| Zipkin服务端搭建使用教程 | 您所在的位置:网站首页 › docker安装zipkin › Zipkin服务端搭建使用教程 |
Zipkin服务端搭建使用教程
|
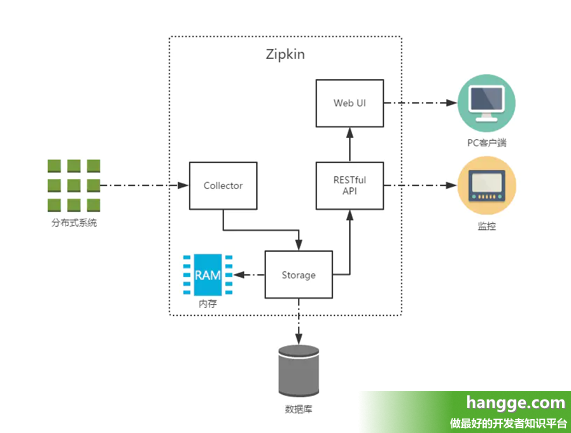
Zipkin服务端搭建使用教程1(分别使用jar包、镜像方式启动Zipkin Server)Zipkin 服务搭建有多种方式:使用官方提供了可直接启动的 Jar 包,通过 Docker 镜像运行,或者自己手动添加依赖创建 Zipkin 服务器应用。 不过到了 spring-boot 2.0 后官方就不推荐自己通过手动添加依赖创建 Zipkin 服务器应用了。所以本文主要介绍前面两种方式...... 扩展阅读:(SkyWalking支持go语言) 还在使用zkpin进行链路追踪?SkyWalking这款国产中间件也很香_程序员落雪的博客-CSDN博客_skywalking属于中间件吗SkyWalking学习和实战1.SkyWalking概述1.1 SkyWaling是什么?对于一个大型的几十个、几百个微服务构成的微服务架构系统,通常会遇到下面一些问题,比如:如何串联整个调用链路,快速定位问题?如何理清各个微服务之间的依赖关系?如何进行各个微服务接口的性能分折?如何跟踪整个业务流程的调用处理顺序?skywalking是一个国产开源框架,2015年由吴晟开源 , 2017年加入Apache孵化器。skywalking是分布式系统的应用程序性能监视工具, Zipkin 服务搭建有多种方式:使用官方提供了可直接启动的 Jar 包,通过 Docker 镜像运行,或者自己手动添加依赖创建 Zipkin 服务器应用。 不过到了 spring-boot 2.0 后官方就不推荐自己通过手动添加依赖创建 Zipkin 服务器应用了。所以本文主要介绍前面两种方式。 一、基本介绍 1,什么是 Zipkin?(1)Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现。可以用来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高的问题,找出系统性能瓶颈的根源。 (2)除了面向开发的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观地搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。 2,Zipkin 基础架构下图展示了 Zipkin 的基础架构,它主要由 4 个核心组件构成: Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。Web UI:UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息。
TIPS 如下命令可下载最新版本。 curl -sSL https://zipkin.io/quickstart.sh | bash -s下载下来的文件名为 zipin.jar 方式2:到Maven中央仓库下载TIPS 如下地址令可下载最新版本。 访问如下地址即可: https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec下载下来的文件名为 zipkin-server-2.12.9-exec.jar 方式3:使用百度盘地址下载提供2.12.9版本。 链接:https://pan.baidu.com/s/1HXjzNDpzin6fXGrZPyQeWQ 密码:aon2 启动Zipkin Server使用如下命令,即可启动Zipkin Server java -jar 你的jar包 访问http://localhost:9411 即可看到Zipkin Server的首页。
Zipkin Server下载与搭建 | 周立的博客 - 关注Spring Cloud、DockerTIPS本文基于Zipkin Server 2.12.9编写,理论支持Zipkin 2.0及更高版本。Zipkin Server的API兼容性(微服务通过集成reporter模块,从而Zipkin Server通信)非常好,对于Spring Cloud Greenwich,Zipkin... (1)下载后执行如下命令启动服务,默认端口为 9411 1 java -jar zipkin-server-2.19.3-exec.jar (2)或者我们也可以执行如下命令将 Zipkin 服务作为守护进程后台运行: 1 nohup java -jar zipkin-server-2.19.3-exec.jar & (3)启动后通过浏览器访问 http://IP:9411,则可以看到如下图所示的 Zipkin 管理页面:
(1)如果需要改用其他端口(比如 8888),则可以执行如下命令启动服务: 1 java -jar zipkin-server-2.19.3-exec.jar --server.port=8888 (2)如果想让 Zipkin 服务端能够从消息中间件(比如 RabbitMQ)获取跟踪信息,可以执行如下命令启动服务: 1 java -jar zipkin-server-2.19.3-exec.jar --zipkin.collector.rabbitmq.addresses=192.168.60.133:5672 --zipkin.collector.rabbitmq.username=hangge --zipkin.collector.rabbitmq.password=123 (3)启动后查看 RabbitMq Web 控制台的 Queues 选项,可以看到创建了一个名为 zipkin 的队列,也是 Zipkin 默认的监听队列: 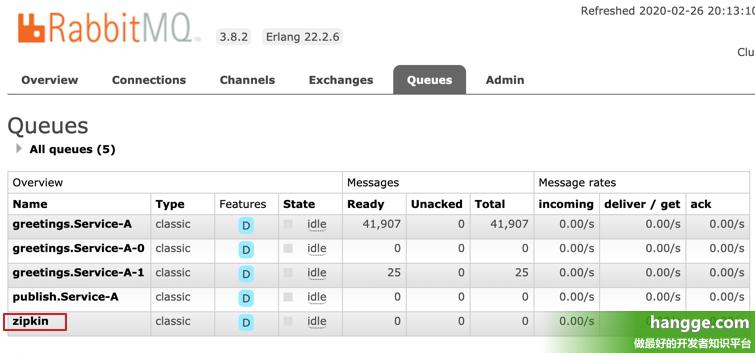 三、通过 Docker 镜像运行
1,下载镜像
三、通过 Docker 镜像运行
1,下载镜像
执行如下命令拉取镜像到本地: 1 docker pull openzipkin/zipkin 2,运行容器(1)镜像下载后执行如下命令运行,服务端口为 9411 1 docker run --name zipkin -d -p 9411:9411 openzipkin/zipkin (2)如果想让 Zipkin 服务端能够从消息中间件(比如 RabbitMQ)获取跟踪信息,可以执行如下命令运行容器: 1 docker run --name zipkin -d -p 9411:9411 -e RABBIT_ADDRESSES=192.168.60.133:5672 -e RABBIT_USER=hangge -e RABBIT_PASSWORD=123 openzipkin/zipkin (3)如果每次都要使用 docker 命令来分别启动 zipkin 容器还是略显繁琐,我们也可以通过 Docker Compose 进行启动,docker-compose.yml 文件内容如下: version: '2' services: zipkin: image: openzipkin/zipkin container_name: zipkin environment: - RABBIT_ADDRESSES=192.168.60.133:5672 - RABBIT_USER=hangge - RABBIT_PASSWORD=123 ports: - 9411:9411默认情况下,Zipkin Server 都会将跟踪信息存储在内存中,每次重启 Zipkin Server 都会使得之前收集的跟踪信息丢失,而且当有大量跟踪信息时我们的内存存储也会成为瓶颈。 所有正常情况下我们都需要将跟踪信息对接到外部存储组件(比如 MySQL、Elasticsearch)中去。本文首先介绍如何使用 MySQL 实现 Zipkin 的数据持久化。 二、使用 MySQL 存储数据 1,数据库初始化(1)首先在 MySQL 中创建一个名为 zipkin 的数据库,编码使用 utf8。 
(2)接着从官方的 GitHub 仓库中下载初始化 sql 语句,然后执行创建表结构(一共三张表)。下载地址如下: zipkin/mysql.sql at master · openzipkin/zipkin · GitHub
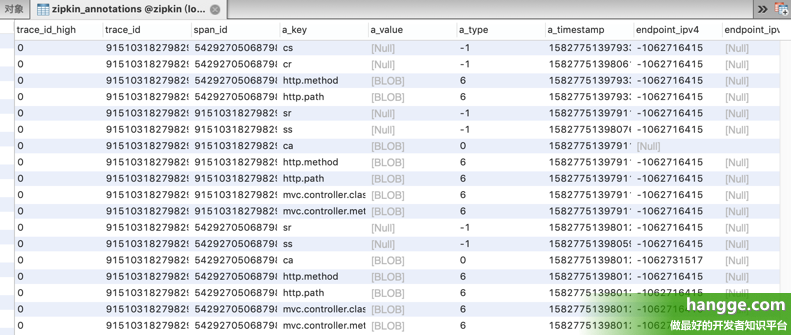
(1)Zipkin 启动时只需要指定好 MySql 连接信息即可。如果是通过 jar 包运行,则执行如下命令: 1 java -jar zipkin-server-2.19.3-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=192.168.60.1 --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=hangge1234 --MYSQL_DB=zipkin (2)如果通过 Docker 镜像运行,则执行如下命令: 1 docker run --name zipkin -d -p 9411:9411 -e STORAGE_TYPE=mysql -e MYSQL_HOST=192.168.60.1 -e MYSQL_TCP_PORT=3306 -e MYSQL_USER=root -e MYSQL_PASS=hangge1234 -e MYSQL_DB=zipkin openzipkin/zipkin (3)如果每次都要使用 docker 命令来分别启动 zipkin 容器还是略显繁琐,我们也可以通过 Docker Compose 进行启动,docker-compose.yml 文件内容如下: version: '2' services: zipkin: image: openzipkin/zipkin container_name: zipkin environment: - STORAGE_TYPE=mysql - MYSQL_HOST=192.168.60.1 - MYSQL_TCP_PORT=3306 - MYSQL_USER=root - MYSQL_PASS=hangge1234 - MYSQL_DB=zipkin #- RABBIT_ADDRESSES=192.168.60.133:5672 #- RABBIT_USER=hangge #- RABBIT_PASSWORD=123 ports: - 9411:9411 3,运行测试通过上面的设置之后,我们完成了将 Zipkin Server 从内存存储跟踪信息切换为 MySQL 存储信息的改造。后续所有的跟踪信息都会存放在 MySQL 相应的表中。 zipkin_spans 表存放类似如下数据信息:
默认情况下,Zipkin Server 都会将跟踪信息存储在内存中,每次重启 Zipkin Server 都会使之前收集的跟踪信息丢失,并且当有大量跟踪信息时我们的内存存储也会成为瓶颈。 在前文中我演示了如何将跟踪信息对接到 MySQL 中去(点击查看)。本文接着演示如何使用 Elasticsearch 实现 Zipkin 的数据持久化。 三、使用 Elasticsearch 存储数据 1,准备 Elasticsearch 环境首先我们需要启动一个 Elasticsearch 服务,具体步骤可以参考我之前写的文章: 数据搜索分析引擎Elasticsearch安装教程(CentOS下单节点部署)Docker - 通过容器部署Elasticsearch环境教程 2,启动 Zipkin 服务(1)Zipkin 启动时只需要指定好 Elasticsearch 连接信息即可。如果是通过 jar 包运行,则执行如下命令: 1 java -jar zipkin-server-2.19.3-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=192.168.60.133:9200 (2)如果通过 Docker 镜像运行,则执行如下命令: 1 docker run --name zipkin -d -p 9411:9411 -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=192.168.60.133:9200 openzipkin/zipkin (3)如果每次都要使用 docker 命令来分别启动 zipkin 容器还是略显繁琐,我们也可以通过 Docker Compose 进行启动,docker-compose.yml 文件内容如下: version: '2' services: zipkin: image: openzipkin/zipkin container_name: zipkin environment: - STORAGE_TYPE=elasticsearch - ES_HOSTS=192.168.60.133:9200 #- RABBIT_ADDRESSES=192.168.60.133:5672 #- RABBIT_USER=hangge #- RABBIT_PASSWORD=123 ports: - 9411:9411 3,运行测试(1)通过上面的设置之后,我们完成了将 Zipkin Server 从内存存储跟踪信息切换为 Elasticsearch 存储信息的改造。后续所有的跟踪信息都会存放到 Elasticsearch 中。 (2)我们使用谷歌浏览器插件 ElasticSearch Head 查看当前 Elasticsearch 集群的信息。可以发现 Zipkin 跟踪数据已经成功保存进来了。 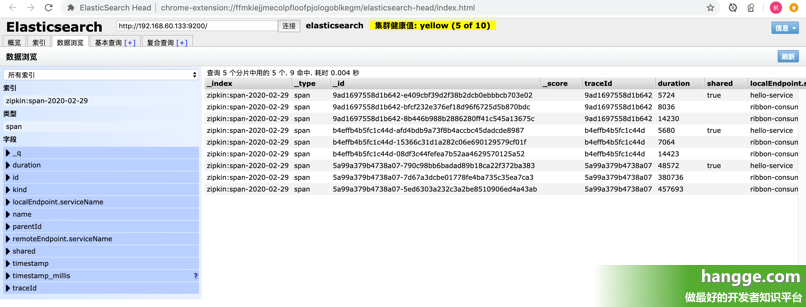
Zipkin 不仅提供了 UI 模块让用户可以使用 Web 页面来方便地查看跟踪信息,它还提供了丰富的 RESTful API 接口方便用户在第三方系统中调用来定制自己的跟踪信息展示或监控(实际上 Zipkin 的 UI 模块也是基于 RESTful API 接口来实现的)。 四、API 接口介绍与使用(1)Zipkin Server 提供的 API 接口都是以 /api/v2 路径作为前缀,详细的接口请求参数和请求返回格式可以访问 Zipkin 官网的 API 页面(点击访问)来查看:
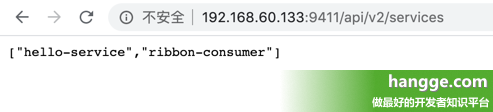
(2)常用接口说明如下: 接口路径请求方式接口描述/dependenciesGET用来获取通过收集到的 Span 分析出的依赖关系/servicesGET用来获取服务列表/spansGET根据服务名来获取所有的 Span 名/spansPOST向 Zipkin Server 上传 Span/dependenciesGET根据 Trace ID 获取指定跟踪信息的 Span 列表/dependenciesGET根据指定条件查询并返回符合条件的 trace 清单
|
 http://www.itmuch.com/spring-cloud/zipkin-server-install/
http://www.itmuch.com/spring-cloud/zipkin-server-install/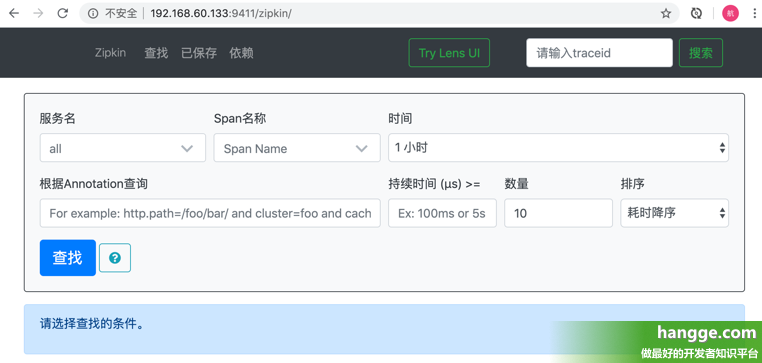


【本文地址】