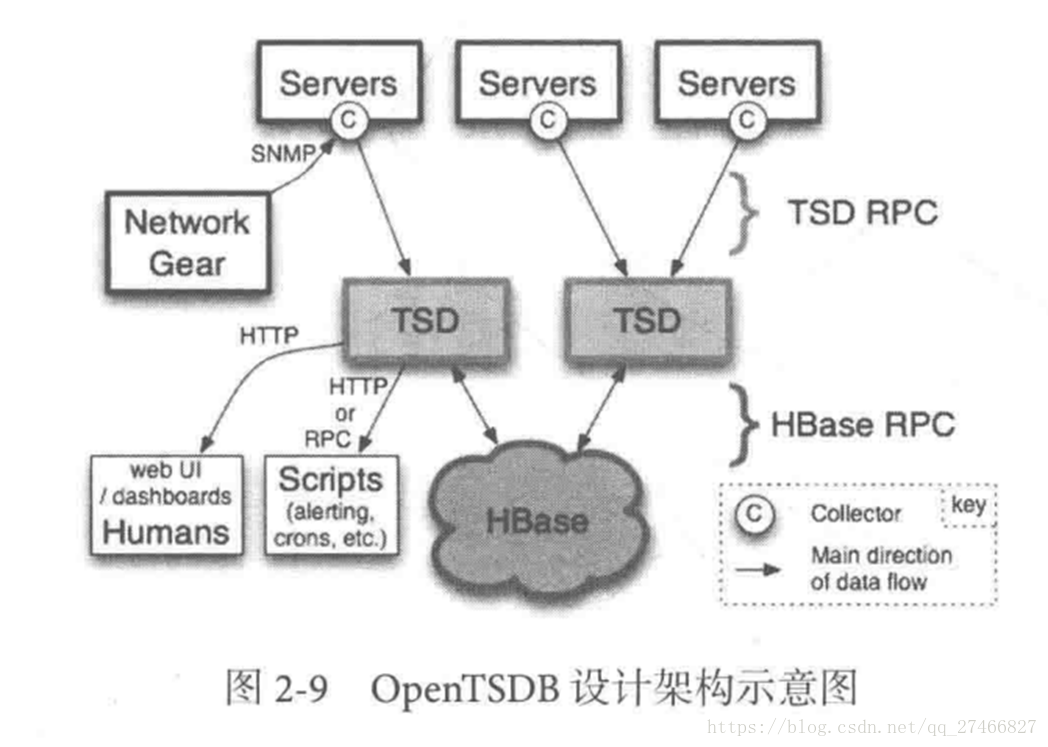
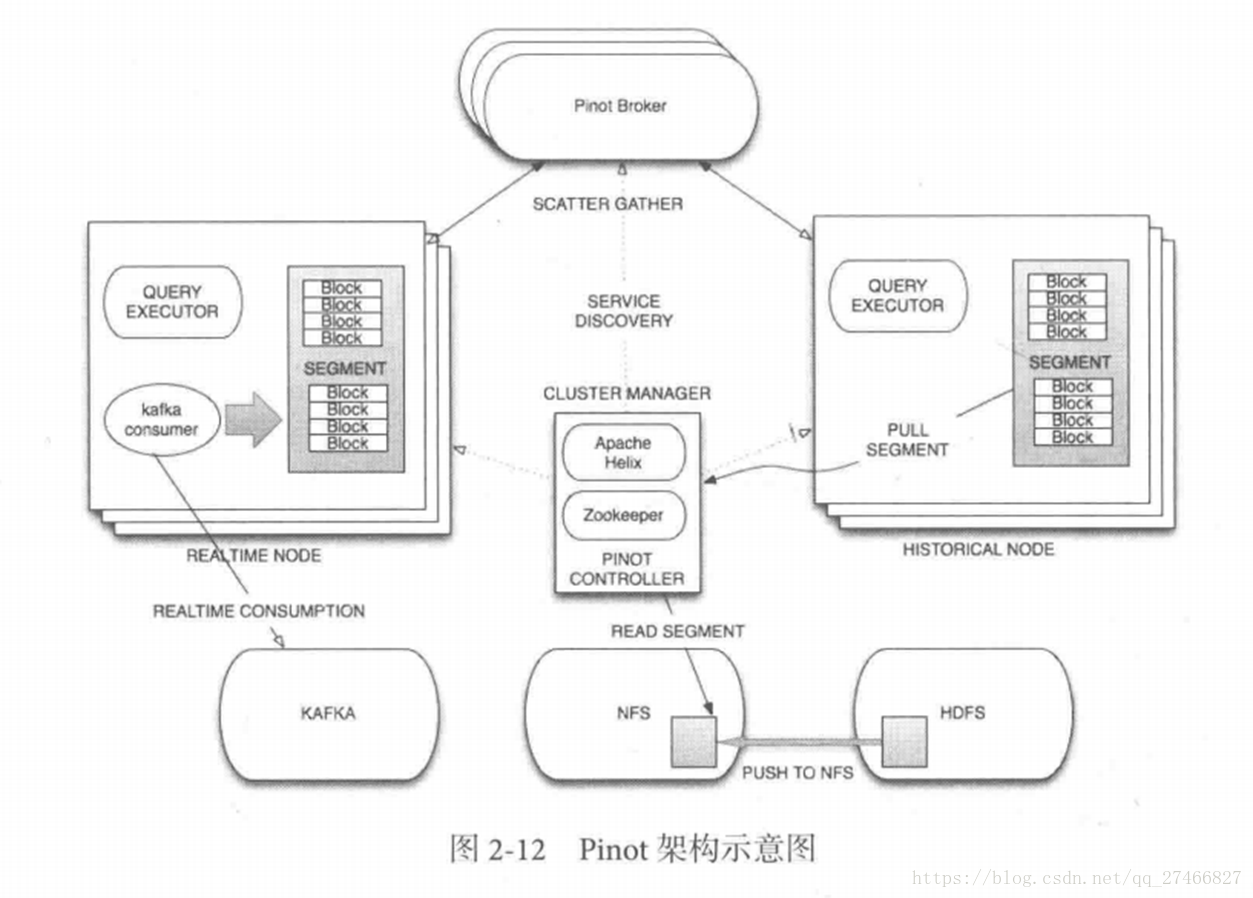
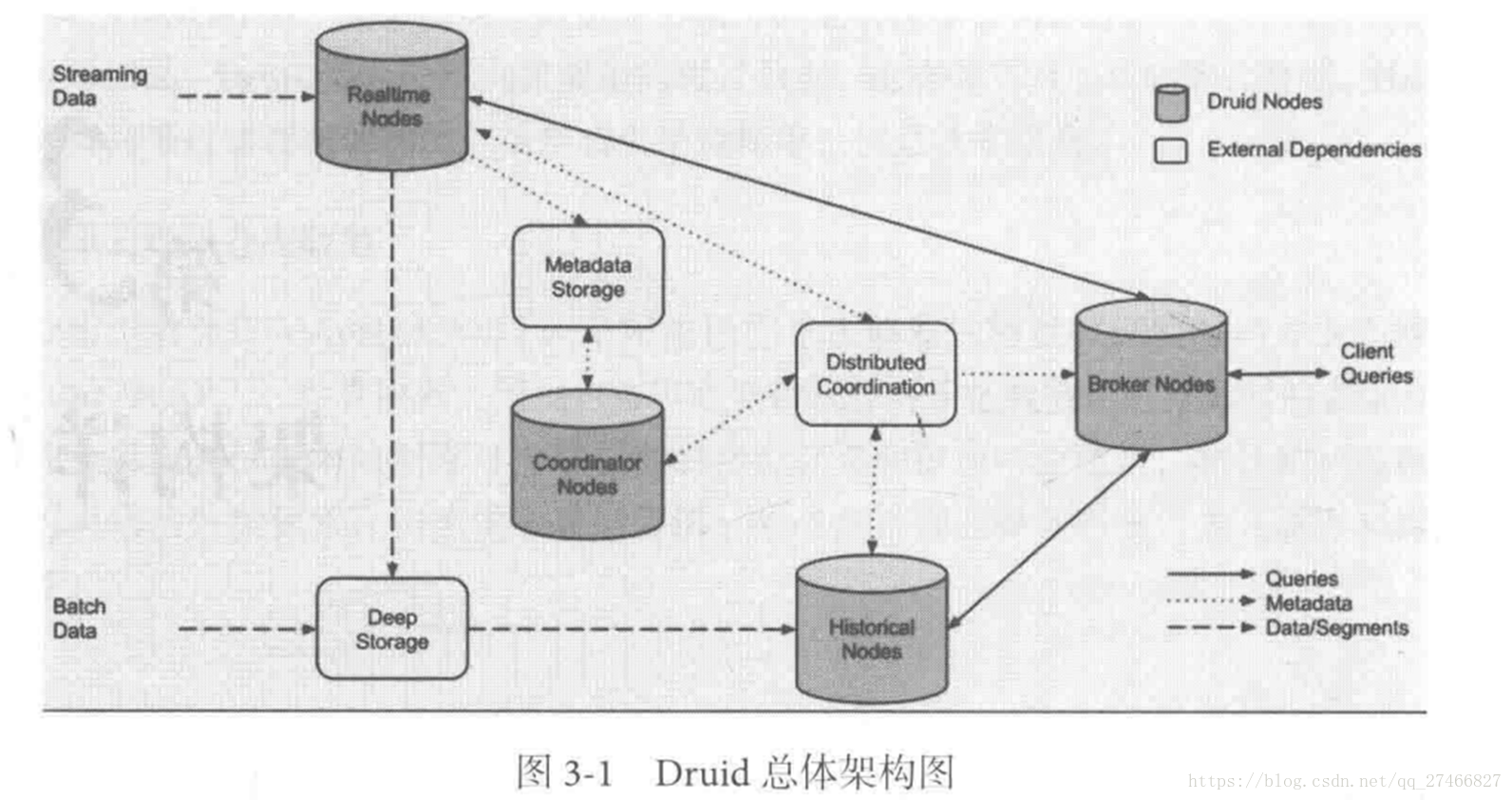
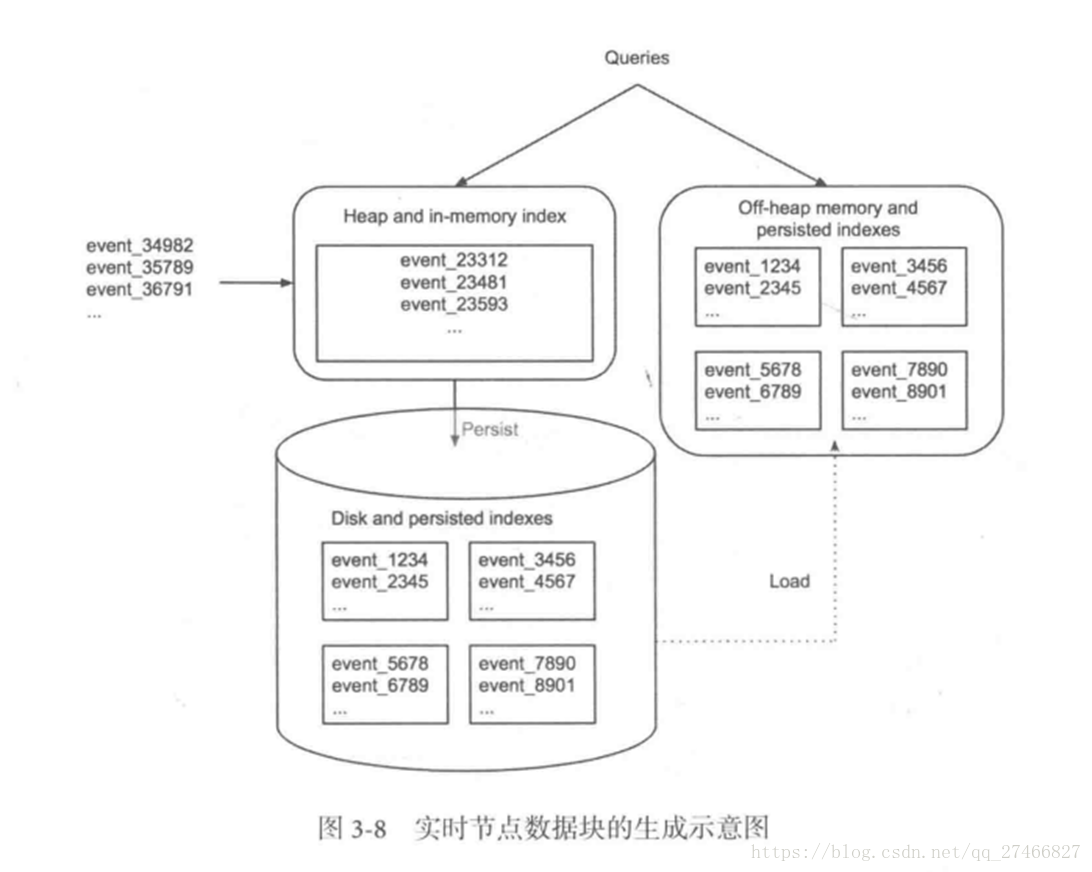
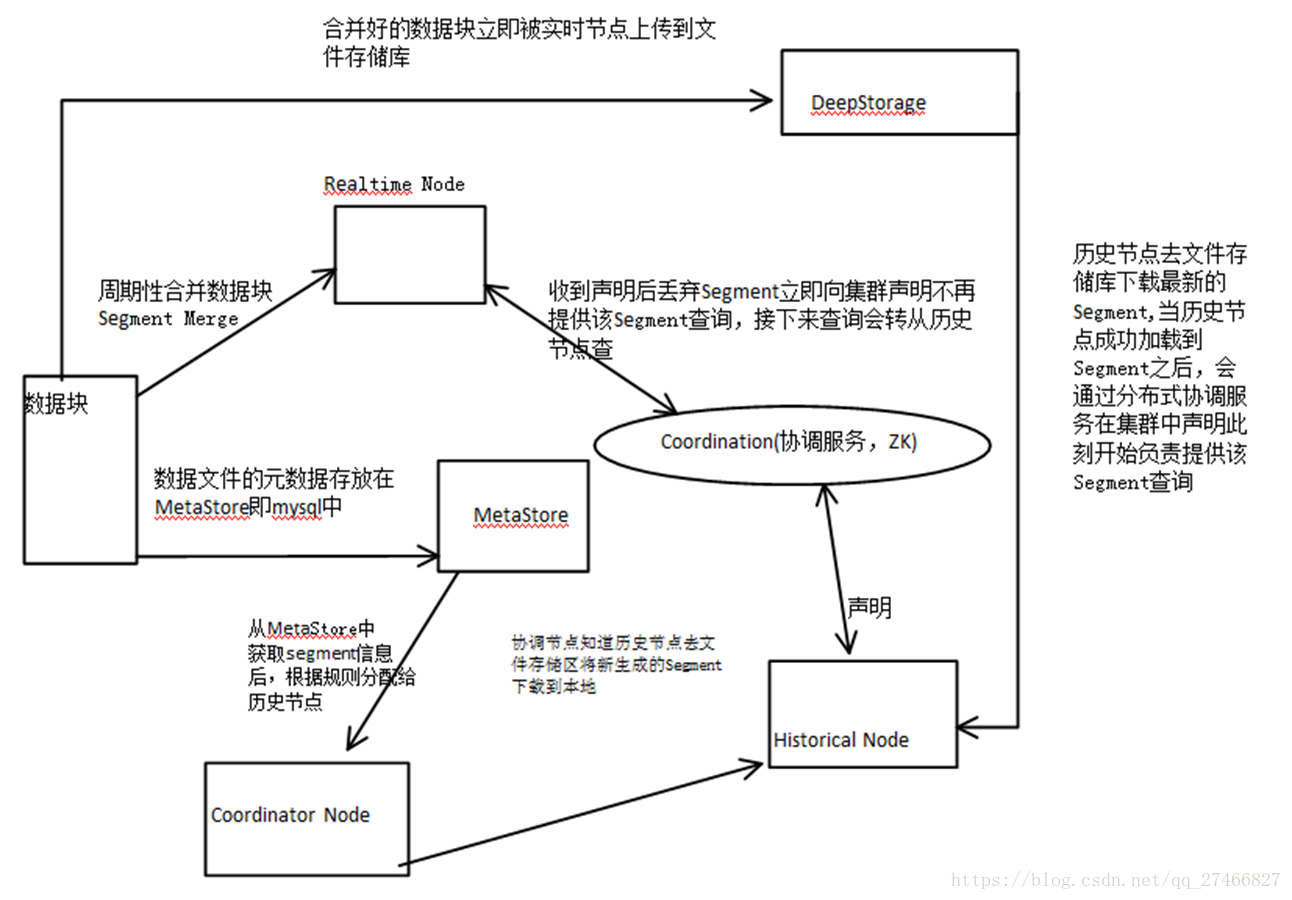
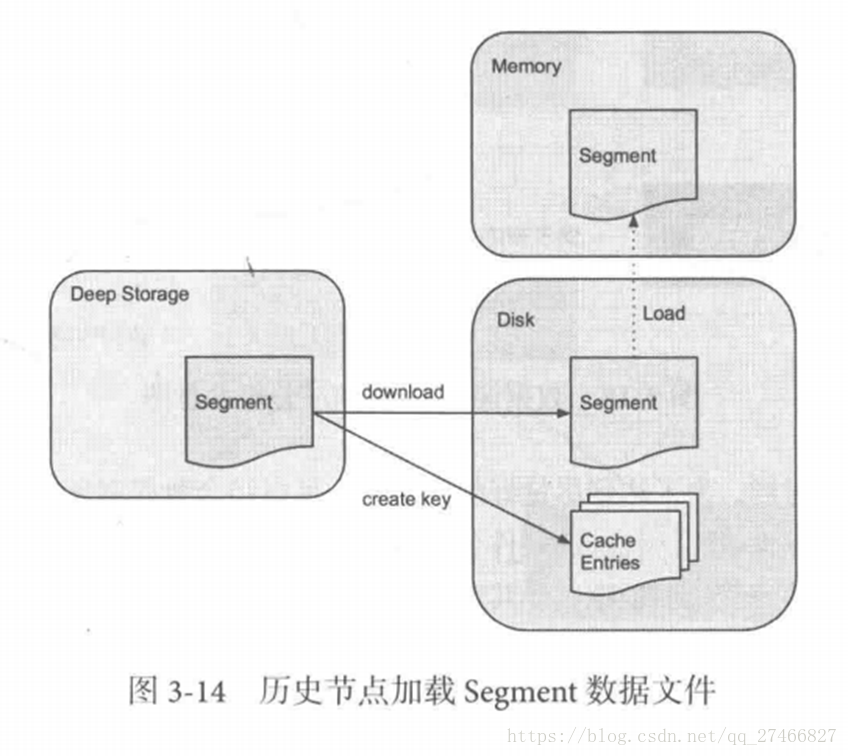
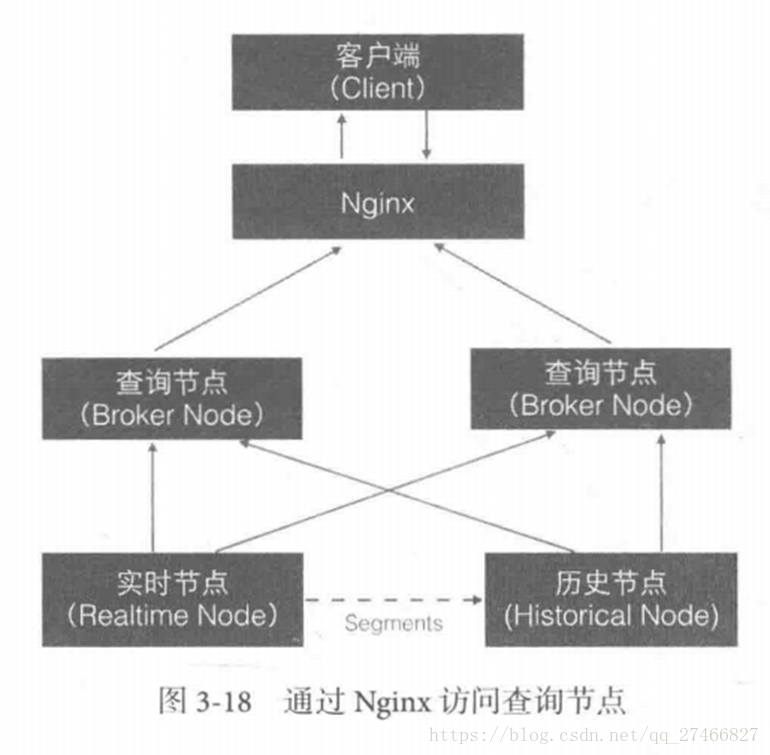
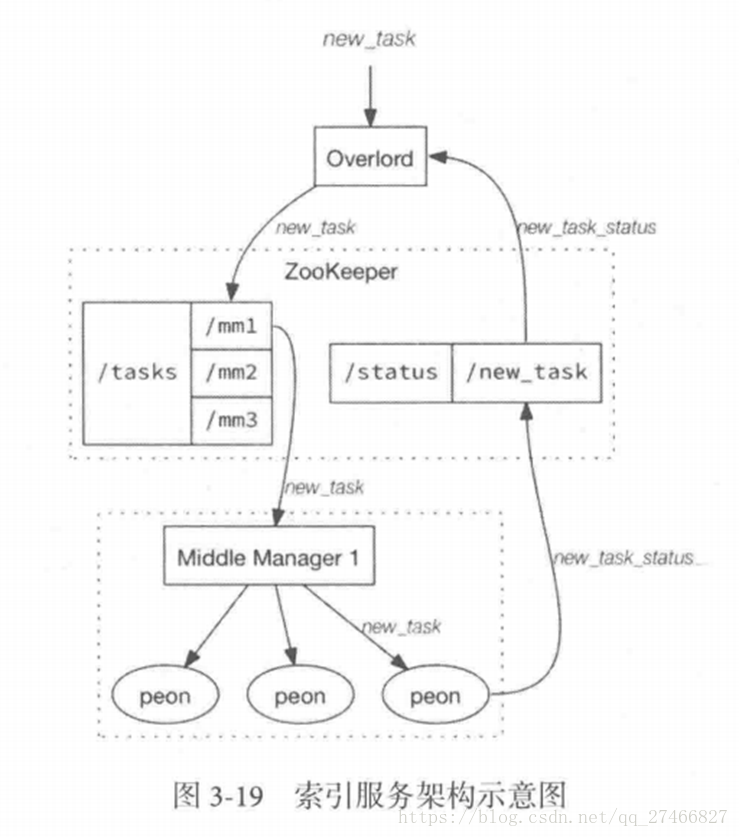
Druid是一个高效的数据查询系统,主要解决的是对于大量的基于时序的数据进行聚合查询。数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。 1、Druid采用的架构:shared-nothing架构与lambda架构 2、Druid设计三个原则:1.快速查询(Fast Query) : 部分数据聚合(Partial Aggregate) + 内存华(In-Memory) + 索引(Index) 2.水平拓展能力(Horizontal Scalability):分布式数据(Distributed data)+并行化查询(Parallelizable Query) 3.实时分析(Realtime Analytics):Immutable Past , Append-Only Future 3.Druid的技术特点数据吞吐量大 支持流式数据摄入和实时 查询灵活且快速 4.Druid基本概念:Druid在数据摄入之前,首先要定义一个数据源(DataSource,类似于数据库中表的概念) Druid是一个分布式数据分析平台,也是一个时序数据库 1.数据格式数据集合(时间列,维度列,指标列) 1、数据结构:基于DataSource与Segment的数据结构,DataSource相当于关系型数据库中的表。 DataSource包含: 时间列(TimeStamp):标识每行数据的时间值 维度列(Dimension):标识数据行的各个类别信息 指标列(Metric):用于聚合和计算的列 2、Segment结构:DataSource是逻辑结构,而Segment是数据实际存储的物理结构,Druid通过Segment实现对数据的横纵切割操作。 横向切割:通过设置在segmentGranularity参数,Druid将不同时间范围内的数据存储在不同Segment数据块中。 纵向切割:在Segment中面向列进行数据压缩处理 3、设置合理的GranularitysegmentGranularity:segment的组成粒度。 queryGranularity :segment的聚合粒度。 queryGranularity 小于等于 segmentGranularity 若segmentGranularity = day,那么Druid会按照天把不同天的数据存储在不同的Segment中。 若queryGranularity =none,可以查询所有粒度,queryGranularity = hour只能查询>=hour粒度的数据 2.数据摄入实时数据摄入 批处理数据摄入 3.数据查询原生查询,采用JSON格式,通过http传送 4.时序数据库 1.OpenTSDB开源的时序数据库,支持数千亿的数据点,并提供精确的数据查询功能 采用java编写,通过基于Hbase的存储实现横向拓展 设计思路:利用Hbase的key存储一些tag信息,将同一小时的数据放在一行存储,提高了查询速度 架构示意图: 接近Druid的系统 Pinot也采用了Lambda架构,将实时流和批处理数据分开处理 Realtime Node处理实时数据查询 Historical Node处理历史数据 技术特点: 面向列式存储的数据库,支持多种压缩技术 可插入的索引技术 — Sorted index ,Bitmap index, Inverted index 可以根据Query和Segment元数据进行查询和执行计划的优化 从kafka实时灌入数据和从hadoop的批量数据灌入 类似于SQL的查询语言和各种常用聚合 支持多值字段 水平拓展和容错 Pinot架构图: Druid包含以下四个节点: 实时节点(Realtime ):即时摄入实时数据,以及生成Segment数据文件 实时节点负责消费实时数据,实时数据首先会被直接加载进实时节点内存中的堆结构缓存区,当条件满足时, 缓存区的数据会被冲写到硬盘上形成一个数据块(Segment Split),同时实时节点又会立即将新生成的数据库加载到内存的非堆区, 因此无论是堆结构缓存区还是非堆区里的数据都能被查询节点(Broker Node)查询 历史节点(Historical Node):加载已经生成好的文件,以供数据查询 查询节点(Broker Node):对外提供数据查询服务,并同时从实时节点和历史节点查询数据,合并后返回给调用方 协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期 集群还依赖三类外部依赖 元数据库(Metastore):存储Druid集群的原数据信息,比如Segment的相关信息,一般用MySql或PostgreSQL 分布式协调服务(Coordination):为Druid集群提供一致性协调服务的组件,通常为Zookeeper 数据文件存储系统(DeepStorage):存放生成的Segment文件,并供历史节点下载。对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS或NFS 实时节点数据块的生成示意图: 数据块的流向: Realtime Node 实时节点: 1.通过Firehose来消费实时数据,Firehose是Druid中消费实时数据的模型 2.实时节点会通过一个用于生成Segment数据文件的模块Plumber(具体实现有RealtimePlumber等)按照指定的周期,按时将本周起生产的所有数据块合并成一个大的Segment文件 Historical Node历史节点 历史节点在启动的时候 : 1、会去检查自己本地缓存中已经存在的Segment数据文件 2、从DeepStorege中下载属于自己但是目前不在自己本地磁盘上的Segment数据文件 无论何种查询,历史节点会首先将相关Segment数据文件从磁盘加载到内存,然后在提供查询 Broker Node节点: Druid提供两类介质作为Cache以供选择 外部Cache,比如Memcached 本地Cache,比如查询节点或历史节点的内存作为cache 高可用性: 通过Nginx来负载均衡查询节点(Broker Node) 协调节点: 协调节点(Coordinator Node)负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期 6.索引服务1.其中主节点:overlord 两种运行模式: 本地模式(Local Mode):默认模式,主节点负责集群的任务协调分配工作,也能够负责启动一些苦工(Peon)来完成一部分具体任务 远程模式(Remote):该模式下,主节点与从节点运行在不同的节点上,它仅负责集群的任务协调分配工作,不负责完成具体的任务,主节点提供RESTful的访问方法,因此客户端可以通过HTTP POST 请求向主节点提交任务。 命令格式如下: http://:port/druid/indexer/v1/task 删除任务:http://:port/druid/indexer/v1/task/{taskId}/shutdown 控制台:http://:port/console.html 2.从节点:Middle Manager索引服务的工作节点,负责接收主节点的分配的任务,然后启动相关的苦工即独立的JVM来完成具体的任务 这样的架构与Hadoop YARN相似 主节点相当于Yarn的ResourceManager,负责集群资源管理,与任务分配 从节点相当于Yarn的NodeManager,负责管理独立节点的资源并接受任务 Peon(苦工)相当于Yarn的Container,启动在具体节点上负责具体任务的执行 问题: 由于老版本的Druid使用pull方式消费kafka数据,使用kafka consumer group来共同消费一个kafka topic的数据,各个节点会负责独立消费一个或多个该topic所包含的Partition数据,并保证同一个Partition不会被多于一个的实时节点消费。每当一个实时节点完成部分数据的消费后,会主动将消费进度(kafka topic offset)提交到Zookeeper集群。 当节点不可用时,该kafka consumer group 会立即在组内对所有可用的节点进行partition重新分配,接着所有节点将会根据记录在zk集群中每一个partition的offset来继续消费未曾消费的数据,从而保证所有数据在任何时候都会被Druid集群至少消费一次。 这样虽然能保证不可用节点未消费的partition会被其余工作的节点消费掉,但是不可用节点上已经消费的数据,尚未被传送到DeepStoreage上且未被历史节点下载的Segment数据却会被集群遗漏,这是基于kafka-eight Firehose消费方式的一种缺陷。 解决方案: 1.让不可用节点恢复重新回到集群成为可用节点,重启后会将之前已经生成但未上传的Segment数据文件统统加载回来,并最终合并传送到DeepStoreage,保证数据完整性 2.使用Tranquility与Indexing Service,对kafka的数据进行精确的消费与备份。 由于Tranquility可以通过push的方式将指定数据推向Druid集群,因此它可以同时对同一个partition制造多个副本。所以当某个数据消费失败时候,系统依然可以准确的选择使用另外一个相同的任务所创建的Segment数据库 7、Druid快速入门硬件及软件要求: Java 8 or higher Linux, Mac OS X, or other Unix-like OS (Windows is not supported) 8G of RAM 2 vCPUs 1、下载解压缩软件包curl -O http://static.druid.io/artifacts/releases/druid-0.12.3-bin.tar.gztar -xzf druid-0.12.3-bin.tar.gzcd druid-0.12.3 压缩包包含如下目录: LICENSE - license文件. bin/ - 快速启动相关脚本. conf/* - 为集群安装提供的配置模板. conf-quickstart/* - 快速入门配置文件. extensions/* - 所有Druid扩展文件. hadoop-dependencies/* - Druid Hadoop依赖文件. lib/* - 所有Druid核心软件包. quickstart/* - quickstart相关文件目录. 2、下载教程示例curl -O http://druid.io/docs/0.12.3/tutorials/tutorial-examples.tar.gztar zxvf tutorial-examples.tar.gz 3、启动zookeeper curl http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz -o zookeeper-3.4.12.tar.gztar -xzf zookeeper-3.4.12.tar.gzcd zookeeper-3.4.12cp conf/zoo_sample.cfg conf/zoo.cfg./bin/zkServer.sh start 4、启动Druid服务 在druid-0.12.3目录下,执行如下命令 bin/init init会做一些初始化工作,脚本内容如下: #!/bin/bash -eugzip -c -d quickstart/wikiticker-2015-09-12-sampled.json.gz > "quickstart/wikiticker-2015-09-12-sampled.json"LOG_DIR=varmkdir logmkdir -p $LOG_DIR/tmp;mkdir -p $LOG_DIR/druid/indexing-logs;mkdir -p $LOG_DIR/druid/segments;mkdir -p $LOG_DIR/druid/segment-cache;mkdir -p $LOG_DIR/druid/task;mkdir -p $LOG_DIR/druid/hadoop-tmp;mkdir -p $LOG_DIR/druid/pids; 在不同的终端窗口启动Druid进程,本教程在同一个操作系统运行所有Druid进程,在大型分布式生产集群环境中,部分Druid进程仍可以部署在一起。 java `cat examples/conf/druid/coordinator/jvm.config | xargs` -cp "examples/conf/druid/_common:examples/conf/druid/_common/hadoop-xml:examples/conf/druid/coordinator:lib/*" io.druid.cli.Main server coordinatorjava `cat examples/conf/druid/overlord/jvm.config | xargs` -cp "examples/conf/druid/_common:examples/conf/druid/_common/hadoop-xml:examples/conf/druid/overlord:lib/*" io.druid.cli.Main server overlordjava `cat examples/conf/druid/historical/jvm.config | xargs` -cp "examples/conf/druid/_common:examples/conf/druid/_common/hadoop-xml:examples/conf/druid/historical:lib/*" io.druid.cli.Main server historicaljava `cat examples/conf/druid/middleManager/jvm.config | xargs` -cp "examples/conf/druid/_common:examples/conf/druid/_common/hadoop-xml:examples/conf/druid/middleManager:lib/*" io.druid.cli.Main server middleManagerjava `cat examples/conf/druid/broker/jvm.config | xargs` -cp "examples/conf/druid/_common:examples/conf/druid/_common/hadoop-xml:examples/conf/druid/broker:lib/*" io.druid.cli.Main server broker jvm.config为java进程运行参数配置,cat coordinator/jvm.config输出如下: -server-Xms256m-Xmx256m-Duser.timezone=UTC-Dfile.encoding=UTF-8-Djava.io.tmpdir=var/tmp-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager-Dderby.stream.error.file=var/druid/derby.log 以上命令在不同终端窗口运行,分别启动了coordinator、overlord、historical、middleManager、broker进程。 5、重置Druid所有持久化状态,如集群元数据存储和服务的segments都会保存在druid-0.12.3/var目录下. 如果你想停止服务,CTRL-C退出运行中的java进程。假如希望停止服务后,以初始化状态启动服务,删除log和var目录,再跑一遍init脚本,然后关闭Zookeeper,删除Zookeeper的数据目录/tmp/zookeeper。 在druid-0.12.3 目录下: rm -rf logrm -rf varbin/init 假如你学习了Loading stream data from Kafka教程,在关闭Zookeeper之前你需要先关闭Kafka,删除Kafka日志目录/tmp/kafka-logs Ctrl-C 关闭Kafka broker,删除日志目录: rm -rf /tmp/kafka-logs 现在关闭Zookeeper,清理状态,在zookeeper-3.4.12目录下: ./bin/zkServer.sh stoprm -rf /tmp/zookeeper 清理了Druid和Zookeeper状态数据后,重启Zookeeper和Druid服务。 6、数据集如下数据加载教程中,我们会使用到一份数据文件,Druid包根目录下的quickstart/wikiticker-2015-09-12-sampled.json.gz,文件内容包含了2015-09-12这一天Wikipedia页面编辑事件。页面编辑事件以json对象格式存储于text文件中。 数据包含了如下列: added channel cityName comment countryIsoCode countryName deleted delta isAnonymous isMinor isNew isRobot isUnpatrolled metroCode namespace page regionIsoCode regionName user 如下为一条示例数据: { "timestamp":"2015-09-12T20:03:45.018Z", "channel":"#en.wikipedia", "namespace":"Main" "page":"Spider-Man's powers and equipment", "user":"foobar", "comment":"/* Artificial web-shooters */", "cityName":"New York", "regionName":"New York", "regionIsoCode":"NY", "countryName":"United States", "countryIsoCode":"US", "isAnonymous":false, "isNew":false, "isMinor":false, "isRobot":false, "isUnpatrolled":false, "added":99, "delta":99, "deleted":0,} 7、从文件中夹在数据 1) 准备数据、定义数据摄取任务 A data load is initiated by submitting an ingestion task spec to the Druid overlord. For this tutorial, we'll be loading the sample Wikipedia page edits data. 向Druid overlord提交一个数据摄取任务,即完成了数据的初始化,如下我们会加载Wikipedia页面编辑数据。 examples/wikipedia-index.json定义了一个数据摄入任务,该任务读取quickstart/wikiticker-2015-09-12-sampled.json.gz中数据: { "type" : "index", "spec" : { "dataSchema" : { "dataSource" : "wikipedia", "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor", "isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName", "user", { "name": "added", "type": "long" }, { "name": "deleted", "type": "long" }, { "name": "delta", "type": "long" } ] }, "timestampSpec": { "column": "time", "format": "iso" } } }, "metricsSpec" : [], "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "day", "queryGranularity" : "none", "intervals" : ["2015-09-12/2015-09-13"], "rollup" : false } }, "ioConfig" : { "type" : "index", "firehose" : { "type" : "local", "baseDir" : "quickstart/", "filter" : "wikiticker-2015-09-12-sampled.json.gz" }, "appendToExisting" : false }, "tuningConfig" : { "type" : "index", "targetPartitionSize" : 5000000, "maxRowsInMemory" : 25000, "forceExtendableShardSpecs" : true } }} 如上定义,创建了一个名为"wikipedia"的数据源. 2)加载批量数据在druid-0.12.3 目录下,通过POST方式,提交数据摄取任务: curl -X 'POST' -H 'Content-Type:application/json' -d @examples/wikipedia-index.json http://localhost:8090/druid/indexer/v1/task 假如任务提交成功,控制台将会打印任务ID: {"task":"index_wikipedia_2018-06-09T21:30:32.802Z"} 可至overlord控制台http://localhost:8090/console.html查看你已提交的数据摄取任务的状态,可以周期性地刷新控制台,当任务成功时,你可以看到任务的状态变为"SUCCESS" 当摄取任务结束,数据将会被historical节点加载,且在一两分钟内可被查询到,你可以通过coordinator控制台监控数据加载进度,当控制台http://localhost:8081/#/数据源“ wikipedia”带有一个蓝色圈圈时表明"fully available"
Druid是一个非常优秀的数据库连接池。在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource。 Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。 Druid是一个JDBC组件,它包括三个部分: 基于Filter-Chain模式的插件体系。 DruidDataSource 高效可管理的数据库连接池。 SQLParser 2、Druid的功能 1、兼容DBCPDruid提供了一个高效、功能强大、可扩展性好的数据库连接池。从DBCP迁移到Druid,只需要修改数据源的实现类就可以了。 2、强大的监控特性Druid内置了一个功能强大的StatFilter插件可以监控数据库访问性能,可以清楚知道连接池和SQL的工作情况。 监控SQL的执行时间、ResultSet持有时间、返回行数、更新行数、错误次数、错误堆栈信息。 SQL执行的耗时区间分布。什么是耗时区间分布呢?比如说,某个SQL执行了1000次,其中0-1毫秒区间50次,1-10毫秒800次,10-100毫秒100次,100-1000毫秒30次,1-10秒15次,10秒以上5次。通过耗时区间分布,能够非常清楚知道SQL的执行耗时情况。 监控连接池的物理连接创建和销毁次数、逻辑连接的申请和关闭次数、非空等待次数、PSCache命中率等。 3、数据库密码加密直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。 4、SQL执行日志Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。 3、扩展JDBC如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter机制,很方便编写JDBC层的扩展插件。 Druid在DruidDataSourc和ProxyDriver上提供了Filter-Chain模式的扩展API,类似Serlvet的Filter,配置Filter拦截JDBC的方法调用。 4、SQLParserSQL Parser是Druid的一个重要组成部分,它提供了MySql、Oracle、Postgresql、SQL-92的SQL的完整支持,这是一个手写的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象语法树很方便。 简单SQL语句用时10微秒以内,复杂SQL用时30微秒。 通过Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如防御SQL注入(WallFilter)、合并统计没有参数化的SQL(StatFilter的mergeSql)、SQL格式化、分库分表。 table th:first-of-type { width: 100px;} 5、Druid的配置详解 配置缺省值说明 name 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 url 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto username 连接数据库的用户名 password 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 driverClassName 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName initialSize 0 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 maxActive 8 最大连接池数量 maxIdle 8 已经不再使用,配置了也没效果 minIdle 最小连接池数量 maxWait 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 poolPreparedStatements false 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 maxPoolPreparedStatementPerConnectionSize -1 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 validationQuery 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 validationQueryTimeout 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 testOnBorrow true 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 testOnReturn false 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 testWhileIdle false 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 timeBetweenEvictionRunsMillis 1分钟(1.0.14) 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 numTestsPerEvictionRun 30分钟(1.0.14) 不再使用,一个DruidDataSource只支持一个EvictionRun minEvictableIdleTimeMillis 连接保持空闲而不被驱逐的最长时间 connectionInitSqls 物理连接初始化的时候执行的sql exceptionSorter 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 filters 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall proxyFilters 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 6、项目实践我们使用的是Spring boot + mybatis + Druid(自己定制)的架构 1、导入依赖包mysql mysql-connector-java org.mybatis.spring.boot mybatis-spring-boot-starter 1.3.0 com.github.pagehelper pagehelper-spring-boot-starter 1.1.1 com.alibaba druid 1.0.25 2、配置数据源 目前Spring Boot中默认支持的连接池有dbcp,dbcp2, tomcat, hikari四种连接池。 由于Druid暂时不在Spring Bootz中的直接支持,故需要进行配置信息的定制: 3、新建配置类package com.xiaolyuh.config;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.stereotype.Component;@Component@ConfigurationProperties(prefix = "spring.datasource.druid")public class DruidDataSourceProperty { // 数据库配置 private String url; private String username; private String password; private String driverClassName; // 初始化大小,最小,最大 private int initialSize = 0; private int minIdle; private int maxActive = 8; // 配置获取连接等待超时的时间 private int maxWait; // 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 private int timeBetweenEvictionRunsMillis = 1000 * 60; // 配置一个连接在池中最小生存的时间,单位是毫秒 private int minEvictableIdleTimeMillis = 1000 * 60 * 30; // 检测连接是否有效的sql private String validationQuery; private boolean testWhileIdle = false; private boolean testOnBorrow = true; private boolean testOnReturn = false; // PSCache Mysql下建议关闭 private boolean poolPreparedStatements = false; private int maxPoolPreparedStatementPerConnectionSize = - 1; // 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 private String filters; // 合并多个DruidDataSource的监控数据 private boolean useGlobalDataSourceStat = false; private String connectionProperties; public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return |

【本文地址】