| 深度学习图像分类(六):Stochastic | 您所在的位置:网站首页 › dropout取值 › 深度学习图像分类(六):Stochastic |
深度学习图像分类(六):Stochastic
深度学习图像分类(六):Stochastic_Depth_Net
 Arwin(Haowen Yu)
分类:机器学习
发布时间 2022.06.29阅读数 955 评论数 0
Arwin(Haowen Yu)
分类:机器学习
发布时间 2022.06.29阅读数 955 评论数 0
文章目录深度学习图像分类(六):Stochastic_Depth_Net前言一、Motivation二、核心结构:Drop Path二、优点与结论三、代码实现总结前言Stochastic Depth(随机深度网络),2016年清华的黄高在ECCV发表(妥妥的CV大佬),他后面也发表了DenseNet(2017年cv的best paper,后面有单独的博文介绍),Deep Networks with Stochastic Depth等,他在训练时对很深的ResNet做了一些压缩和剪枝,随机丢掉一些层,优化了训练速度和性能。一定程度上证明了ResNet太深了,有些层是没必要的;同时也证明了ResNet的恒等映射思想确实有效(ResNet不熟悉的同学可以看我之前的博文)。 一、Motivation作者在探讨太深的网络是否必要,比如:深度(残差)网络中是不是所有的层都是必要的?是不是有很多层是冗余的?这些分支里权重值相对于别的层可能非常小。 实验方法 :随机深度简单解释就是通过在训练过程中随机丢掉一些层,来优化深度残差网络的训练过程。网络变得简单一点了。 实现方法:Drop path用随机变量和线性衰减的生存概率原则来随机丢弃层,在训练时缩小的深度(随机在ResNet的基础上pass掉一些层),较少训练时间,提高训练性能;在预测时再恢复原本的深度。 换句话说,这里的Drop path 与 AelxNet中提出的Dropout大同小异;只是两者的作用对象不同:Dropout是作用在神经元级别上的;而Drop path比较高级,其是作用在网络的层级结构上的。 二、核心结构:Drop Path原始的ResNet结构:f 是卷积部分(残差),id 是原来部分(恒等映射),把这两部分求和,再激活,得到输出。 Drop Path:训练时,加入了随机变量 b(伯努利随机变量),把 b*f,对整个ResBlock卷积部分做了随机丢弃。果b = 1,则简化为原始的ResNet结构;如果b = 0,则这个ResBlock未被激活,降为恒等函数。 伯努利分布(0-1分布),它的随机变量只取0或1,0频率是1−p,1的频率是p。 生存概率 p,p就是b=1的频率,决定了随机变量b取值为1的频繁程度,也就是给每个block的残差都加上了一个概率p,整个网络中前面的层更重要。 一种方法是将它设置为平滑函数,从 p0=1 简单线性衰减到 pL=0.5,实验得出这种线性衰减最好,一般设为pL = 0.5。总共有L个block. 如图将“线性衰减规律”应用于每一大层的生存概率,由于较早的层会提取低级特征,而这些低级特征会被后面的层所利用,所以这些层不应该频繁地被丢弃。最终 p 生成的规则就变成了这样: 在测试过程(推理预测)中,所有的block都将保持被激活状态,以充分利用整个长度网络的所有模型容量。而且每个block都将根据其在训练中的生存概率p进行重新调整。即训练时的每个block的残差的概率,在预测时变成了这个block的残差的权重。正向传播更新规则变为(ResNet的block被重新定义为):
总结Deep Networks with Stochastic Depth 这篇论文的创新点不在于新的网络模型,而是新的正则化方法。Drop path方法在后期的模型中被广泛应用,例如VIT, swin-Transformer等等。它与DenseNet有异曲同工之妙(后面会有专门的博文介绍),但是DenseNet太占用内存了(即便网络参数量少),这可能也是为什么DenseNet参数少,比ResNet性能好,但是,还没有ResNet流行的原因。而Drop path就可以看成一种折中的手段,因此被后续模型不断借鉴使用。 深度学习Stochastic_Depth_Net
打赏 0 点赞 0 收藏 0 分享 微信 微博 QQ 图片 上一篇:深度学习图像分类(五): ResNet 下一篇:深度学习图像分类(七):DenseNet |

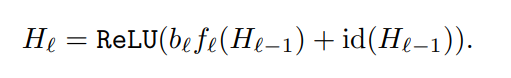

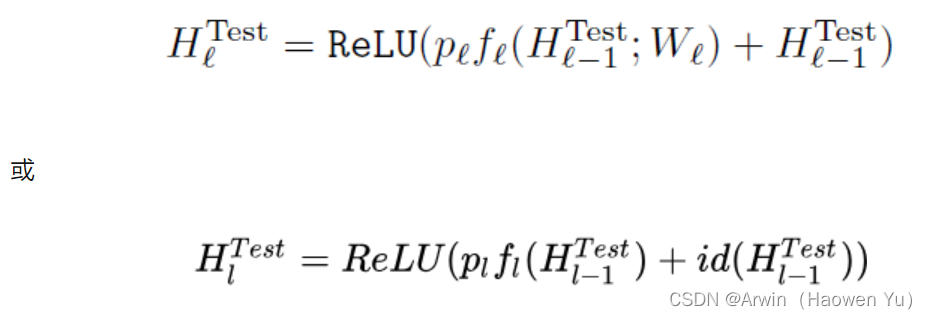 二、优点与结论大大减少了训练时间较少了深度,增强了反向传播的梯度利用不同的深度训练,最终相当于潜在地融合了多个不同深度的网络,性能提升了(跟后来2017的best paper:DenseNet的作用有异曲同工之妙,或许这就是研究的过程吧,厚积薄发)可以使得网络更深,甚至超过1200层,仍然可以在CIFAR-10上产生有意义的测试误差改善(4.91%)在cifar-10, cifar-100, SVHN 上超过了 ResNet论文测试结果ResNet的普通版和Stochastic_Depth版的比较,可见精度和速度都提高了。
二、优点与结论大大减少了训练时间较少了深度,增强了反向传播的梯度利用不同的深度训练,最终相当于潜在地融合了多个不同深度的网络,性能提升了(跟后来2017的best paper:DenseNet的作用有异曲同工之妙,或许这就是研究的过程吧,厚积薄发)可以使得网络更深,甚至超过1200层,仍然可以在CIFAR-10上产生有意义的测试误差改善(4.91%)在cifar-10, cifar-100, SVHN 上超过了 ResNet论文测试结果ResNet的普通版和Stochastic_Depth版的比较,可见精度和速度都提高了。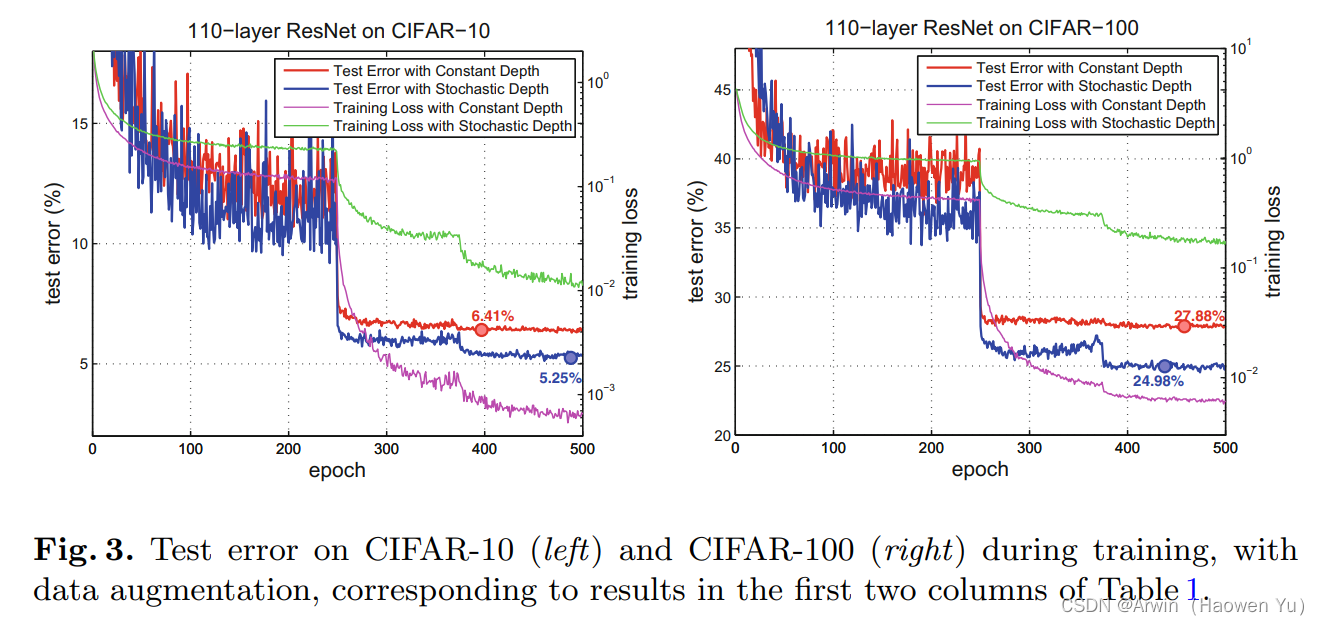 三、代码实现这里给出Drop path方法的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub: 完整代码链接
三、代码实现这里给出Drop path方法的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub: 完整代码链接【本文地址】