| 如何使用Docker部署Ceph分布式文件系统 | 您所在的位置:网站首页 › docker部署应用 › 如何使用Docker部署Ceph分布式文件系统 |
如何使用Docker部署Ceph分布式文件系统
|
Docker作为持久化集成的最佳工具,特别是在部署中有着得天独厚的优势。Ceph作为开源的分布式存储得到越来越多的使用,但是作为分布式系统,Ceph在部署和运维上仍然有不小的难度,本文重点介绍利用Docker快速的进行Ceph集群的创建,以及各个组件的安装。 部署环境 至少需要三台虚拟机或者物理机,每台虚拟机或者物理机至少有两块硬盘,这里我是在一台物理机上用vagrant模拟出三台CentOS 6.6虚拟机进行的实验 获取ceph/daemon镜像 三台虚拟机需要安装docker,本文附带Docker加速方案 部署流程
主机名和集群的对应关系如下: node1 -> 192.168.33.11 node2 -> 192.168.33.12 node3 -> 192.168.33.13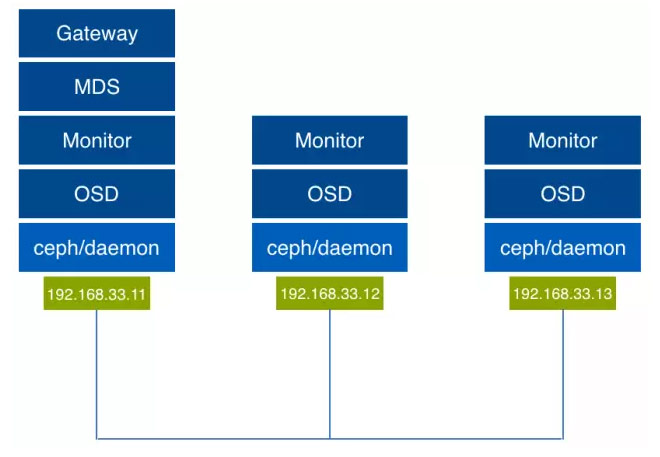
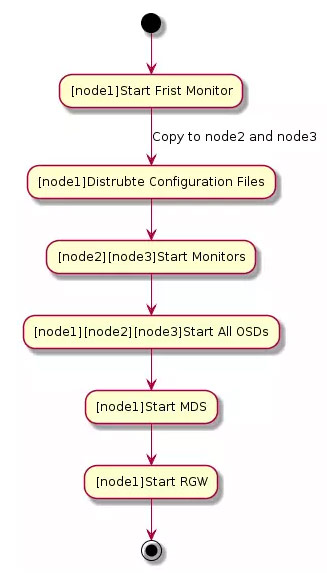
国内安装Dcoker还是速度很慢的,这里推荐使用daocloud的加速方案。不但docker安装速度提高了,pull镜像的速度也大幅度提高。 curl -sSL https://get.daocloud.io/docker | sh我是在CentOS系统上进行的测试,将docker加入自动启动,并启动docker,接下来pull ceph daemon镜像,该镜像包含了所有的ceph服务和entrypoint。 chkconfig docker service docker start docker pull ceph/daemon 启动第一个Monitor在node1上启动第一个Monitor,注意,如果你的环境中IP和我不同,请修改MON_IP。 sudo docker run -d \ --net=host \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ -e MON_IP=192.168.33.11 \ -e CEPH_PUBLIC_NETWORK=192.168.33.0/24 \ ceph/daemon mon验证一下效果: docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7babea544ef1 ceph/daemon "/entrypoint.sh mon" 3 seconds ago Up 2 seconds backstabbing_brattain查看一下集群状态: docker exec 7babea544ef1 ceph -s当前集群状态,能看到当前已经有一个mon启动起来了。 cluster 0de1fc5a-084d-4396-bb0b-59db72a9a439 health HEALTH_ERR 64 pgs stuck inactive 64 pgs stuck unclean no osds monmap e1: 1 mons at {node1.docker.com=192.168.33.11:6789/0} election epoch 2, quorum 0 node1.docker.com osdmap e1: 0 osds: 0 up, 0 in flags sortbitwise pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects 0 kB used, 0 kB / 0 kB avail 64 creating 复制配置文件接下来需要将node1的配置文件复制到node2和node3上,复制的路径包含/etc/ceph和/var/lib/ceph/bootstrap-*下的所有内容。这些配置文件非常重要,如果没有这些配置文件的存在,我们在其他节点启动新的docker ceph daemon的时候会被认为是一个新的集群。 我们在node1执行以下命令: ssh root@node2 mkdir -p /var/lib/ceph scp -r /etc/ceph root@node2:/etc scp -r /var/lib/ceph/bootstrap* root@node2:/var/lib/ceph ssh root@node3 mkdir -p /var/lib/ceph scp -r /etc/ceph root@node3:/etc scp -r /var/lib/ceph/bootstrap* root@node3:/var/lib/ceph 启动第二个和第三个Monitor在node2上执行: sudo docker run -d \ --net=host \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ -e MON_IP=192.168.33.12 \ -e CEPH_PUBLIC_NETWORK=192.168.33.0/24 \ ceph/daemon mon在node3上执行: sudo docker run -d \ --net=host \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ -e MON_IP=192.168.33.13 \ -e CEPH_PUBLIC_NETWORK=192.168.33.0/24 \ ceph/daemon mon在node1上查看集群状态: cluster 0de1fc5a-084d-4396-bb0b-59db72a9a439 health HEALTH_ERR 64 pgs stuck inactive 64 pgs stuck unclean no osds monmap e3: 3 mons at {node1.docker.com=192.168.33.11:6789/0,node2.docker.com=192.168.33.12:6789/0,node3.docker.com=192.168.33.13:6789/0} election epoch 6, quorum 0,1,2 node1.docker.com,node2.docker.com,node3.docker.com osdmap e1: 0 osds: 0 up, 0 in flags sortbitwise pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects 0 kB used, 0 kB / 0 kB avail 64 creating 启动OSD的遇到的问题按照原视频的介绍的方法,启动OSD可以直接指定某个分区,然后用osd_ceph_disk作为启动ceph/daemon的参数,之后docker镜像会自动的进行分区等动作。但是经过实际验证却发现在mkjournal创建错误,OSD无法启动。 经过和社区确认,发现这个Bug在之前版本中得到过修复,但是之后的版本又出现了。根据社区的建议使用jewel版本的ceph daemon进行了再次验证,发现问题依旧,所以这里介绍的方法只能退而求其次,采用手动方式分区、格式化,之后用osd_directory启动ceph/daemon。 这是用osd_ceph_disk方式启动后的错误日志: command_check_call: Running command: /usr/bin/ceph-osd --cluster ceph --mkfs --mkkey -i 4 --monmap /var/lib/ceph/tmp/mnt.BT8FXG/activate.monmap --osd-data /var/lib/ceph/tmp/mnt.BT8FXG --osd-journal /var/lib/ceph/tmp/mnt.BT8FXG/journal --osd-uuid 89e240e1-17e9-4d6c-8d4f-f1a3e0278b91 --keyring /var/lib/ceph/tmp/mnt.BT8FXG/keyring --setuser ceph --setgroup disk 2016-06-12 23:37:26.180610 7f8889654800 -1 filestore(/var/lib/ceph/tmp/mnt.BT8FXG) mkjournal error creating journal on /var/lib/ceph/tmp/mnt.BT8FXG/journal: (2) No such file or directory 2016-06-12 23:37:26.180752 7f8889654800 -1 OSD::mkfs: ObjectStore::mkfs failed with error -2 2016-06-12 23:37:26.180918 7f8889654800 -1 ** ERROR: error creating empty object store in /var/lib/ceph/tmp/mnt.BT8FXG: (2) No such file or directory mount_activate: Failed to activate unmount: Unmounting /var/lib/ceph/tmp/mnt.BT8FXG command_check_call: Running command: /bin/umount -- /var/lib/ceph/tmp/mnt.BT8FXG 启动OSD第一步先进行分区和格式化,这里只给出node1的操作方式,其他两个节点的方式类似。 先来安装必要的工具: yum install -y parted xfsprogs [root@node1 vagrant]# parted /dev/sdb GNU Parted 2.1 Using /dev/sdb (parted) mklabel New disk label type? gpt (parted) p Model: ATA VBOX HARDDISK (scsi) Disk /dev/sdb: 107GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags (parted) mkpart Partition name? []? "Linux filesystem" File system type? [ext2]? xfs Start? 0G End? 107GB (parted) p Model: ATA VBOX HARDDISK (scsi) Disk /dev/sdb: 107GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 1049kB 107GB 107GB Linux filesystem (parted) quit格式化: [root@node1 vagrant]# mkfs.xfs /dev/sdb1 meta-data=/dev/sdb1 isize=256 agcount=4, agsize=6553472 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=26213888, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=12799, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0我们把目录在node1上进行挂载。 mkdir -p /ceph/sdb mount /dev/sdb1 /ceph/sdb最后启动OSD,这里最重要的就是把我们刚刚挂载好的OSD的实际路径透传给Docker内部的/var/lib/ceph/osd,如果每个节点有多个OSD的情况下,只需要在Host上映射到不同的目录,启动Docker的时候变更和/var/lib/ceph/osd的映射关系即可。 sudo docker run -d \ --net=host \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ -v /dev/:/dev/ \ -v /ceph/sdb:/var/lib/ceph/osd \ --privileged=true \ ceph/daemon osd_directory按照同样的方法,将node2和node3的OSD也加入到集群,最终的效果如下: cluster 0de1fc5a-084d-4396-bb0b-59db72a9a439 health HEALTH_WARN clock skew detected on mon.node2.docker.com 64 pgs degraded 64 pgs stuck unclean 64 pgs undersized Monitor clock skew detected monmap e3: 3 mons at {node1.docker.com=192.168.33.11:6789/0,node2.docker.com=192.168.33.12:6789/0,node3.docker.com=192.168.33.13:6789/0} election epoch 6, quorum 0,1,2 node1.docker.com,node2.docker.com,node3.docker.com osdmap e13: 3 osds: 3 up, 3 in flags sortbitwise pgmap v18: 64 pgs, 1 pools, 0 bytes data, 0 objects 4551 MB used, 11306 MB / 16720 MB avail 64 active+undersized+degraded 创建MDS创建好基本的环境,其他的就容易了很多,下面来启动MDS。 sudo docker run -d \ --net=host \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ -e CEPHFS_CREATE=1 \ ceph/daemon mds 启动RGW,并且映射80端口 sudo docker run -d \ -p 80:80 \ -v /etc/ceph:/etc/ceph \ -v /var/lib/ceph/:/var/lib/ceph/ \ ceph/daemon rgw 最终的集群状态 cluster 0de1fc5a-084d-4396-bb0b-59db72a9a439 health HEALTH_WARN clock skew detected on mon.node2.docker.com 48 pgs stuck inactive 48 pgs stuck unclean Monitor clock skew detected monmap e3: 3 mons at {node1.docker.com=192.168.33.11:6789/0,node2.docker.com=192.168.33.12:6789/0,node3.docker.com=192.168.33.13:6789/0} election epoch 6, quorum 0,1,2 node1.docker.com,node2.docker.com,node3.docker.com mdsmap e5: 1/1/1 up {0=mds-node1.docker.com=up:active} osdmap e25: 3 osds: 3 up, 3 in flags sortbitwise pgmap v38: 128 pgs, 9 pools, 588 bytes data, 11 objects 6791 MB used, 16996 MB / 25081 MB avail 80 active+clean 45 creating 3 creating+activating 总结在Docker中部署Ceph并没有想象中的那么顺利,社区的版本中仍然有Bug需要解决。 Docker作为一种快捷的部署方式,的确可以大幅度提高Ceph的部署效率,提高扩展的速度。但是从另一个角度我们应该注意到,随着Docker的引入也改变了Ceph的运维方式,比如在OSD增减的时候,需要到容器中对Ceph集群进行维护。再比如配置文件变更后的重启问题等。 Ceph中国社区 Ceph中国社区是由中国开源云联盟WG8工作组领导的开源社区组织,2016年4月份得到Ceph社区官方的正式授权,社区秉承公正、公开、公平的理念,为广大Ceph爱好者提供交流平台。 官方网站:www.ceph.org.cn |
【本文地址】