| LDA, Linear Discriminant Analysis(线性判别分析) | 您所在的位置:网站首页 › dorm的全称是什么 › LDA, Linear Discriminant Analysis(线性判别分析) |
LDA, Linear Discriminant Analysis(线性判别分析)
|
上一篇博客简要介绍了基于特征值分解和SVD分解矩阵的PCA方法,本篇博客介绍LDA,并将二者进行比较总结,主要是在文后几篇博客链接基础上总结的阅读笔记。 一、LDA和PCALDA的全称是Linear Discriminant Analysis(线性判别分析)
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,不同类别之间的距离越远越好,同一类别之中的距离越近越好。如下图(来自周志华老师《机器学习》)所示,分类目标是最大化类间距离以及最小化类内距离。 LDA降维流程: (1)计算每个类别的均值 μ i \mu_i μi,全局样本均值 μ \mu μ (2)计算类内散度矩阵 S w S_w Sw,全局散度矩阵 S t S_t St,类间散度矩阵 S b S_b Sb (3)对矩阵 S w − 1 S b S_w^{-1}S_b Sw−1Sb做特征值分解 (4)取最大的d个特征值所对应的特征向量 (5)计算投影矩阵 三、总结PCA和LDA的区别
举个简单的例子,在语音识别领域,如果单纯用PCA降维,则可能功能仅仅是过滤掉了噪声,还是无法很好的区别人声,但如果有标签识别,用LDA进行降维,则降维后的数据会使得每个人的声音都具有可分性,同样的原理也适用于脸部特征识别。 LDA充分利用了数据的分类信息,使数据在低维度上就可以区分,减少了运算量,在多个领域都得到了广泛的应用,但仍然存在一些缺点: (1)当样本数量远小于样本的特征维数,样本与样本之间的距离变大使得距离度量失效,使LDA算法中的类内、类间离散度矩阵奇异,不能得到最优的投影方向,在人脸识别领域中表现得尤为突出; (2)LDA不适合对非高斯分布的样本进行降维; (3)LDA在样本分类信息依赖方差而不是均值时,效果不好; (4)LDA可能过度拟合数据。 所以,可以归纳总结为有标签就尽可能的利用标签的数据(LDA),而对于纯粹的非监督任务,则还是得用PCA进行数据降维。 通俗易懂的LDA降维原理 降维算法二:LDA(Linear Discriminant Analysis) 机器学习基础(2)- PCA与LDA比较 数据预处理之降维-PCA和LDA |
 PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。样本的方差越大表示样本的多样性越好。x轴和y轴都不是最理想的投影,故上图中PCA会将数据投影在红色的轴上。
PCA是将数据投影到方差最大的几个相互正交的方向上,以期待保留最多的样本信息。样本的方差越大表示样本的多样性越好。x轴和y轴都不是最理想的投影,故上图中PCA会将数据投影在红色的轴上。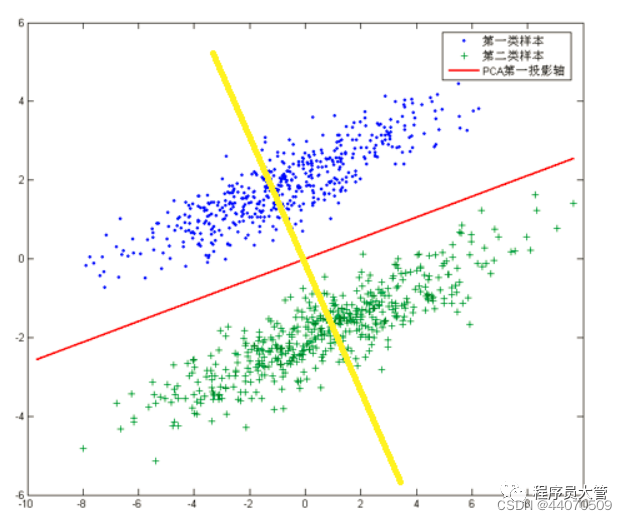 若根据PCA进行降维,将会把数据映射到红色直线上,这样做投影确实方差最大,但是这样做投影之后两类数据样本将混合在一起,将不再线性可分,甚至是不可分的。上面的这个数据集如果使用LDA降维,找出的投影方向就是黄色直线所在的方向,这样的方法在降维之后,可以很大程度上保证了数据的线性可分的。
若根据PCA进行降维,将会把数据映射到红色直线上,这样做投影确实方差最大,但是这样做投影之后两类数据样本将混合在一起,将不再线性可分,甚至是不可分的。上面的这个数据集如果使用LDA降维,找出的投影方向就是黄色直线所在的方向,这样的方法在降维之后,可以很大程度上保证了数据的线性可分的。 w
w
w为投影方向的向量,损失函数为:
J
(
w
)
=
w
T
S
B
w
w
T
S
w
w
J(w)=\frac{w^TS_Bw}{w^TS_ww}
J(w)=wTSwwwTSBw 分母代表每一个类别内的方差之和,分母小,则每个类内部数据点比较聚集; 分子表示两个类别各自数据点到中心点的距离的平方,分子大,则两个类别的距离较远。 希望分母越小越好,分子越大越好,所以需要找出一个w使 J(w) 的值最大,这样就找到最优的w了。 求解过程就是针对
J
(
w
)
J(w)
J(w),对
w
w
w求偏导,并令其为零,最终得到:
S
B
w
=
(
w
T
S
w
w
)
(
w
T
S
B
w
)
S
w
w
S_Bw=\frac{(w^TS_ww)}{(w^TS_Bw)}S_ww
SBw=(wTSBw)(wTSww)Sww
S
w
−
1
S
B
w
=
(
w
T
S
w
w
)
(
w
T
S
B
w
)
w
S_w^{-1}S_Bw=\frac{(w^TS_ww)}{(w^TS_Bw)}w
Sw−1SBw=(wTSBw)(wTSww)w
S
w
−
1
S
B
w
=
λ
w
S_w^{-1}S_Bw=\lambda w
Sw−1SBw=λw 因此目标函数就变成了求矩阵的特征值,而投影的方向就是这个特征值对应的特征向量
w
w
w。
w
w
w为投影方向的向量,损失函数为:
J
(
w
)
=
w
T
S
B
w
w
T
S
w
w
J(w)=\frac{w^TS_Bw}{w^TS_ww}
J(w)=wTSwwwTSBw 分母代表每一个类别内的方差之和,分母小,则每个类内部数据点比较聚集; 分子表示两个类别各自数据点到中心点的距离的平方,分子大,则两个类别的距离较远。 希望分母越小越好,分子越大越好,所以需要找出一个w使 J(w) 的值最大,这样就找到最优的w了。 求解过程就是针对
J
(
w
)
J(w)
J(w),对
w
w
w求偏导,并令其为零,最终得到:
S
B
w
=
(
w
T
S
w
w
)
(
w
T
S
B
w
)
S
w
w
S_Bw=\frac{(w^TS_ww)}{(w^TS_Bw)}S_ww
SBw=(wTSBw)(wTSww)Sww
S
w
−
1
S
B
w
=
(
w
T
S
w
w
)
(
w
T
S
B
w
)
w
S_w^{-1}S_Bw=\frac{(w^TS_ww)}{(w^TS_Bw)}w
Sw−1SBw=(wTSBw)(wTSww)w
S
w
−
1
S
B
w
=
λ
w
S_w^{-1}S_Bw=\lambda w
Sw−1SBw=λw 因此目标函数就变成了求矩阵的特征值,而投影的方向就是这个特征值对应的特征向量
w
w
w。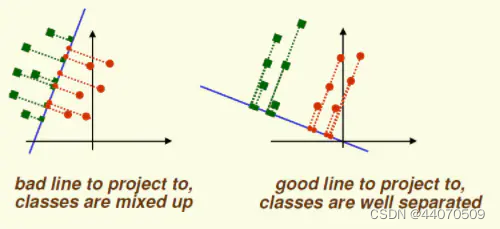
【本文地址】